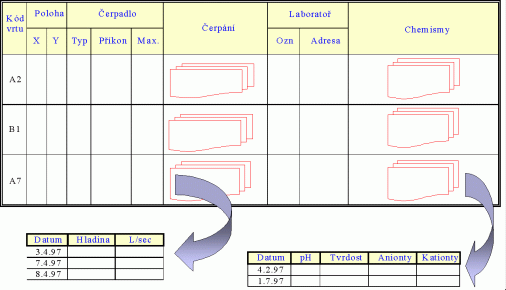
Obrázek 1: Segmentovaný soubor
Organizace dat, báze dat
Doc. Dr. Vladimír Homola, Ph.D.
Organizace dat je jisté uspořádání dat, které má za účel umožnit efektivní zpracování data potřebných pro aplikace. Zahrnuje postupy a metody, jak data na médiích ukládat a jak je hledat. Tyto postupy a metody jsou soustředěny v programech, které požadované akce provádí. Programy mají tři úrovně:
Základní systémová úroveň, kterou realizují komponenty operačního systému pro všechny uživatelské programy jednotně. Záznam a hledání dat podléhá fyzickým charakteristikám jednotlivých médií a proto se tato úroveň nazývá fyzická úroveň (dat, záznamu, organizace apod).
Úroveň báze dat. Jde o maximálně obecné, avšak většinou na jediný typ databázové struktury zaměřené programové systémy. Poskytují především možnost definice struktury záznamu (z jakých polí se záznam skládá, označení, zda jde o pole klíčové nebo hodnotové ap), aktualizace dat (co do množství, kvality i struktury), a získávání informací na základě zadaných specifikací. Základní funkcí bází dat je záznam a čtení takto nadefinovaných struktur na fyzické úrovni (tj. komunikace s programy systémové úrovně). Dále poskytují možnost provádění vazeb mezi jednotlivými soubory a výběr dílčích datových polí z takto provázaných souborů. Tato úroveň se nazývá logická úroveň.
Uživatelská úroveň. Báze dat jsou zcela postačující systémy pro veškeré požadavky uživatelů na zpracování dat. Pro svou obecnost však kladou na běžné uživatele značné nároky na zvládnutí formalizovaného způsobu jejich ovládání. Proto báze dat poskytují prostředky, jak vytvořit rozhraní mezi obecnou bází dat a specializovanou potřebou toho kterého uživatele. Těmito prostředky jsou většinou programovací jazyky různých syntaxí, ale vždy se zajištěnou možností použít kteroukoliv z funkcí báze dat. Databázoví specialisté ve spolupráci s odborníky různých oblastí pak pomocí daného programovacího jazyka vytváří uživatelské, účelově orientované programy, které sice neposkytují možnost kdykoliv použít jakoukoliv funkci báze dat, ale zato uživatel pracuje v prostředí své odbornosti, ve kterém se dobře orientuje především terminologicky.
Tato práce je zaměřena na úroveň báze dat a případné vztahy k úrovni systémové tak, aby byly jasně vidět aspekty zvláště bází nejrůznějších geo-dat v moderních systémech. K vytváření bází dat vedly potřeby nesmírně dynamického rozvoje nových technologií umožňujících koncentraci a zpracování dat kvantity a kvality dříve nevídané (viz např. už jen družicové informace z nejrůznějších oblastí: geografie, geofyzika, strukturní geologie, environmentální inženýrství ap).
Klasické metody zpracování dat většinou nelze na data takového rozsahu a provázanosti aplikovat. Především mají principielní nevýhody a s růstem množství dat jsou stále méně efektivní. Jsou založeny na následujících principech:
Data jsou uložena v souborech. Soubor se skládá ze záznamů.
Záznam se skládá z jednotlivých datových polí. Často má jedno nebo více polí identifikační význam a tvoří pak klíč záznamu. V takovém případě bývají soubory uspořádány ve vzrůstající posloupnosti hodnot klíčů a při každé změně klíčového pole a přidání nebo vypuštění záznamu je nutno soubor fyzicky přeorganizovat.
Organizace souborů (jejich struktura) je dána potřebou konkrétních programů, které je používají. Programátor takových programů nejprve zjistí, jaká data jsou k disposici, jaká data na jejich základě je nutno odvodit, a podle toho navrhne strukturu souborů, která je z jeho subjektivního hlediska optimální.
V každém takto vytvořeném programu je tedy přesně udáno, které soubory se mají pro zpracování použít, jaká je jejich přesná interní struktura, a jaké informace z nich mají tvořit požadované výsledné informace. Takový klasický způsob zpracování dat má mnoho nevýhod; mezi nejvýraznější patří:
Během jednotlivých kroků při zpracování dat vzniká množství různých souborů. Je obtížné udržet přehled o jejich jménech, obsahu, formě, době platnosti ap. všech existujících souborů.
Velké množství souborů vede k tzv. redundanci dat: tatáž data jsou uložena na několika různých místech. Při aktualizaci takového údaje je nutno provést aktualizaci na všech místech jeho výskytu, což je náročné jednak časově a jednak organizačně.
Velké obtíže nastávají při potřebě použít soubory se strukturou definovanou na míru dané aplikaci v jiných programech, které vyžadují strukturu jinou. Programy pro přeorganizování dat (zvláště pro změnu logické struktury) se svou složitostí mohou blížit samotným zpracovávajícím aplikacím.
Jestliže je pro nějaký soubor opodstatněné vést dva nebo více nezávislých klíčů, je zapotřebí při přechodu od zpracování podle jednoho ke zpracování podle druhého provést jeho fyzické přeorganizování.
Právě při fyzickém přeorganizovávání objemných souborů může vznikat několik dočasných souborů, které zahltí kapacitu médií.
Koncepce bází dat se snaží tyto nevýhody odstraňovat. Používají přitom následující metody:
Sdružují a provazují data souborů.
Oddělují popis struktury dat od dat samotných a od zpracovávajících programů.
Přistupují k jednotlivým údajům zvláštní programovou vrstvou, nikoliv přímo jednotlivými uživatelskými programy.
Poskytují možnost vyhodnotit uložená data jakýmkoliv způsobem. K uloženým datům umožňují současný přístup více uživatelů s jejich plnou vzájemnou ochrannou.
ad 1): Sdružování a provazování dat souborů znamená odstranění redundantních dat. Umožňuje spojování logicky navazujících souborů, ve kterých místo násobného přímého výskytu nějaké datové hodnoty udržuje ukazovátka (pointery) na jedinečné místo uložení této hodnoty.
ad 2): Oddělení popisu struktury od vlastních dat znamená, že kromě vlastních uložených dat jsou ukládány také informace o místě a způsobu jejich uložení. Tento popis může být fyzicky přítomen ve stejném souboru jako data, nebo v souboru samostatném. Jestliže se zpracovávající programy opírají o tyto popisy struktury, není zapotřebí programy měnit při reorganizaci vlastních dat.
ad 3): K vlastním datům nepřistupují aplikace přímo, ale žádají o jejich dodání obecně přístupné programové komponenty systému řízení báze dat. Provádí to většinou voláním podprogramů s parametry, kterými jsou popisy požadovaných dat získané z (od dat odděleného) popisu struktury.
ad 4): Zvláště v síťovém prostředí a při práci s citlivými informacemi je zapotřebí zajistit bezpečnost informací. Báze dat k tomu používají na jedné straně prověřování oprávněnosti přístupu pomocí seznamu uživatelů a jejich přístupových hesel a práv, na druhé straně mechanismus zamykání souborů, záznamů a polí dat.
Pro umožnění shora uvedeného musí být zajištěna
fyzická nezávislost dat: fyzické uložení (např. délka bloku) může být změněno, aniž by bylo nutno přepisovat uživatelské aplikace
logická nezávislost dat: může být přidána položka nebo rozšířena logická struktura, aniž by to mělo vliv na existující aplikace
programová komunikace: musí být k disposici vhodné programové moduly systémů řízení báze dat pro dodávání dat do aplikací
uživatelská komunikace: musí být k disposici vhodný komunikační prostředek pro uživatele - nepočítačové odborníky; tím může být uživatelská aplikace, ale preferuje se obecný dotazovací jazyk nezávislý na použitém systému báze dat.
Z uživatelského hlediska je základní logickou jednotkou pole. Obsahuje hodnotu některého typu elementární informace (viz příslušná kapitola shora), fyzicky proto bývá uloženo na jednom nebo více bytech. Pole je charakterizováno atributy (typ pole, jeho délka, poloha desetinné tečky nebo čárky atd).
Jestliže více polí tvoří logický celek, tvoří tato pole segment. Segment sám nemusí být tvořen pouze poli, ale libovolnou posloupností polí a segmentů, je-li to potřebné nebo vhodné z hlediska logické struktury.
Segmenty, které k sobě logicky patří, tvoří záznam. Záznamy, které k sobě logicky patří, tvoří soubor. Soubory tvoří bázi dat.
Obrázek 1: Segmentovaný soubor
Předchozí obrázek znázorňuje soubor s informacemi o podzemních vodách. Záznam je tvořen informacemi o jednom vrtu. Má šest segmentů: Kód vrtu, Poloha, Čerpadlo, ..., Chemismy. První segment je tvořen jediným polem. Segmenty Čerpání a Chemismy mají charakter násobného, opakujícího se segmentu, tj. mohou být přítomny vícekrát. Je samozřejmé, že - až na řídké výjimky - je počet záznamů v souboru vždy proměnný, stejně jako počet násobných segmentů v záznamu. Omezení shora je dáno především kapacitou média.
Některé typy organizace dat na systémové úrovni kladou další omezení na maximální počet záznamů v souboru (např. v systémech s pevným přidělením místa pro soubor) - musí být definován před vytvořením souboru. Některé systémy báze dat kladou další omezení na počet opakování segmentů - rovněž musí být definováno před vytvořením souboru.
Příklad z předchozího odstavce uvádí pohled na "naplněný" soubor. Z tohoto pohledu je zřejmá nejen logická struktura souboru, ale i jeho obsah (kdyby bylo hodně místa na papíře). Pro potřeby vytváření a zpracování bází dat je však zapotřebí od sebe oddělit popis struktury (typy polí, segmentů ...) a výskyt dat (záznamu, segmentu ...).
Popis struktury stanovuje počet polí, jejich typ a pojmenování, komposici segmentů ap. Popis každého segmentu se tedy vyskytuje jen jednou. Avšak segment, který je popsán ve struktuře, se - zvláště u násobných segmentů - nemusí ve skutečném datovém záznamu vyskytnout ani jednou, nebo naopak se může vyskytnout několikrát, přitom u různých záznamů v různém počtu. To se týká např. segmentu Čerpání: po založení záznamu tento segment asi ještě zápis o čerpání mít nebude; ale čas od času přibude další záznam o čerpání tak, jak to stanoví provozní podmínky.
Je zřejmé, že popis struktury je zapotřebí formalizovat, a to jak na úrovni uživatele (=člověka), tak na úrovni aplikace (=programu). Různé systémy báze dat přijímají popisy struktur v různé syntaxi. Např. v hierarchickém modelu bývá používán popis, obdobný popisu souboru v jazyku Cobol. Zjednodušený příklad zápisu je následující:
01 Vrt.
02 Kód-vrtu pic X(5).
02 Poloha.
03 X pic N(8).
03 Y pic N(8).
02 Čerpadlo.
03 Typ pic X(10).
03 Příkon pic N(4).
03 Maximum pic N(6).
02 Čerpání occurs (=opakuje se).
03 Datum pic D(8).
03 Hladina pic N(8,2).
03 L-Sec pic N(6,1).
...
V předchozím odstavci je podána ukázka logického záznamu. Tak uživatel požaduje, aby se mu záznam jevil. Při klasickém způsobu zpracování (a pohříchu mnohde ještě přetrvávajícímu klasickému myšlení) je od logického k fyzickému záznamu velmi blízko - třebas až na úroveň totožnosti. V bázi dat je ovšem logický záznam budován až na požadavek uživatele.
Takové požadavky mohou být v různých situacích velmi rozmanité a v době vytváření databází ani nemusí být známy. Protože je požadováno jen jedno fyzické uložení jednoho údaje, nemusí být jednotlivá pole logického záznamu dokonce ani v jednom jediném fyzickém souboru: např. shora uvedený logický záznam může být komponován z údajů geologa (vrty a jejich poloha), údajů odběratele (čerpadla a čerpání) a údajů chemika (výsledky chemických analýz).
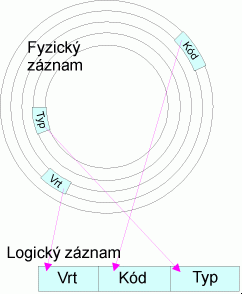
Obrázek 2: Koincidence záznamů
Logické záznamy vytváří na přání uživatele aplikační programy (dotazovací jazyky) výběrem a organizací z fyzického záznamu. Logický záznam tedy může obsahovat
části fyzického záznamu
celý fyzický záznam
více fyzických záznamů nebo jejich částí, přičemž tyto fyzické záznamy mohou a nemusí být součástí jednoho nebo více souborů.
Rozlišuje se tedy struktura organizace dat (vnější, uživatelský popis dat sloužící k vytváření logických záznamů), a struktura uložení dat (vnitřní, systémový popis dat fyzických záznamů).
Organizace dat v bázi dat musí umožňovat právě spolupráci mezi uložením a organizací.
Lineární záznam je takový, jehož pole nejsou vzájemně podřízena. Například záznamy o čerpání vod z vrtů obsahující kód vrtu, datum, hladinu a sekundové množství jsou klasickým příkladem lineárních záznamů. Jednou z jejich charakteristik je např. to, že při návrhu struktury nezáleží na pořadí polí v záznamu.
Nelineární záznam je takový záznam, v němž může existovat vztah nadřazenosti a podřízenosti polím. K nejvýznamnějším a nejpoužívanějším nelineárním strukturám patří shora zmíněná hierarchická struktura. Příklad tamtéž uvedený lze graficky znázornit např. schématem obvyklým v teorii grafů, kde z hlediska této teorie jde o strom.
Obecně lze říci, že u nelineárních záznamů záleží na pořadí polí v záznamu. Konkrétně u hierarchické struktury lze zavést zřejmý pojem úroveň pole jako počet nadřízených polí. Pak při návrhu struktury nezáleží na pořadí polí stejné úrovně podřízené stejnému poli. Všechna ostatní pořadí jsou pak evidentně významná.
Možnost vytvářet nelineární záznamy je důležitou vlastností bází dat. Ukazuje se tak opět význam rozlišení fyzických a logických záznamů.
Rev 10 / 2002