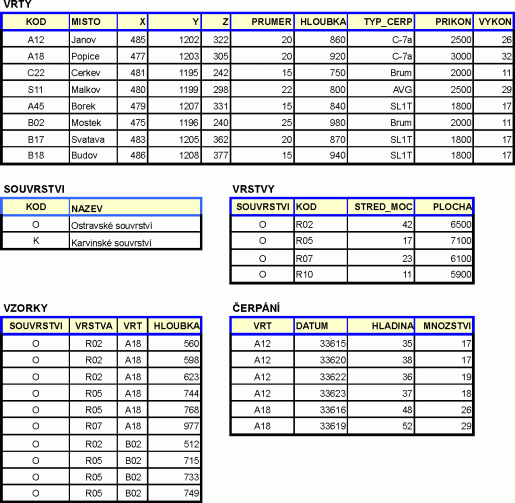
Obrázek 1: Tabulky demonstrační databáze
Dotazovací jazyk SQL
Doc. Dr. Vladimír Homola, Ph.D.
Poznámka: Tento článek byl jedním ze zdrojů pro publikaci [1] stejného autora.
Problematika uložení a zpracování dat je nesmírně rozsáhlá: od fyzického uložení dat po logické struktury, od sekvenčního přístupu po přístup přímý atd. U koncového uživatele - nepočítačového odborníka však není možno očekávat, že se nejprve stane odborníkem přes data. Proto je pochopitelná snaha vytvářet pro tyto uživatele jednak formalizované, jednak pokud možno normalizované nástroje pro zpracování dat v počítačovém prostředí jednotným způsobem s tím, že uživatel není zatěžován otázkami uložení, organizace apod.
Pokusů o vytvoření jednotného alespoň dotazovacího prostředí bylo učiněno několik. Faktem zůstává, že - zvláště při velkých objemech dat - jistý stupeň přehledu uživatele o datové problematice je vyžadován u všech takových prostředí. Čím vyšší stupeň přehledu o datech uživatel má, tím optimálněji je schopen zajistit zpracování dat a tím mohutnějším nástrojem se pak takový prostředek pro něj stává.
Jedním z poměrně zdařilých a v mnoha různých (i operačních) systémech implementovaným nástrojem pro zpracování dat je SQL (z plného anglického označení Structured Query Language; toto označení se dnes většinou už nepřekládá a používá se jen SQL).
Oproti jiným podobným obecným nástrojům má SQL nejen funkce dotazovací (tj. pro čerpání dat z existujících databází), ale i funkce pro plné zpracování dat: vytváření nových databází a tabulek o definované struktuře, plnění daty, změny dat ap.
V současné době většina implementací SQL pracuje nad relačními databázemi (kde data „mají podobu“ tabulek). Odtud také zástupná klíčová slova typu "table". Protože však existuje poměrně snadná (protože mechanická) konverze hierarchické (ne síťové) struktury na relační, některé SQL mají možnost pracovat i na hierarchických organizacích datových bází.
V této kapitole je popsána logika a nástin použití základních
příkazů SQL. Protože jde o poměrně širokou problematiku, u které je předpoklad
plného využití, je nutno odkázat na příslušné referenční manuály. Proto také
jsou v této kapitole jednotlivé příkazy uváděny již na konkrétních příkladech
a nejsou popisovány ani syntakticky úplně. Všechny příklady jsou předkládány
na části datového modelu, jehož data, strukturu a částečně obsah ukazují
následující schémata:
Obrázek 1: Tabulky demonstrační databáze
Poznámka: z technických důvodů nejsou ve shora uvedených tabulkách šířky sloupců opticky ekvivalentní jejich skutečným hodnotám používaným v příkladech.
Protože uspořádání dat je chápáno "tabulkově", jsou zavedeny ve zřejmém smyslu tyto pojmy: jméno sloupce, šířka sloupce, typ sloupce. Konkrétně typ sloupce je typem každého z jednotlivých údajů, které sloupec tvoří (viz doména a její atributy v kapitole o relačních databázích v [1]). Podrobněji o typech dat viz kapitola "Datové typy při provozu databází" v [1].
SQL pracuje obecně s následujícími typy dat a jejich kódováním:
Jde o číselná data v běžném pojetí. Pro větší variabilitu použití jsou dále dělena na dva základní pod-typy: čísla celá a čísla racionální (mající konečnou "desetinnou" část). I tyto pod-typy ještě mohou být jemněji děleny podle velikosti paměti potřebné pro uložení jejich hodnot; tím je de facto dán rozsah jejich možných hodnot.
Jakékoliv texty, obsahující jakékoliv znaky většinou podle kódových tabulek znaků. Charakteristikou je jejich šířka - maximální počet znaků.
Kalendářní datum bývá zavedeno jako samostatný typ proto, že jsou na něm definovány přirozeným způsobem operace přičítání a odečítání čísla, avšak tyto operace nejsou běžné aritmetické operace (např. přechod přes konec měsíce nebo roku). Jejich šířka je vždy konstantní, nejčastěji 8.
Dvouhodnotová data: ANO a NE. Používají se jako indikativní ukazatele apod. Jejich šířka je vždy konstantní, nejčastěji 1.
Různé implementace mohou zavádět další typy údajů; shora uvedené čtyři typy však postačují pro většinu aplikací běžných aplikací.
Vytvořením nové tabulky se ve většině systémů rozumí založení nového datového úložiště s daným jménem, který obsahuje dvě části: jednak popis jednotlivých sloupců tabulky, jednak vlastní data tabulky organizovaná do řádků. Bezprostředně po vytvoření nové tabulky je druhá část prázdná (zatím nejsou vložena žádná data).
Vytvoření tabulky ČERPÁNÍ provede následující příkaz:
create table ČERPÁNÍ (VRT text(5), DATUM date, HLADINA integer, MNOŽSTVÍ integer)
Po klíčových slovech CREATE TABLE se tedy uvede jméno tabulky a za ním, uzavřený v kulatých závorkách, seznam popisů jednotlivých sloupců tabulky (=polí řádků). Každý popis obsahuje jméno sloupce následované klíčovým slovem ve smyslu typu event. s uvedením maximální šířky.
Příkaz
create table ČERPÁNÍ (VRT text(5) primary key, ...)
provede totéž, ale navíc pro tabulku definuje tzv. primární přístupový klíč, jehož hodnotami budou kódy vrtů zařazovaných řádků dat.
Úpravou struktury se rozumí přidání nebo vypuštění sloupce tabulky. Bez bližších komentářů jsou uvedeny příklady charakteristického tvaru:
alter table ČERPÁNÍ add column VYDATNOST real
přidá do tabulky ČERPÁNÍ nový sloupec VYDATNOST.
alter table ČERPÁNÍ alter column VYDATNOST float
změní v tabulce ČERPÁNÍ typ dat ve sloupci VYDATNOST.
alter table ČERPÁNÍ drop column VYDATNOST
vypustí sloupec VYDATNOST z tabulky ČERPÁNÍ.
Do existující tabulky (např. právě vytvořené) je možno přidávat data. Do shora vytvořené tabulky ČERPÁNÍ se přidají nové řádky příkazem např.
insert into ČERPÁNÍ values ('V12', #12/02/97#, -122, 78)
Příkaz přidá na konec tabulky nový řádek dat a naplní ho hodnotami uvedenými jako seznam v kulatých závorkách. Data musí být uvedena v takovém množství, kolik je polí, a musí následovat v tom pořadí, jak byla pole uvedena při vytvoření tabulky. Datum se předpokládá v americkém formátu - zde tedy nikoliv 12. února, ale 2. prosince.
Aktualizaci existujících dat v existující tabulce provádí příkaz UPDATE. Např. zvýšení množství čerpání o 0.1 u všech řádků s hladinou pod 100 provede příkaz
update ČERPÁNÍ set MNOŽSTVÍ = MNOŽSTVÍ+0.1 where HLADINA < 100
Vynulování hladiny a množství u některých řádků provede příkaz
update ČERPÁNÍ set MNOŽSTVÍ = 0, HLADINA = 0 where VRT = 'V12'
Výrazem za klíčovým slovem WHERE se určuje množina řádků, pro které se má náhrada (=aktualizace) provést - zde tedy pro všechny údaje vrtu V12.
Otázka vypouštění řádků je poněkud složitější. Příkaz
delete from ČERPÁNÍ where HLADINA < 100 and MNOŽSTVÍ > 1
doslova přeložen vypustí z tabulky ČERPÁNÍ řádky, kde je hladina pod 100 a množství nad Problém spočívá v nebezpečnosti akce. Pokud (např. omylem) by byly vypuštěny jiné řádky než uživatel skutečně vypustit chtěl, obtížně by se zajišťovala náprava.
Některé implementace SQL provedou nikoliv fyzické vypuštění, ale pouze označení řádků za neplatné. Toto označení lze především příkazem typu RECALL odstranit, takže se žádné řádky neztratí. Dále: při jakémkoliv dalším zpracování se takto označené řádky nebudou vůbec brát v úvahu. Při výběrech dat, při aktualizaci atd. to bude vypadat tak, jako by tam tyto řádky skutečně nebyly.
Fyzické zrušení (vypuštění, odstranění) řádků z databáze pak provede specielní, k tomu určený příkaz, který většinou závisí na implementaci. Je-li např. SQL implementováno v prostředí xBase, je tímto příkazem PACK.
Tento odstavec je stěžejním odstavcem celé kapitoly. Zatímco organizaci databází (jejich zakládání a aktualizaci) - zvláště informačních systémů větších rozsahů - provádí většinou specializovaní nebo alespoň zvlášť určení pracovníci, čerpat z databází by měli mít potřebu všichni.
Ke získávání informací z existujících bází dat slouží v SQL jediný příkaz - SELECT. Jde o velmi silný, poměrně obecný a tedy poněkud složitější příkaz. Proto bude vysvětlen v jednotlivých krocích.
Jako příklad budeme uvažovat uvedenou část modelové databáze geologických souvrství. Konkrétně půjde o tabulky VZORKY, VRSTVY, SOUVRSTVÍ.
Obecně lze říci, že příkaz SELECT vybere určené údaje z určených databází (tabulek) a vytvoří tabulku novou. Může jít o tabulku fyzickou (tj. soubor na médiu) nebo tabulku dočasnou (která po použití zanikne).
Mějme tedy tabulku VZORKY, která má pole SOUVRSTVI, VRSTVY, VRT, HLOUBKA. Následně jsou uvedeny nejjednodušší tvary příkazu SELECT.
select * from VZORKY
Vybere všechny sloupce ze všech řádků tabulky VZORKY.
select VRT, HLOUBKA from VZORKY
Vybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY.
select distinct VRT, HLOUBKA from VZORKY
Vybere sloupce VRT a HLOUBKA z tabulky VZORKY. Klíčové slovo DISTINCT zajišťuje, že ve vytvořené tabulce nebudou žádné dva řádky stejné - řádků tedy bude nanejvýš stejný počet jako ve zdrojové tabulce VZORKY.
select VRT, HLOUBKA*100/2.54 as PALCE from VZORKY
Vybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY. Na výstupu však druhý sloupec nebude obsahovat původní údaje o hloubce, ale údaje přepočtené podle uvedeného výrazu (přepočet na palce). Tento druhý sloupec výstupu také nebude mít název HLOUBKA, ale PALCE. Příklad demonstruje použití výrazů pro výpočet hodnot výstupu.
Poznámka: Konstrukci <výraz> AS <jméno> je možno použít kdykoliv kdekoliv při určování, jaké hodnoty mají tvořit sloupec výstupní tabulky, a jak se tento sloupec má jmenovat. Tato skutečnost již nebude dále zdůrazňována a většinou bude používáno pouze jméno sloupce zdrojové tabulky.
select VRT, HLOUBKA from VZORKY into VÝBĚR
Vybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a z těchto údajů vytvoří novou tabulku VÝBĚR. Tabulka VÝBĚR bude mít dva sloupce VRT a HLOUBKA (v tomto pořadí) s atributy i hodnotami dat přejatými z tabulky VZORKY. Počet řádků obou tabulek bude shodný.
Poznámka: Konstrukci INTO <výstup> je možno použít, kdykoliv je zapotřebí vytvořit novou tabulku na základě dat v tabulkách již existujících. Tato skutečnost již nebude dále zdůrazňována a klauzule INTO bude většinou vynechána (tj. výstup bude směrován na standardní výstup, kterým je většinou obrazovka terminálu nebo počítače).
select VRT, HLOUBKA from VZORKY into VÝBĚR where HLOUBKA > 100
Vybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a z těchto údajů vytvoří novou tabulku VÝBĚR. Tabulka VÝBĚR bude mít dva sloupce VRT a HLOUBKA (v tomto pořadí) s atributy i hodnotami dat přejatými z tabulky VZORKY. V tabulce VÝBĚR však budou zařazeny jen údaje z těch řádků tabulky VZORKY, ve kterých je HLOUBKA větší než 100.
Poznámka: Konstrukci WHERE <podmínka> je možno použít kdykoliv kdekoliv při určování, jaké řádky zdrojové tabulky se mají zpracovávat při vytváření řádků výstupní tabulky. Tato skutečnost již nebude dále zdůrazňována a většinou bude používáno všech řádků zdrojové tabulky.
select VRT, HLOUBKA from VZORKY into table VÝBĚR order by VRT asc, HLOUBKA desc
Vybere sloupce VRT a HLOUBKA ze všech řádků tabulky VZORKY, a z těchto údajů vytvoří novou tabulku VÝBĚR. Tabulka VÝBĚR bude mít dva sloupce VRT a HLOUBKA (v tomto pořadí) s atributy i hodnotami dat přejatými z tabulky VZORKY. Řádky v tabulce VÝBĚR budou seřazeny (asc - ascending = vzestupně) podle kódů vrtů (A18 bude před B11). Pokud dva řádky budou mít shodný kód vrtu, bude rozhodovat hloubka: [V18,140] bude před [V18,120], protože u jména HLOUBKA je uvedeno klíčové slovo desc - descending = sestupně.
Poznámka: klíčové slovo asc se nemusí uvádět. Není-li uvedeno ani asc, ani desc, platí asc.
select VRT, min (HLOUBKA) as DOLE, max (HLOUBKA) as NAHORE from VZORKY group by VRT
Jedna z velmi silných možností příkazu SELECT. Příkaz v tomto tvaru provádí nejprve myšlené seskupování ("grupování") řádků zdrojové tabulky VZORKY podle údajů ze sloupce VRT - v každé takové skupině jsou ty řádky tabulky VZORKY, které mají stejnou hodnotu ve sloupci VRT. Na výstupu se pak vytvoří tolik řádků, kolik je skupin (tj. kolik různých kódů vrtů je ve vstupní tabulce).
Z každé takto vytvořené skupiny se pošle na výstup jeden řádek. Výstupní tabulka bude mít tři sloupce. První (se jménem VRT) bude obsahovat kód vrtu společný všem řádkům skupiny. Druhý (se jménem DOLE) bude obsahovat nejmenší z hodnot HLOUBKA v této skupině. Analogicky třetí sloupec (se jménem NAHORE) bude obsahovat největší z hodnot HLOUBKA v této skupině.
Poznámka: Kromě funkcí MIN a MAX je možno při seskupování používat funkce AVG (average = průměr), COUNT (count = počet) a SUM (suma = počet).
Je možno použít seskupování podle více kriterií. Například klauzule
... group by SOUVRSTVI, VRT ...
vytvoří tolik skupin, kolik je ve vstupní tabulce různých dvojic [SOUVRSTVI,VRT].
Poznámka: Konstrukci GROUP BY <sloupec> je možno použít, kdykoliv nastane potřeba na výstup zařadit ne jednoduché údaje ze vstupní tabulky, ale údaje nějakým způsobem agregované. Tato skutečnost již nebude dále zdůrazňována a většinou bude používáno neseskupených dat.
Výstupní tabulku lze vytvořit na základě údajů ze dvou a více zdrojových tabulek. Nejjednodušší je případ dvou tabulek.
select VZORKY.VRT, VZORKY.HLOUBKA, SOUVRSTVI.NAZEV from VZORKY, SOUVRSTVI
Tento základní tvar příkazu SELECT obsahující dva zdrojové soubory pracuje následovně: především je vytvořena kombinace všech řádků (se všemi sloupcovými údaji) jedné zdrojové tabulky a všech řádků (se všemi sloupcovými údaji) druhé zdrojové tabulky.
Poznámka: mají-li obě vstupní tabulky po pouhém tisící řádků, má tato kombinovaná tabulka řádků milion.
Dále: uvedená výstupní tabulka je vytvořena ze všech těchto zkombinovaných řádků s tím, že bude mít tři sloupce; v prvním budou data ze sloupce VRT té části, která vznikla z tabulky VZORKY; ve druhém budou data ze sloupce HLOUBKA té části, která rovněž vznikla z tabulky VZORKY; konečně ve třetím budou data ze sloupce NAZEV té části, která vznikla z tabulky SOUVRSTVI.
Toto je přesný popis vzniku tabulky. Je zřejmé, že právě v uvedeném příkladě se většinou ve výstupní tabulce ocitnou nesmyslné kombinace údajů. Jestliže např. vrt A18 zasahuje jen do ostravského souvrství (tj. logická je jen kombinace [O,A18]), přesto se ve výstupní tabulce objeví i kombinace [K,A18] a případné další.
Je proto zapotřebí vybrat jen ty kombinace, které vyplývají z dat vzorků. To provede tvar příkazu SELECT s již dříve uvedenou klauzulí WHERE:
select VZORKY.VRT, VZORKY.HLOUBKA, SOUVRSTVI.NAZEV from VZORKY, SOUVRSTVI where VZORKY.SOUVRSTVI = SOUVRSTVI.KOD
Nyní jsou do výstupní tabulky ze všech možných kombinací zařazeny jen ty, kde kód SOUVRSTVÍ ve VZORKU je rovno KÓDU v SOUVRSTVÍ. Tento mechanismus je možno považovat za vytvoření "filtru" mezi VZORKY a SOUVRSTVÍmi. "Odfiltrují" se všechny řádky, které nesplňují podmínku uvedenou za WHERE, jinak zde: ke každému řádku ze VZORKŮ se připojí ten řádek ze SOUVRSTVÍ, který má shodný kód s kódem souvrství ve VZORCÍCH.
Klauzuli WHERE je možno dále rozšířit o běžné podmínky výběru, např.
select VZORKY.VRT, VZORKY.HLOUBKA, SOUVRSTVI.NAZEV from VZORKY, SOUVRSTVI where VZORKY.SOUVRSTVI = SOUVRSTVI.KOD and HLOUBKA > 100
Funkce je zcela totožná jako shora až na to, že ve výstupní tabulce budou zahrnuty jen ty řádky, kde je větší hloubka než 100.
Poznámka: zcela podle potřeby je možno použít klauzulí GROUP BY, ORDER BY a INTO TABLE ve smyslu popsaném shora.
Uvedený příklad na čerpání dat ze dvou datových zdrojů používal mechanismu tzv. kartézského součinu dvou množin. Nevýhodou však je, že výsledek takového příkazu nelze použít pro aktualizaci dat zdrojových tabulek.
Čerpat data ze dvou tabulek lze však také pomocí mechanismu připojení (angl. join). Protože zápis příkazu SQL je lineární (zleva doprava), pak při použití dvou datových zdrojů je jeden první (vlevo od druhého) a jeden druhý (vpravo od prvního). Jedna z tabulek připojuje druhou na základě nějaké podmínky:
select VZORKY.VRT, VZORKY.HLOUBKA, SOUVRSTVI.NAZEV from VZORKY left join SOUVRSTVI on VZORKY.SOUVRSTVI = SOUVRSTVI.KOD where HLOUBKA > 100
Výsledek bude na první pohled stejný jako v předchozím případě. V situaci, kdy si tabulka VZORKY zleva připojuje tabulku SOUVRSTVÍ, objeví se na výstupu i ty vzorky, pro které případně ve druhé tabulce neexistuje souvrství. Takové vzorky by se v předchozím případě neobjevily. Kdyby si naopak tabulka VORKY zprava (right join) připojovala tabulku souvrství, objevily by se na výstupu všechna souvrství a jejich vzorky, a to i ta souvrství, pro něž event. neexistují vzorky. Konečně kdyby byly oba datové zdroje vnitřně (inner join) připojeny, byl by výsledek datově stejný jako v předchozím případě. V čem je však podstatný rozdíl: pomocí výsledku druhého příkazu (s join) jde na rozdíl od předchozího příkladu data aktualizovat.
Pro tři a více tabulek platí zřejmá analogie se dvěma tabulkami. Nejprve se - v prvním případě -vytvoří mezi-tabulka tvořená ze všech možných kombinací všech řádků všech zdrojových tabulek. Výstupní tabulka bude mít tolik sloupců, kolik je určeno výčtem za klíčovým slovem SELECT. Na výstup se dostanou jen ty řádky, které splní podmínku uvedenou za WHERE.
Tedy např. pro čtyři tabulky příkaz
select
VZORKY.VRT, VZORKY.HLOUBKA, VRTY.X, VRTY.Y, VRSTVY.PLOCHA, SOUVRSTVI.NAZEV
from VZORKY, VRTY, VRSTVY, SOUVRSTVI
where
VZORKY.VRT = VRTY.KOD
and VZORKY.VRSTVA = VRSTVY.KOD
and VRSTVY.SOUVRSTVI = SOUVRSTVI.KOD
ponechá ve výstupní tabulce jen ty řádky, které mají shodné "vazební" prvky uvedené na každé straně rovnítek.
Poznámka: i u tohoto tvaru příkazu SELECT je možno zcela podle potřeby použít klauzulí GROUP BY, ORDER BY a INTO TABLE ve smyslu popsaném shora.
Ve druhém případě - s klauzulí join - vytváří každá konstrukce typu
... (A left join B on A.X = B.Y) ...
nový datový zdroj, který (nebo na který) je možno připojit další datový zdroj, tím vznikne další nový datový zdroj, na který lze připojit ... atd.
Síla příkazu SELECT se násobí možností použít uvnitř jednoho příkazu SELECT jiný příkaz SELECT - tzv. poddotaz. Ten lze využít např. při výpočtu výsledných údajů nebo při určení datových zdrojů. Velmi často se použije při definování podmínek, za kterých se řádek ve výstupní tabulce vytvoří. V tomto případě se uplatní operátory IN, ANY, ALL, jak je ukázáno dále.
select VRT, HLOUBKA from VZORKY where VRT in (select distinct VRT from ČERPÁNÍ where MNOŽSTVÍ > 10)
Tento příkaz SELECT obsahuje druhý příkaz SELECT použitý v klauzuli WHERE; "vnitřní" příkaz se provede nejdříve a vytvoří (dočasný) seznam kódů vrtů, kde se čerpalo (alespoň jednou) větší množství než 10. Následuje tvorba výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY již popsaným způsobem. Do výsledné tabulky se však umístí jen ty řádky, které vyhovují podmínce uvedené v klauzuli WHERE - zde ty, kde se kód VRT vyskytuje v (in) seznamu vytvořeném oním "vnitřním" příkazem SELECT (tedy v seznamu vrtů, v nichž bylo alespoň jednou čerpáno větší množství než 10).
Poznámka: kromě IN lze použít i negaci NOT IN.
select VRT, HLOUBKA from VZORKY where exists (select * from ČERPÁNÍ where VZORKY.VRT = ČERPÁNÍ.VRT)
Při vytváření výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY se pro každý řádek nejprve zjistí, zda je splněna podmínka daná klauzulí WHERE; tj. zda existuje (exists) alespoň jeden řádek tabulky vytvořené "vnitřním" příkazem SELECT. Ten vybere z tabulky ČERPÁNÍ všechny řádky mající kód vrtu shodný s kódem právě zařazovaného řádku z tabulky VZORKY. Pokud existuje, řádek se zařadí; pokud neexistuje, řádek se nezařadí. Výsledná tabulka tedy bude obsahovat údaje jen o těch vrtech, ze kterých bylo čerpáno.
Poznámka: kromě EXISTS lze použít i negaci NOT EXISTS.
select VRT, HLOUBKA from VZORKY where HLOUBKA+10 > ALL (select HLADINA from ČERPÁNÍ where ČERPÁNÍ.DATUM >= #01/01/1997# )
Při vytváření výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY se pro každý řádek nejprve zjistí, zda je splněna podmínka daná klauzulí WHERE; tj. hloubka vrtu je alespoň o 10 větší než všechny hladiny při čerpáních počínaje rokem 1997.
select VRT, HLOUBKA from VZORKY where HLOUBKA+10 > ANY (select HLADINA from ČERPÁNÍ where ČERPÁNÍ.DATUM >= #01/01/1997# )
Při vytváření výsledné tabulky obsahující sloupce VRT a HLOUBKA z tabulky VZORKY se pro každý řádek nejprve zjistí, zda je splněna podmínka daná klauzulí WHERE; tj. hloubka vrtu je alespoň o 10 větší než alespoň jedna hladina při čerpáních počínaje rokem 1997.
[1] DROZDOVÁ, J., HOMOLA, V.: Databáze pro geovědní obory. VŠB-TU Ostrava 2019. ISBN 978-80-248-4265-3.
Orig: 7 / 1995
Rev: 11 / 2021