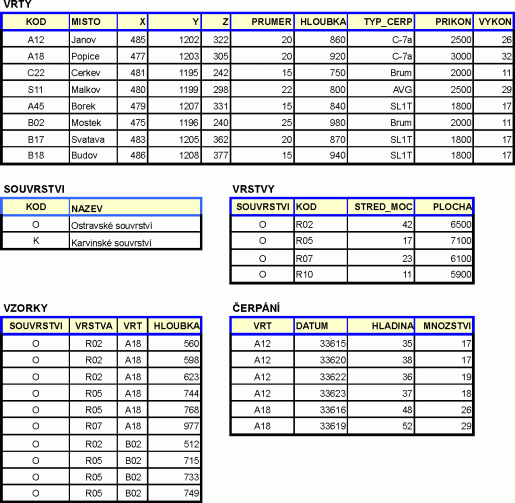
Obrázek 1: Tabulky demonstrační databáze
Realizace obecného datového modelu v xBase
Doc. Dr. Vladimír Homola, Ph.D.
Poznámka: Tento článek byl jedním ze zdrojů pro publikaci [1] stejného autora.
Jako xBase je označován další rozšířený jazyk používaný pro vytváření, údržbu a čerpání informací z bází dat. xBase stejně jako SQL pracuje ve všech známých implementacích na relačních databázích, tj. na datech "tabulkově" uspořádaných.
Oproti popsanému jazyku SQL má xBase daleko silnější možnosti zvláště při vytváření virtuálních datových struktur a jejich používání pro aktualizaci dat; to SQL neumožňuje vůbec. Na druhé straně většina realizovaných systémů xBase mají zabudovány alespoň základní příkazy SQL jako své vlastní interní příkazy, čímž umožňuje své využití i těmi uživateli, kteří SQL pro své potřeby dobře zvládli.
Většina systémů založených na xBase používá svých příkazů jak v interaktivním, tak v dávkovém režimu. Při prvním z nich se střídá zadání příkazu uživatele s jeho okamžitým provedením systémem.
V dávkovém režimu zapíše nejprve uživatel své příkazy do běžného textového souboru a ten pak předá systému k provedení "najednou". Jelikož tento textový soubor obsahuje příkazy, je běžně označován jako příkazový soubor. Textový soubor s příkazy je trvalý, příkazy v něm lze tedy provádět opakovaně; dále je možno jejich provádění parametrizovat. Protože provedení příkazů v souboru se vyžádá od systému jeho příkazem DO (a DO může být jedním z příkazů v souboru), je možno vytvářet zřetězené (až do úrovně rekurze) provádění akcí. Možnost popsat příkazy v textovém souboru algoritmy pro výpočet hodnoty vlastní funkce a zařazení několika příkazů řídících způsob provádění ostatních příkazů tvoří z xBase kompletní, velmi silný jazyk nejen dotazovací a organizační, ale také programovací.
xBase zpřístupňuje uživateli data buď ve tvaru formuláře, nebo ve tvaru tabulky. Datový obsah formuláře i tabulky určuje plně uživatel. Formát tabulky může uživatel částečně určovat sám - na rozdíl od formátu formuláře, který uživatel určuje zcela.
Pokud uživatel neurčí jinak, lze všechna data jak v tabulce, tak ve formuláři měnit. Při jakékoliv změně kteréhokoliv údaje je možno nadefinovat kontrolní funkce. Kromě interních funkcí xBase (kterých je asi 200) lze ke kontrolním účelům nadefinovat jakékoliv vlastní algoritmy.
Pro tiskový výstup obsahuje xBase mechanismus pro definici tvaru výstupní sestavy včetně typů písma, seskupování údajů, základních statistických operací nad skupinami údajů apod.
Příkazů xBase je asi 400. Tato práce není referenční příručka jazyka; výklad je zaměřen na pochopení základní linie, a tou je vytváření datových struktur z více zdrojů. Proto je dále popsána jen velmi omezená podmnožina příkazů, která však plně postačuje k uvedenému účelu.
Příkazy budou vysvětlovány na stejných modelových datech jako kapitole „Příkazy SQL“ v [1]:
Obrázek 1: Tabulky demonstrační databáze
Poznámka: z technických důvodů nejsou ve shora uvedených tabulkách šířky sloupců opticky ekvivalentní jejich skutečným hodnotám používaným v příkladech.
Vytvoření (=definice) nové tabulky a přidávání řádků dat provádí xBase příkazy CREATE a APPEND, které jsou v tomto tvaru interaktivními příkazy: po jejich zadání je uživatel dotazován na další specifikace resp. data. Protože většina systémů s xBase mají implementovány základní příkazy SQL, lze k těmto dvěma akcím použít také příkaze CREATE TABLE a APPEND INTO kategorie SQL.
Pokud je zapotřebí čerpat data z tabulek nebo je zpřístupnit, je nutno nejprve tyto tabulky "otevřít" - sdělit systému, že je má "použít". Systém má pro zpracovávané tabulky vyhrazeny tzv. oblasti: v každé z nich může být použita (otevřena) jedna tabulka. Počet oblastí bývá minimálně 20. Uvedenou akci provede příkaz ve tvaru např.
use VRTY in 3
který v oblasti č. 3 zpřístupní (otevře, použije) tabulku VRTY.
Systémy s xBase mají možnost jednak otevřít již otevřenou tabulku ještě jednou, jednak otevřené tabulce dočasně - po dobu otevření - přidělit jiné jméno:
use VRTY in 7 again alias SONDY
Uvedený tvar příkazu klíčovým slovem AGAIN sděluje, že se mají VRTY otevřít ještě jednou, a klauzulí ALIAS přidělují souboru v oblasti 7 dočasně jméno SONDY.
Poznámka: jakmile je v oblasti otevřena tabulka, je oblast identifikovatelná nejen číslem, ale také (dočasným) jménem tabulky, která je v oblasti otevřena písmeny A pro oblast č. 1, B pro oblast č. 2 atd.
Příkaz USE bez udání souboru, tj.
use in 7
uzavírá tabulku dat v dané oblasti. Kromě jiného bezpečně zaznamená do fyzické tabulky všechny případně provedené změny.
Poznámka 1: Tabulka dat je většinou uložena jako trvalý záznam na nějakém médiu: disku, disketě ap. Pro urychlení práce většina systémů vytváří obraz tabulky (po jejím otevření) ve vnitřní paměti. Tedy všechny případné změny provádí uživatel v paměti a to nastoluje otázku existence změn např. při výpadku napájení počítače. Jednu odpověď podává shora uvedené vysvětlení činnosti při uzavírání tabulky.
Poznámka 2: Tabulka otevřená v nějaké oblasti se uzavře také tehdy, když je vydán příkaz pro otevření jiné tabulky v téže oblasti.
Při práci s tabulkami je vždy jedna oblast tzv. aktuální. Pro ni se nemusí v příkazech zadávat specifikace oblasti klauzulí IN. Po spuštění systému je aktuální oblastí oblast č. 1.
Nastavení se do konkrétní oblasti (učinění oblasti aktuální) provede příkaz SELECT (nikoliv SQL!) tvaru
select 6
který v tomto případě učiní aktuální oblastí oblast č. 6.
Každá otevřená tabulka má přiřazeno "ukazovátko" (=pointer) na tzv. aktuální řádek. Data jsou přístupná pouze z toho řádku, který je aktuálním, na který ukazuje ukazovátko. Pohyb ukazovátka ovládají příkazy GOTO a SKIP. Dále zajišťuje pohyb ukazovátka sám uživatel pomocí (většinou kurzorových) kláves při pohybu ve formuláři nebo zobrazené tabulce.
První ze zmíněných příkazů má tvar např.
goto 12 in 7
nebo
goto 12 in SONDY
který nastaví ukazovátko do tabulky VRTY, která je otevřena v oblasti č. 7 pod dočasným názvem SONDY, na dvanáctý řádek tabulky. Řádky se přitom počítají podle skutečného, fyzického uložení v tabulce.
Druhý z uvedených příkazů má tvar např.
skip 3 in 7
nebo
skip 3 in SONDY
který nastaví ukazovátko o tři řádky směrem ke konci tabulky SONDY (v tabulce dolu). Záporné číslo posunuje ukazovátko směrem k začátku tabulky. Pohyb v tabulce přitom podléhá případné připojené indexové tabulce (viz níže). Je-li aktuálním řádkem řádek s fyzickým pořadovým číslem 12, pak po provedení SKIP 3 nemusí být novým aktuálním řádkem řádek s fyzickým pořadovým číslem 15!
Datová pole, se kterými si uživatel právě teď přeje pracovat, jsou určena v mnoha příkazech pro práci s daty. Datové pole má tvar např.
SONDY.MÍSTO
tedy (dočasné) jméno tabulky, za kterým bezprostředně po tečce následuje jméno sloupce databáze. Výsledkem je v tomto případě hodnota ve sloupci MÍSTO tabulky SONDY (=VRTY v oblasti č. 7), a to v tom řádku, na který právě teď ukazuje ukazovátko.
Poznámka: Srovnej seznam v příkazu SELECT SQL výše.
Indexové tabulky slouží v relačních databázových systémech ke dvěma účelům:
Pro každou tabulky dat je možno (trvale) vytvořit jednu nebo více indexových tabulek s tímto souborem spojených. Spojení je většinou logické; např. v systémech na PC je tabulka dat jako taková uložena v souboru např. VRTY.DBF, a všechny její indexové tabulky v souboru VRTY.CDX - pokud je alespoň jedna tabulka vytvořena. Takový soubor je nazýván indexovým souborem.
Indexové tabulky jsou ukládány pod zadaným jménem. Klíčem je libovolný výraz toho typu, jaký databázový systém připouští pro operace porovnávání (tj. vždy nejméně numerické, textové, datumové a logické).
Poznámka: společně se samotnou indexovou tabulkou se v indexovém souboru ukládá nejen její jméno, ale i výraz, podle kterého je vytvořen její klíč.
Vytvoření indexové tabulky pro tabulku dat v aktuální oblasti provádí příkaz tvaru např.
index on MÍSTO tag INÁZ
který vytvoří k datové tabulce otevřené v aktuální oblasti indexovou tabulku s názvem INÁZ, jejímž klíčem je MÍSTO (tabulka je tedy "podle abecedy").
Tvar příkazu v předchozím příkladě vytváří indexovou tabulku ve vzestupném pořadí. Připojí-li se na konec příkazu klíčové slovo DESCENDING, vytvoří se tabulka v opačném pořadí (sestupně).
Poznámka: Systém uchovávání a označování indexových tabulek má jeden zásadní pozitivní efekt: kdykoliv je vytvořena alespoň jedna indexová tabulka, při otevírání souboru je databázový systém schopen to zjistit. To dále znamená, že je schopen zjistit i všechny klíčové výrazy. Konečně tedy je schopen automaticky aktualizovat všechny indexové tabulky, které závisí na údaji v tabulce dat, který se právě teď změnil. Uživateli tedy stačí jednou jedinkrát kdykoliv vytvořit indexovou tabulku (např. po založení databáze a ještě před jejím plněním řádky dat!), a dále se o její údržbu nestará.
Sama existence indexových tabulek ještě neznamená jejich využití. Po otevření tabulky dat se pohyb ukazovátka po řádcích řídí fyzickým pořadím řádků (tedy v pořadí jejich záznamů příkazem APPEND). Příkaz ve tvaru např.
set order to INÁZ in SONDY
připojí pro následné zpracování tabulky dat SONDY indexovou tabulku INÁZ. To znamená, že pohyb ukazovátka na řádky tabulky dat bude zprostředkovávat indexová tabulka. Jako první řádek bude zpřístupněn ne fyzicky první řádek dat, ale řádek dat, který je podle hodnoty klíče (zde MÍSTO) první v indexové tabulce. Jako druhý řádek bude zpřístupněn řádek s hodnotou klíče, která je druhá v indexové tabulce atd.
Poznámka: Je-li indexová tabulka vytvořena vzestupně, je prvním zpřístupněným řádkem řádek s nejmenším klíčem; je-li vytvořena sestupně, je prvním zpřístupněným řádkem řádek s největším klíčem.
Příkaz pro připojení indexové tabulky může obsahovat klíčové slovo DESCENDING:
set order to INÁZ in SONDY descending
Tento příkaz připojí pro následné zpracování tabulky dat SONDY rovněž indexovou tabulku INÁZ. Jako první řádek však bude zpřístupněn ne fyzicky první řádek dat, ale řádek dat, který je podle hodnoty klíče (zde MÍSTO) poslední v indexové tabulce. Jako druhý řádek bude zpřístupněn řádek s hodnotou klíče, která je předposlední v indexové tabulce atd.
Poznámka: Je-li v tomto případě indexová tabulka vytvořena vzestupně, je prvním zpřístupněným řádkem řádek s největším klíčem; je-li vytvořena sestupně, je prvním zpřístupněným řádkem řádek s nejmenším klíčem.
Připojit indexovou tabulku lze také již při otevření tabulky dat:
use VRTY in 7 again alias SONDY order INÁZ
Výše uvedený příkaz SKIP podléhá připojení nebo nepřipojení indexové tabulky. Je-li nějaká indexová tabulka připojena, pak příkaz SKIP 1 posune ukazovátko na řádek tabulky, který má klíč s nejbližší vyšší (nižší v případě sestupného pořadí) hodnotou než řádek aktuální. Není-li žádná tabulka připojena, pak je jako následující řádek zpřístupněn řádek následující podle fyzického pořadí řádků v tabulce.
Poznámka: V daném okamžiku může být připojena nanejvýš jedna indexová tabulka. Kombinace typu "nejprve podle datumu, potom podle abecedy" se řeší výrazem v (jediném) indexovém klíči.
Příkaz tvaru např.
set index to in SONDY
odpojuje (pro další zpracování) připojenou indexovou tabulku k datové tabulce SONDY. Další zpracování tedy bude probíhat podle fyzického pořadí řádků datové tabulky.
Mezi (otevřenými) tabulkami je možno vytvářet logické vazby. Jedna z tabulek je vždy "řídící": po ní jest pohybováno ukazovátkem a z ní vychází vazby první úrovně. Vazby směřují do jedné nebo více ostatních tabulek; tyto tabulky jsou cílem vazby. Na druhé straně z těchto tabulek mohou vycházet vazby druhé úrovně atd.
Jedna konkrétní vazba je zprostředkována jedním konkrétním klíčem. Tímto klíčem je hodnota jakéhokoliv výrazu toho typu, který může být klíčem při vytváření indexové tabulky (viz nahoře).
Na straně tabulky dat, ze které vychází vazba, musí být hodnota klíče kdykoliv opakovatelně zjistitelná. Na straně tabulky, do které směřuje vazba, musí být podle tohoto klíče vytvořena a připojena indexová tabulka.
Vytvoření vazby z tabulky VZORKY (která obsahuje kódy vrtů) do tabulky VRTY (která obsahuje např. souřadnice vrtu a tedy souřadnice vzorku) vyžaduje především vytvořenou indexovou tabulku podle klíče, pomocí něhož bude vazba zprostředkována, tj. podle kódu vrtu. To provede příkaz tvaru např.
index on KÓD tag IKÓD
(viz výše). Celá sekvence příkazů pro vytvoření uvedené vazby je následující:
use VRTY in 2 order IKÓD
use VZORKY in 1
set relation to VRT into VRTY
Tabulkou, ze které vychází vazba, je tabulka VZORKY. Tabulkou, do které směřuje vazba, je tabulka VRTY. Výrazem, který zprostředkovává vazbu, je kód vrtu, který je v tabulce VZORKY umístěn ve sloupci VRT a v tabulce VRTY ve sloupci KÓD (a podle něhož je pro VRTY vytvořena indexová tabulka IKÓD).
Po vytvoření vazby je "řídící" tabulkou tabulka VZORKY. Pohyb ukazovátka v tomto souboru řídí uživatel ať přímo příkazy GOTO nebo SKIP nebo pohybem ve zobrazovací tabulce dat, nebo nepřímo příkazy pro hromadné zpracování.
Pohyb ukazovátka v tabulce, do které směřuje vazba, je však řízeno vytvořenou vazbou. Ukazovátko v tomto cílovém souboru ukazuje vždy na ten řádek, který má shodný klíč (v indexové tabulce) s hodnotou klíče, který na straně zdrojové tabulky vazbu zprostředkovává.
Konkrétně tedy ukazovátkem v tabulce VZORKY pohybuje nějakým způsobem uživatel. Ukazovátko v tabulce VRTY ukazuje vždy na ten vrt, který má stejný kód jako je hodnota položky VRT v tom řádku tabulky VZORKY, na který právě ukazuje ukazovátko.
Je nutno řešit dvě situace:
Je-li vazba 1:n povolena, pak při pokusu o pohyb ukazovátka v řídícím souboru se nejprve pohne ukazovátko v podřízeném souboru na následující řádek, má-li stejný klíč. Teprve až by se tímto způsobem mělo nastavit ukazovátko na řádek s jinou hodnotou klíče, dojde k pohybu ukazovátka v řídícím souboru.
Není-li vazba 1:n povolena, je v podřízeném souboru nastaveno ukazovátko vždy na první řádek skupiny řádků s touto hodnotou klíče.
Stejným mechanismem, tj. indexovými tabulkami a příkazem SET RELATION, se realizují vazby mezi více tabulkami dat. Nic nebrání tomu, aby tabulka, která byla jedním příkazem SET RELATION nastavena do řídící posice, byla dalším příkazem SET RELATION nastavena do pozice řízené. Tím se ovšem původní řízená tabulka na druhé úrovni přesune na úroveň třetí atd.
Dále je možno klauzuli <výraz> INTO <tabulka> v příkaze SET RELATION uvést vícekrát; v tom případě se z jednoho řídícího souboru vytváří vazby do více tabulek řízených na stejné (např. druhé) úrovni.
V tomto postupu lze pokračovat a vytvářet libovolně složité datové vazby, omezené jen technickými parametry použitého databázového systému.
Jako příklad uvažujme "řídící" tabulku VZORKY. Nechť je zapotřebí při zpracování každého řádku tabulky mít k disposici údaje o vrstvě, ze které byl vzorek odebrán, dále o vrtu, ze kterého vzorek pochází, a nakonec informace o souvrství, kam patří vrstva příslušná vzorku. Jest tedy čerpat další informace z tabulek VRSTVY, VRTY a SOUVRSTVÍ.
K vytvoření těchto vazeb lze použít např. následující sekvenci příkazů (předpokládá se existence příslušných indexových tabulek vytvořených dříve):
use SOUVRSTVÍ in 4 order IKÓD use VRTY in 3 order IKÓD use VRSTVY in 2 order IKÓD use VZORKY in 1 select VRSTVY set relation to SOUVRSTVÍ into SOUVRSTVÍ select VZORKY set relation to VRSTVA into VRSTVY, VRT into VRTY additive
Vytvoří se "propojení" ze VZORKŮ do VRTŮ a VRSTEV, a z VRSTEV do SOUVRSTVÍ. Z hlediska čerpání dat lze situaci znázornit např. takto:
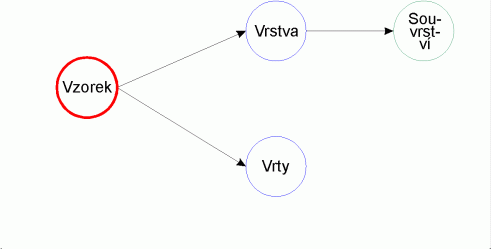
Obrázek 1: Vazby relací
Tento příklad především ukazuje oba dva typy logické hierarchické podřízenosti v případě tří (!) zdrojů dat. Jeden typ je možno nazvat "paralelní" - v této podřízenosti jsou tabulky VRTY a VRSTVY vzhledem k tabulce VZORKY. Druhý typ je možno nazvat "sériový"; v ní jsou tabulky VZORKY - VRSTVY - SOUVRSTVÍ.
Dále příklad ilustruje vytvoření invertované hierarchické struktury. Zatímco se v celé předchozí kapitole o hierarchických strukturách uvažovala jako nejvyšší úroveň SOUVRSTVÍ, jíž byla podřízena úroveň VRSTVY a té zase VZORKY, je nyní situace právě opačná (invertovaná): nejvyšší úrovní je VZORKY, jí podřízenou je VRSTVY a té zase SOUVRSTVÍ.
Popis možností, jaké má uživatel pro zpřístupnění resp. zpracování dat, bude podán na shora uvedeném příkladu tabulky VZORKY, z níž vychází vazba do tabulky VRTY.
Zpřístupnění dat uživateli ve formě tabulky provede příkaz tvaru např.
browse fields VZORKY.MÍSTO, VRTY.X, VRTY.Y
Většina systémů otevře zobrazovací tabulku v samostatném okně. Tato tabulka bude mít tolik řádků (potenciálně v okně prohlédnutelných), kolik je - v obecném případě - řádků tabulky v aktuální oblasti, popř. tabulky "řídící" vazbu.
Tabulka v okně bude mít v tomto konkrétním případě tři sloupce. První bude obsahově i kvantitativně totožný se sloupcem MÍSTO tabulky VZORKY. Každý řádek okna bude mít ve druhém sloupci hodnotu sloupce X toho řádku tabulky VRTY, na který právě ukazuje ukazovátko tabulky VRTY. Toto ukazovátko je řízeno vytvořenou vazbou; ukazuje na ten řádek VRTŮ, který má stejný kód vrtu jako daný řádek tabulky VZORKY. Je tedy pravděpodobné, že stejná hodnota souřadnice X se bude vyskytovat ve více řádcích okna (z jednoho vrtu je běžně odebráno více vzorků). Stejná situace je s třetím sloupcem okna Y.
Poznámka: Příkaz BROWSE je nesmírně silným příkazem. V definici xBase má dalších 34 volitelných klauzulí. Jako jednu z nejčastěji používaných klauzulí lze uvést klauzuli FOR <podmínka>, která zpřístupní pouze ty řádky, které splňují zadanou podmínku.
Tento mechanismus je zásadně odlišný od (zdánlivě obdobného) příkazu SELECT kategorie SQL. Příkaz SELECT sice vytvoří obdobnou tabulku se stejným obsahem, jde však o novou tabulku dat bez jakékoliv vazby na původní datové tabulky, ze kterých tato nová tabulka vznikla. Na rozdíl od toho příkaz BROWSE vytvoří pro dobu svého provádění novou logickou datovou strukturu s vazbou do míst zdroje dat. Tato struktura - protože reálně neexistuje - se nazývá virtuální datová struktura. Protože však její pole jsou reálně existující pole, změna hodnot v nich se promítne do místa, kde reálně existují.
To je nejzřetelněji patrné v této situaci: shora uvedený příklad (většinou v okně) ve sloupci X obsahuje několik stejných hodnot, protože přísluší různým vzorkům ze stejného vrtu. Nechť nyní uživatel změní v okně "jednu ze stejných" hodnot. Okamžitě se změní všechny! Je to právě proto, že nejde o "několik stejných" hodnot, ale jen o několik zobrazení téže hodnoty, čerpané z jediného místa tabulky VRTY.
Předchozí příkaz BROWSE slouží jednak k prohlížení, jednak k opravám údajů v jedné nebo více tabulkách. Pro rychlý a jednoduchý výpis informací lze použít příkaz
list VZORKY.MÍSTO, VRTY.X, VRTY.Y
který vypíše stejné informace, jaké zobrazí shora uvedené okno BROWSE. V tomto tvaru zasílá příkaz LIST výstup na standardní zobrazovací zařízení, kterým je většinou obrazovka. Příkaz ve tvaru
list VZORKY.MÍSTO, VRTY.X, VRTY.Y to print
provede totéž, ale na standardní tiskárnu. Kromě klauzule TO PRINT lze uvést klauzuli TO FILE <soubor>, pomocí které lze výpisem vytvořit textový soubor se zadaným názvem.
I velmi složité výstupní sestavy plně (předem) definované uživatelem (např. pod názvem SESTVRTŮ) zajistí příkaz např.
report form SESTVRTŮ to print
Problematika výstupních sestav však přesahuje rozsah i cíl této práce.
xBase obsahuje příkazy pro zjišťování hodnot vzniklých zpracováním skupin dat z tabulek (agregované informace). Existující, ale málo používané příkazy COUNT, SUM ap. nahrazuje jediný, silnější příkaz CALCULATE. Popsán bude opět na shora uvedeném příkladu propojených tabulek VZORKY a VRTY.
calculate cnt (), avg (HLOUBKA)
spočte počet řádků (cnt = count = počet) a průměrnou hloubku (avg = average = průměr) aktuální popř. "řídící" tabulky. Výsledek zašle na standardní výstupní zařízení, kterým je většinou obrazovka.
calculate cnt (), avg (HLOUBKA) to POČŘÁD, PRŮMHL
provede totéž, ale výsledek navíc umístí to dvou tzv. paměťových proměnných nazvaných uživatelem POČŘÁD a PRŮMHL; hodnoty umístěné do těchto proměnných je možno dále používat pod jejich názvy.
Poznámka: Kromě uvedených funkcí CNT a AVG je možno použít funkce SUM (součet), MIN (minimum), MAX (maximum) a STD (směrodatná odchylka).
calculate avg (VRTY.X) for HLOUBKA < PRŮMHL
spočte průměrnou X-ovou souřadnici těch vzorků, které byly odebrány z menší než průměrné hloubky.
Z doposud uvedeného výkladu je možno odvodit mechanický způsob transformace hierarchického modelu na soustavu relačních databází, které navíc budou v jedné z normálních forem.
Popis každého záznamu na každé úrovni hierarchické struktury se doplní o položku NADŘAZENÝ KLÍČ a - pokud již logicky neexistuje - o položku KLÍČ. Spojená položka NADŘAZENÝ KLÍČ + KLÍČ je položkou NADŘAZENÝ KLÍČ všech záznamů hierarchicky podřízených danému záznamu. NADŘAZENÝ KLÍČ záznamů první úrovně je prázdná položka. Oba uvedené klíče lze zkonstruovat vždy; nejméně to může být znakový klíč bázovaný numerickou hodnotou pořadí záznamu mezi svými "sourozenci".
Logická struktura dat každého typu segmentu doplněná o oba uvedené klíče tvoří definici samostatné tabulky dat = relační databáze. Takových databází tedy bude tolik, kolik je různých typů segmentů.
Obsahem každé relační databáze jsou datové obsahy jednotlivých segmentů hierarchické databáze doplněné o hodnoty obou klíčových polí.
Vytvořením vazeb (set relation) mezi jednotlivými tabulkami způsobem popsaným shora, kdy vazebními výrazy jsou spojené klíče dané úrovně, je k disposici datová struktura ekvivalentní původní hierarchické struktuře.
Poznámka 1: Takto vzniklý systém relačních databází je ovšem daleko mohutnějším prostředkem pro zpracování dat. Pouhou záměnou vazeb lze bez jakýchkoliv dalších pomocných konstrukcí a předzpracování dat zřídit invertované datové struktury (ve smyslu hierarchického modelu), které se právě v hierarchických databázových systémech realizují velmi obtížně.
Poznámka 2: Další předností takto transformovaných hierarchických modelů je to, že veškeré struktury jsou virtuální. Jednotlivé relační databáze existují nezávisle na sobě a složité struktury vytváří jen v případě potřeby a na dobu trvání této potřeby.
[1] DROZDOVÁ, J., HOMOLA, V.: Databáze pro geovědní obory. VŠB-TU Ostrava 2019. ISBN 978-80-248-4265-3.
Orig: 7 / 1994
Rev: 11 / 2021