VYSOKÁ ŠKOLA BÁŇSKÁ - TECHNICKÁ UNIVERZITA OSTRAVA
Tabulkový procesor Excel
Přílohy k učebním textům pro distanční vyučování
doc. Dr. Vladimír Homola, Ph.D.
Ostrava, rev. květen 2025
K ISBN 978-80-248-4145-8
© VŠB-TU Ostrava 2018-2025
Přílohy
Vlastní formát buňky s hodnotou typu Číslo
Excel nabízí poměrně široké spektrum formátů použitelných pro zobrazení aktuální hodnoty obsahu konkrétní buňky (srov.: Obsah buňky a Zobrazení obsahu buňky). Tato příloha se nezabývá předdefinovanými formáty, ale pouze tzv. Vlastními formáty (Custom formats). Základem informací v této příloze jsou originální texty Microsoftu na adrese https://support.microsoft.com (viz [3]) a případná zkoumání reakce programu Excel - to pokud měl autor této přílohy pochybnosti o správném pochopení Microsoftích sdělení (což bylo poměrně často J ).
Struktura kódu vlastního formátu
Kód vlastního číselného formátu sestává až ze čtyř sekcí (sections of code). V případě více než jedné se sekce oddělují středníkem (semicolon, „;“). Schematicky tedy v maximalistickém tvaru
S1 ; S2 ; S3 ; S4
Pokud jsou v kódu formátu uvedeny všechny čtyři sekce, použijí se ke zobrazení hodnot buněk, jsou-li po řadě
<kladné> ; <záporné> ; <nula> ; <text>
Pokud jsou v kódu formátu uvedeny tři sekce, použijí se k zobrazení hodnot, jsou-li po řadě
<kladné> ; <záporné> ; <nula>
přičemž je-li obsahem buňky text, budou zobrazeny všechny jeho znaky tak, jak byly zadány.
Pokud jsou v kódu formátu uvedeny dvě sekce, použijí se k zobrazení hodnot, jsou-li po řadě
<kladné a nula> ; <záporné>
Pokud je uvedena jen jedna sekce, použije se pro formátování jakékoliv hodnoty adekvátně formátovacím znakům uvedených v sekci.
Pokud v kódu formátu některá „vnitřní“ sekce není definována (ale jsou definovány další, např. nechceme definovat S2), pak kód formátu má tvar např.
S1 ; ; S3 ; S4
tj. následují dva středníky za sebou a mezi nimi nic (kromě případných mezer).
Poznámka: V originálních textech není explicitně uvedeno, jak bude zobrazena hodnota v případě chybějící sekce. Pokusem bylo zjištěno, že v tomto případě (chybí S2 a hodnota je záporná) není zobrazeno nic.
Sekce vlastního číselného formátu
Poznámka: V celé této kapitole je při popisu některých formátů a ukázce zobrazení hodnot použit znak "␣" ve smyslu znázornění mezery, která - jak známo - není vidět. Jde o to, aby se čtenář byl schopen dopočítat počtu mezer ve vztahu k počtům zástupných symbolů.
Dále: V příkladech zápisu ne-celočíselných hodnot je důsledně použita desetinná čárka na rozdíl od originální dokumentace, kde je použita anglosaská desetinná tečka. Toto musí mít na paměti čtenáři používající i nelokalizované Officy.
Zástupné symboly pro cifry
| Symbol | Význam | Příklad sekce | Formátovaná hodnota | Zobrazení |
| 0 (=nula) | Jedna cifra zobrazované číselné hodnoty, a to včetně počáteční nebo koncové bezvýznamné nuly | 000,00 | 12,376 | 012,38 |
| # (=hash) | Jedna cifra zobrazované číselné hodnoty; je-li na této pozici bezvýznamná nula, nebude zobrazeno nic | ##0,00 | 12,376 | 12,38 |
| ? (=otazník) | Stejný význam jako 0 (nula) ovšem s tím, že bezvýznamné nuly budou zobrazeny jako mezery; tím se docílí zarovnání číselných hodnot pod sebou do sloupce | 0,0? | 1,2 | 1,2␣ |
| . (=tečka) , (=čárka) |
Zástupný symbol pro oddělovač celé a necelé části čísla. Závisí na národním prostředí; v ČR je použita čárka |
Příklady použití:
| Kód formátu | Hodnota buňky | Zobrazení hodnoty |
| ###␣##0,0 | 1234,56 | 1␣234,6 |
| ???␣??0,0 | 1234,56 | ␣␣1␣234,6 |
| 0,0 | 0,567 | 0,6 |
| #,0 | 0,567 | ,6 |
| #,0# | 28 | 28,0 |
| #,0# | 28,567 | 28,57 |
| ???,???# | 33,333 | ␣33,333 |
| ???,???# | 333,33 | 333,33␣ |
| ???,???# | 3,3 | ␣␣3,3␣␣ |
Poznámka: Budou-li v posledních třech příkladech umístěny hodnoty v buňkách pod sebou, pak budou zobrazeny zarovnány na desetinnou čárku. V textu této přílohy toho bohužel dosáhnout nejde díky jiné typografii znaku ␣ a cifer.
Pokud má číselná hodnota více platných desetinných míst než je zástupných symbolů vpravo od desetinného oddělovače, bude na tento počet symbolů hodnota zaokrouhlena. Pokud má číselná hodnota více platných cifer celé části než je počet zástupných symbolů nalevo od desetinného oddělovače, budou zobrazeny i „přebývající“ cifry.
Zástupné symboly pro barvy
Sekce vlastního formátu může obsahovat určení barvy znaků, kterými bude obsah buňky zobrazen. V takovém případě určením barvy musí sekce začínat. Lze použít následující:
| V českém prostředí | V anglickém prostředí | Barva |
| [Červená] | [Red] | n |
| [Zelená] | [Green] | n |
| [Modrá] | [Blue] | n |
| [Azurová] | [Cyan] | n |
| [Purpurová] | [Magenta] | n |
| [Žlutá] | [Yellow] | n |
| [Bílá] | [White] | n |
Příklad použití:
| Kód formátu | Hodnota buňky | Zobrazení hodnoty |
| [Purpurová]###␣##0,0 | 1234,56 | 1␣234,6 |
Vkládání textu do kódu sekce
Kromě zástupných symbolů může sekce vlastního formátu obsahovat i posloupnosti dalších znaků (v originále nazývaných text), a to i mezi jednotlivými zástupnými symboly. Pozor, nejde o text přejímaný z obsahu nějaké buňky. Aby se předešlo kolizi s případnými shodnými znaky použitých jako zástupné symboly, musí být znaky vkládaného textu uzavřeny mezi uvozovky " a ":
| Kód formátu | Hodnota buňky | Zobrazení hodnoty |
| ##0,00" je můj příjem." | 234,56 | 234,56 je můj příjem. |
Procenta a vědecká notace (semilogaritmický tvar)
Zástupnými symboly pro percentuální formát je „%“ a pro matematický (vědecký, semilogaritmický) je „E“. Na rozdíl od tvrzení originální dokumentace nelze např. v českém Excelu 2016 použít malé „e“.
| Kód formátu | Hodnota buňky | Zobrazení hodnoty |
| ##0,00"% | 0,054 | 5.40% |
| ##0,00"% | 5,67 | 567.00% |
| 0,00E+00 | 12345678 | 1,23E+07 |
| #0,0E+0 | 12345678 | 12,3E+06 |
Sekce S4 v případě úplného kódu vlastního formátu
Jde o případ, kdy se autor sešitu připravil na situaci, že některá buňka může obsahovat někdy hodnotu typu číslo (to zpracují sekce S1, S2 a S3), někdy hodnotu typu text (a to zpracuje právě sekce S4).
Pro zobrazení celého textu, který je právě obsahem formátované buňky, je použit zástupný znak @ (= angl. „at“, česky lidově „zavináč“). Před ním i za ním mohou být vloženy vlastní autorovy texty uzavřené v uvozovkách " a " (viz výše). Pokud v této sekci není znak @ vůbec uveden, budou zobrazeny jen případné vložené autorovy texty. Pokud naopak je znak @ uveden vícekrát, bude tolikrát na těchto místech zobrazen úplný text, který je obsahem buňky (plus všechny případné autorovy texty do kódu sekce vložené).
| Kód formátu | Hodnota buňky | Zobrazení hodnoty |
| "Alfa"@"Gama" | Beta | AlfaBetaGama |
| "Alfa""Gama" | Beta | AlfaGama |
Poznámka: Na rozdíl od např. mnohých programovacích jazyků se vložení uvozovek " do vlastního autorova textu nedosáhne jejich zdvojením. Jednoznakový autorův text je možno vložit také uvedením znaku \ (= opačné lomítko), za kterým bezprostředně následuje onen jediný znak. V případě uvozovek jde tedy o uvedení dvou znaků \" bezprostředně za sebou.
Sekce vlastního formátu datumu a času
Pro zpracování kalendářního data a času používá Excel funkce, které datum a čas chápou jako číslo ve významu polohy bodu na časové ose s počátkem (samozřejmě v nule), kterému odpovídá 31/12/1899 00:00:00. Celá část čísla je tedy chápána jako pořadové číslo dne na časové ose, necelá část jako část dne s tím, že 1,00 den = 24 hod.
Funkce pro takové zpracování číselné hodnoty pak Excel používá i při zobrazování jednotlivých částí kalendářního datumu (dne, měsíce, roku) resp. času (hodin, minut, vteřin) odpovídajícím číselné hodnotě ve formátované buňce právě uložené. Používá k tomu následujících zástupných symbolů (opět uvádíme lokalizovanou verzi pro češtinu, příklad je uveden pro datum úterý 2.června 2015 7hod:8min:9sec odpovídající číslu 42157,2973263889):
| Symbol | Význam | Zobrazení hodnoty |
| d | Číslo dne na 1 nebo 2 cifry | 2 |
| dd | Číslo dne vždy na 2 cifry | 02 |
| ddd | Zkratka názvu dne | út |
| dddd | Úplný název dne | úterý |
| m | Číslo měsíce na 1 nebo 2 cifry | 6 |
| mm | Číslo měsíce vždy na 2 cifry | 06 |
| mmm | Číslo měsíce římskými číslicemi (v Cz) Tříznaková zkratka měsíce (dle dokumentace v En) |
VI |
| mmmm | Úplný název měsíce | červen |
| mmmmm | První písmeno měsíce (v Cz nesmyslné pro červen/červenec) | č |
| rr | Číslo roku ve století | 15 |
| rrrr | Úplné číslo roku | 2015 |
| h | Hodiny na 1 nebo 2 cifry | 7 |
| hh | Hodiny vždy na 2 cifry | 07 |
| m | Minuty na 1 nebo 2 cifry | 8 |
| mm | Minuty vždy na 2 cifry | 08 |
| s | Celé vteřiny na 1 nebo 2 cifry | 9 |
| ss | Celé vteřiny vždy na 2 cifry | 09 |
| ss,000 | Vteřiny vždy na 2 cifry včetně tisícin (analogicky desetiny, setiny ...) |
09,000 |
Poznámka: Oddělovačem zástupných symbolů pro den, měsíc a rok je lomítko nebo tečka, pro hodiny, minuty a vteřiny dvojtečka.
V praxi se číselná hodnota může chápat jen jako časový údaj, kde celá část vyjadřuje násobek 24 hodin (= jednoho dne). Např. let k protinožcům trvá 26 hodin = (24+2) hodin = 1 den 2 hodiny = 1,0833 dne. Pokud by bylo nutno omezit se pouze na zástupné symboly uvedené výše, pak by let trval buď 2 hodiny, nebo 1. ledna 1900 2 hod - což je podivné. Proto Excel zavádí pojem „Spotřebovaný čas“ (=Elapsed time), kdy je číselný údaj zpracováván právě s celou částí chápanou jako násobek 24 hodin a nikoliv jako pořadové číslo dne. Zobrazení v takovém chápání zajistí následující tvary časového formátu:
| Symbol | Význam | Příklad |
| [h] nebo [hh] | Spotřebovaný čas v hodinách | [h]:mm:ss |
| [m] nebo [mm] | Spotřebovaný čas v minutách | [m]:ss |
| [s] nebo [ss] | Spotřebovaný čas ve vteřinách (příklad je až na milisekundy) |
[ss],000 |
Jména, identifikátory
Jména a identifikátory obecně
Autoři projektů (sešitu, prezentace, databáze, programu) především pro svou vlastní orientaci označují části vyvíjeného nebo upravovaného projektu tak, aby jim takové označení na první pohled připomnělo význam a funkci jednotlivých částí. Ke mnemotechnickému pojmenování používají autoři (zde hlavně sešitů) konstrukci od pravěku programování nazývanou Identifikátor. Zopakujme celkem jednoduchou definici:
Identifikátor je posloupnost písmen a číslic začínající písmenem
tedy např. Alfa3, Kilometry - ale nikoliv 3Alfa (nezačíná písmenem) a nikoliv ani Den svatby (obsahuje mezeru, což není ani písmeno ani cifra).
Identifikátor se začal používat pro pojmenování nejen v programech, ale např. i ve vznikajících systémech zpracování dat, které se dopracovaly k dnešním databázím v nejrůznějším pojetí. Zpřístupněním hardware i software víceméně komukoliv se začal projevovat problém právě s identifikátory - zvláště s umožněním komukoliv definovat a plnit třebas právě nějaké datové struktury.
Zatímco Homo Computatrum (česky označovaný jako Ajťák) nevidí v zavádění a používání identifikátorů žádný problém, pak Homo Ordinarius (Člověk Běžný) si zoufá. Tento druh Homa neustále naráží hlavně na dva problémy:
- Především nechápe, proč by datum z účtenky nemohl nazvat Den nákupu, když to toho dne skutečně nakoupil. I když by nebyl sám autorem nějakého datového zdroje ale jen jeho prohlížitelem, prostě datovou položku Den nákupu tam neuvidí. Nanejvýš třeba DENNAKUPU a to je nečtivé a vůbec ošklivé.
- Zvláště v době celosvětové epidemické fyzické izolace jedinců probíhá čilá komunikace příslušnými prostředky. I když zmíněný běžný uživatel má snahu dodržet pravidla pro tvorbu identifikátoru a použije třebas Pořadí, nechápe proč s takovými zaslanými daty má jeho běžná americká přítelkyně problémy.
Protože množina běžných uživatelů je obrovská a je to tedy pro Ajťáky značný zdroj příjmů, bylo třeba běžným uživatelům vyjít vstříc.
První vstřícný krok směřoval k tomu, aby uživatel viděl označení dat pro něj rozumně čitelným způsobem. Kromě identifikace dat pomocí jména (name) byl zaveden další atribut, titulek (caption). Zatímco uživatel vidí v grafickém prostředí titulek, uvnitř je položka uložena a programově přístupná pod jménem. Pokud autor dat neurčí nějaké datové položce titulek, uvidí uživatel jméno - to musí být definováno vždy.
Zatímco pro jméno byl stále vyžadován tvar identifikátoru, titulek mohl (a může) obsahovat vcelku libovolný znakový řetězec.
Problém uvedený shora jako ad 2. vznikl doslovnou interpretací definice identifikátoru v americkém (stejně tak v německém, francouzském a jiném) národním prostředí. Angličtina má jak známo 26 písmen: a, b, ..., y, z. Taková podivnost jako je např. „r“ nad kterým je ještě „v“ - to rozhodně v Americe není písmeno.
Postupem času se striktní omezení tvaru jména na identifikátor změkčilo:
Jméno má tvar identifikátoru nebo znakového řetězce uzavřeného mezi hranaté závorky „[“ a „]“.
Zmíněný znakový řetězec může obsahovat víceméně libovolné znaky (tedy nejen písmena a cifry) s výjimkou několika málo speciálně využívaných znaků; velmi často se nepřipouští „*“ nebo „#“ - k tomu viz dokumentace daného programového systému.
Platná jména jsou tedy např. [Den nákupu], [% DPH], Kilometry, [Kilometry] (=Kilometry) nebo [Pořadí] - zde je znak s diakritikou a předejde se tedy zmíněnému problému v ne-českém prostředí. Tím se umožnilo i běžnému uživateli pojmenovávat své objekty pro něj čitelným textem a titulek to v mnoha případech učinilo zbytečným.
Poznámka: Při tvorbě identifikátoru by se měl autor seznámit s „case sensitivity“ (citlivostí na velikost písmen) používaného software. Některé programové systémy jsou citlivé na velikost písmen (X a x jsou dvě různá písmena), některé nejsou (ALFA i ALfa i alfa jsou stejné identifikátory). Excel v případě identifikátorů např. oblastí není citlivý, Vydaje i VYDAJE jsou pro něj stejné.
Pojmenování v Excelu
Shora uvedené změkčení tvaru jména není dosud platné obecně. Některé programové produkty způsob pojmenování změnily kompletně podle uvedené úpravy, někde naopak k ní nepřešli vůbec. Existují ovšem i produkty (a Excel k nim zatím patří), ve kterých lze v některých kontextech používat ono „měkčí“ pojmenování, jinde je nutno použít původní striktní definici identifikátoru.
Pojmenování svým vlastním názvem se začasté používá již při přípravě sešitu a jeho dat. Pro plynulou a bezkolizní přípravu je ideální dobře znát objektový model sešitu, což evidentně nelze požadovat od běžných uživatelů. Proto v dalším textu bude na vyžadovaný nebo povolený tvar vlastního pojmenování explicitně upozorněno.
Pro představu: Jako jméno tabulky (obecně oblasti) musí být použit identifikátor, zatímco jména sloupců nemusí tento striktní požadavek splňovat.
Poznámka: Další informace (spec. pro Excel - Tables) viz v samostatném odstavci níže.
Prefix identifikátoru
Pro ty autory - zvláště složitějších - sešitů, kteří hodlají používat své vlastní identifikátory, je vhodné uvést doporučení Microsoftu:
Poznámka: Doporučení, jak známo, nejsou závazná.
Často při koncipování sešitu autor navrhuje několik jeho komponent odlišného typu, které však z hlediska řešené problematiky spadají do stejné logické oblasti - např. list ZAMĚSTNANCI, tabulka ZAMĚSTNANCI, graf ZAMĚSTNANCI atd. Aby se autor vyhnul kolizi v případě duplicitních identifikátoru (i když by nemusela nastat), doporučuje se jako první jeden až tři znaky identifikátoru (tzv. prefix) zvolit písmena mnemotechnicky vyjadřující typ pojmenovávaného objektu. Konec konců i pro autora samotného je výhodné, když se po delší době k sešitu vrátí, že mu prefix připomene kontext použití daného objektu. Např.
- lsZAMĚSTNANCI ... pro list zaměstnanců,
- dtZAMĚSTNANCI ... pro data zaměstnanců,
- tbZAMĚSTNANCI ... pro tabulku zaměstnanců,
- grZAMĚSTNANCI ... pro graf zaměstnanců.
Počet písmen prefixu i písmena samotná volí autor podle svého uvážení a vůbec nemusí korespondovat s pojmenovávaným objektem.
Znovu podotýkáme, že jde pouze a jen o doporučení. Na některých místech je však v tomto článku i doprovodném sešitu použito - tak aby čtenář věděl, že nejde o překlepy J
Tabulky databáze obecně a v programu Excel
Excel sám je chápán jako tabulkový procesor, tedy program zpracovávající data pojímaná jako tabulka - ovšem v původním pojetí označovaném jako Spreadsheet. Běžný uživatel si tedy pod pojmem Tabulka představí list mající R řádků x S sloupců, kde S a R jsou rozměry listu. Zde dochází k nepochopitelnému zmatení pojmů autory Excelu, kdy původně celkem příhodně nazvaný Seznam (= List, List Of Records) zcela nevhodně přejmenovali na Tabulku, tedy pojmu používanému v nejrůznějších kontextech. Aby to uhodilo (podle jejich mínění) do očí, zavedli pojem Tabulka Excelu. Pilný pronikatel do tajů Excelu teď tedy musí pečlivě rozlišovat mezi Tabulkou a Tabulkou Excelu. A záleží na jeho erudici, zda se mu to v reálném čase podaří.
Tabulka relační databáze
Poznámka: V tomto odstavci vůbec nejde o význam dat, ale pouze o jejich formální uspořádání. Pokud by se však nad nimi chtěl čtenář zamýšlet, autoři doufají, že zvolili příklad názorný, i když zvláště z hlediska hodnot ve druhém sloupci - v dlouhodobém kontextu hodnot sloupce prvního - smutný.
Ačkoliv je celá myšlenka relačních databází založená na matematickém aparátu známého z teorie množin, relačních operací a dalších, pro potřeby běžného uživatele postačí náhled na element uspořádání dat (což je ona relace) jako na zdánlivě jednoduchou a běžnou tabulku, např. nějakého seznamu svých výdajů:
| DATUM | KC | CO | MNOZSTVI | JEDNOTKA | DRUH | OBCHOD | JEDCENA |
| 05.01.2021 | 15,00 | Chléb normální | 0,600 | kg | CH | D | |
| 05.01.2021 | 19,00 | Rohlíky | 10,000 | ks | CH | D | |
| 05.01.2021 | 41,00 | Máslo | 0,250 | kg | TU | D | |
| 05.01.2021 | 50,00 | Kapučíno | 0,143 | kg | KA | D | |
| 06.01.2021 | 129,00 | Bohemia Brut | 0,750 | l | AL | A | |
| 06.01.2021 | 11,40 | Rohlíky | 6,000 | ks | CH | A | |
| 06.01.2021 | 16,40 | Rajčata | 0,222 | kg | ZE | A | |
| 07.01.2021 | 9,00 | Řezy z matjesa | 0,040 | kg | RD | D | |
| 07.01.2021 | 33,80 | Hermelín | 0,120 | kg | ML | D | |
| ... | ... | ... | ... | ... | ... | ... |
Ona jednoduchost má však svá omezení a uživatel z nich obecně při přípravě dat nesmí vybočit:
- Naprosto zásadní je to, že typ dat je v databázových tabulkách vázán na celý sloupec, nikoliv na jednotlivé buňky. Je-li tedy typ sloupce číselný, musí být hodnota v každé buňce tohoto sloupce typu číslo. Typ sloupce určuje autor tabulky výběrem z množiny nabízených datových typů a tomu přizpůsobuje hodnoty dat.
- Každý sloupec databázové tabulky musí být jednoznačně pojmenován. Při databázovém přístupu jsou pak data tabulky přístupná pod jménem sloupce, ve kterém se nachází. Tato jména volí autor tabulky podle konvencí pro syntaxi jmen.
- Stejně tak v databázích (které obecně mají více tabulek dat) musí být každá z tabulek jednoznačně pojmenována. Stejně jako jména sloupců volí autor databáze jména tabulek podle konvencí pro syntaxi jmen.
- Při zpracování dat tabulky se vždy zpracovává jen jediný řádek dat (tzv. aktuální řádek). Uvedením jména sloupce je pak zpřístupněna jediná hodnota, a to z příslušného sloupce aktuálního řádku. Při zpracování tabulky je samozřejmě možno požadovat opakované zpracování dalšího a dalšího řádku, případně ve stanoveném pořadí, případně dle stanoveného výběru.
Tabulka relační databáze jako Tabulka Excelu
Autoři Excelu po delší době začali řešit absenci databázových nástrojů pro data v listech sešitu, které autor sešitu uspořádá dle výše uvedených pravidel. Ta jsou však poměrně striktní, proto Excel akceptuje jisté odchylky:
- V několika málo situacích dovede vyřešit nehomogenitu datových typů ve sloupci - např. když se do číselného sloupce připlete text.
- Pojmenování sloupců autor tabulky provede tak, že do řádku bezprostředně předcházejícího prvnímu řádku dat zapíše jména sloupců jako hodnoty typu text. Tento řádek se v takovém případě nepočítá k datům tabulky. Jména sloupců nemusí mít tvar identifikátoru (viz výše).
- Pokud autor tabulky nevyužije předchozího pravidla, použije Excel jako jméno sloupce tabulky dat písmenné označení svého sloupce - přesněji sloupce daného listu sešitu, nebo sám vygeneruje identifikátory typu „Sloupec4“ (pro sloupec D).
- Data tabulky (včetně případného řádku nadpisu) však musí být v listu umístěna tak, aby Excel poznal, ve které obdélníkové oblasti listu se data nachází - viz hned následující text.
Pokud uživatel připraví data právě uvedeným způsobem a vybere (označí) alespoň jednu buňku takového obdélníkového uskupení dat, Excel sám je schopen rozpoznat celou tabulku za předpokladu, že vlevo a vpravo je alespoň jeden volný sloupec (nebo jsou data zapsána od sloupce A) a že nad i pod je alespoň jeden volný řádek (nebo jsou data zapsána hned od prvního řádku listu). Stačí tedy jako aktuální buňku učinit kteroukoliv buňku oblasti, a následné činnosti týkající se databázového zpracování budou probíhat v takto rozpoznané oblasti. Výběr (označení) "ručně" lze provést také klávesová zkratka Ctrl/A. Toto platí obecně, je to však málo.
Data připravená podle předchozího odstavce sice splňují požadavky pro databázové zpracování, ovšem zvláště při periodickém přidávání řádků v reálném provozu jen toto je nedostačující. Vždyť pro následné zpracování takových dat bývají připravené vzorce, navazující (např. kontingenční) tabulky, grafy apod. Při změně oblasti dat by se všechny tyto objekty musely minimálně přeadresovávat nebo často nově polohovat.
Dále: uživatel už jen pro prostou kontrolu potřebuje na připravovaná data nazírat různým způsobem - např. je vhodně řadit nebo na chvíli nějak odfiltrovat. Takových obvyklých požadavků je řada a skutečné databázové programy je svým uživatelům nabízí automaticky.
Autoři Excelu se dopracovali k objektové třídě, kterou nazvali shora kritizovaným pojmem Tabulka. Autor sešitu vytvoří instanci této třídy (tj. funkční tabulku v pojetí Excelu) z jediné (!) obdélníkové oblasti, ve které předem připravil svá data podle pravidel uvedených shora. Poté aktivuje posloupností
Vložení / Tabulky / Tabulka
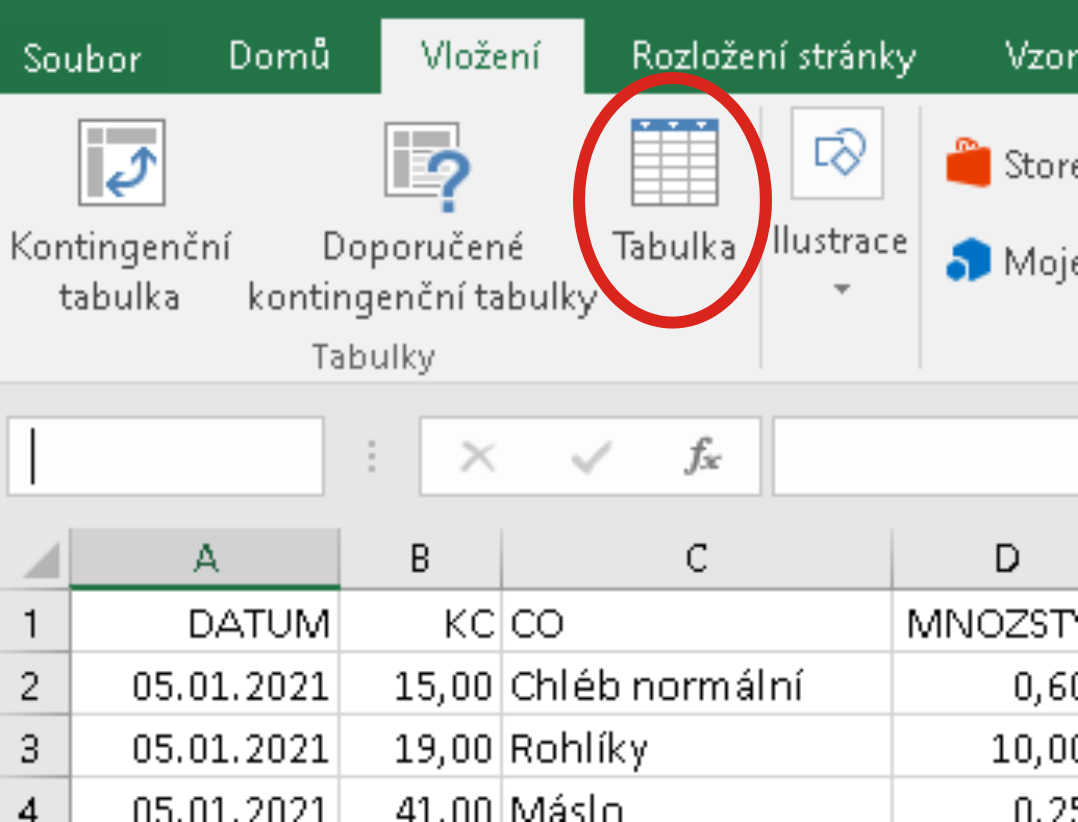
Následuje dotaz na oblast s daty a informaci, a zda má první řádek považovat za řádek s nadpisy sloupců (a důrazně se doporučuje připravit své nadpisy):
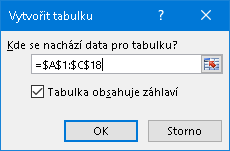
Výsledkem bude v zadaném umístění vytvořená Excelem pojmenovaná oblast opatřená v prvním řádku rozvíjecími seznamy (combo box) s nabídkami pro řazení, filtrování a vyhledávání. Oblast bude většinou divoce strakatě naformátována, což se dá zrušit běžným postupem
Nástroje tabulky / Návrh / Styly tabulky /
 / Vymazat
/ Vymazat
Důležitější je však vlastní pojmenování tabulky, které musí mít tvar identifikátoru. Excel při jejím pojmenování generuje nekolidující identifikátor (většinou tvaru např. Tabulka24), který každý soudný uživatel bezprostředně po vytvoření změní postupem
Nástroje tabulky / Návrh / Vlastnosti / Název tabulky:
a tam vepíše svůj vlastní identifikátor (klidně třeba ABCD - ovšem s rizikem, že si za měsíc už vůbec nevzpomene, která že data takhle pojmenoval):
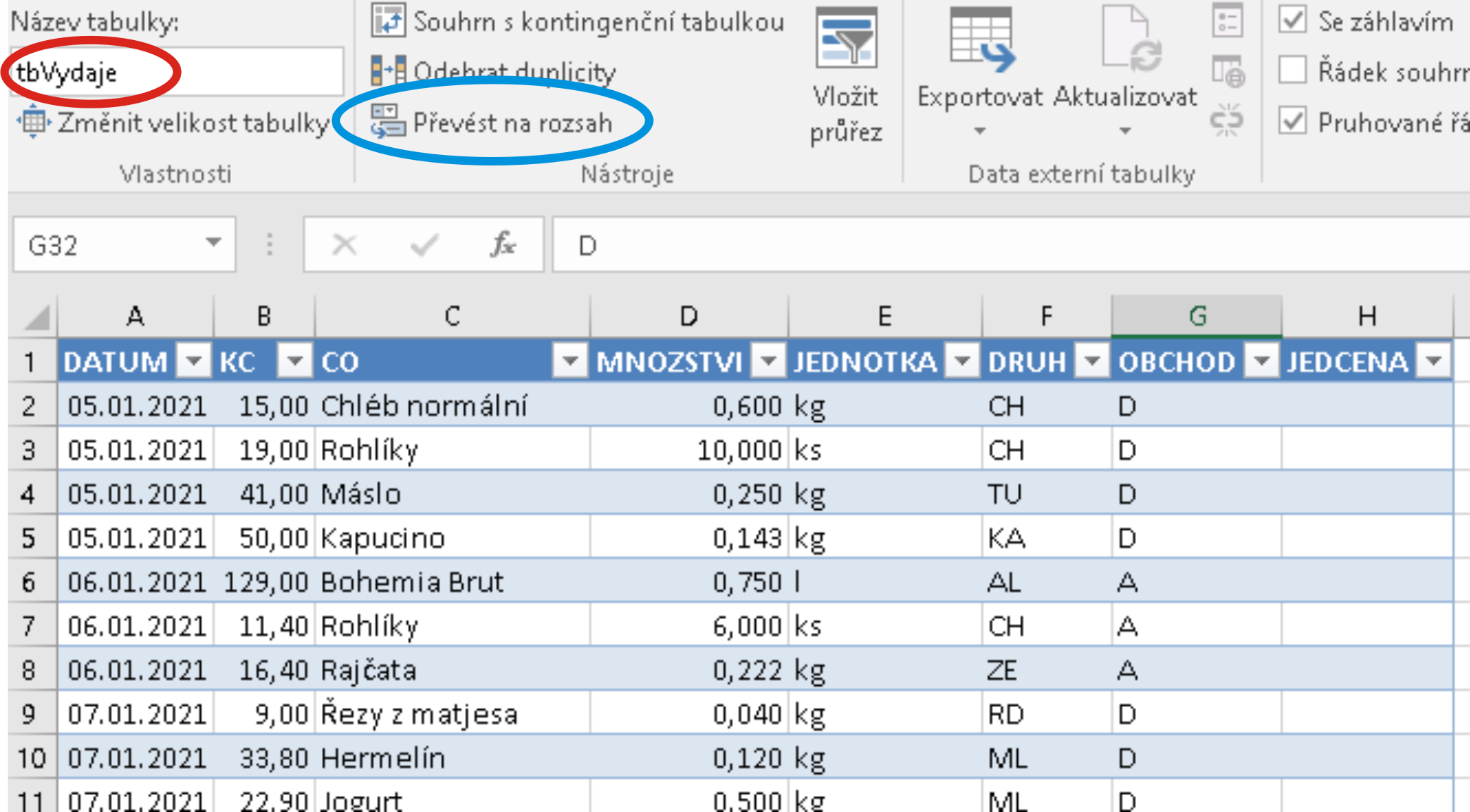
Na hořejším obrázku je rovněž (modře) vyznačeno tlačítko, kterým lze případně později oblast prohlášenou za tabulku Excelu převést zpět na "normální" data.
Kromě nástrojů pro řazení a filtrování však takto vytvořená oblast disponuje doposud chybějící vlastností: pokud uživatel začne zapisovat bezprostředně za poslední řádek dat, pojmenovaná oblast se automaticky rozšíří směrem dolu o jeden řádek - přesněji o jednořádkový blok vedle sebe stojících buněk v počtu rovném šířce tabulky.
Některé nástroje pro tabulky Excelu
Filtrování a řazení
Po převodu obdélníkové oblasti na tabulku Excelu je implicitně aktivována možnost filtrování a řazení, i pro „normální“ data dostupná pomocí
Data / Seřadit a filtrovat / Filtr
Projeví se zobrazením tlačítek  rozvíjecích
seznamů v řádku nadpisů sloupců. Seznamy obsahují stejné nabídky
se stejnými možnostmi jako pro data nepřevedená na tabulku Excelu.
Stejně tak lze tlačítkem
Filtr na kartě
Seřadit a
filtrovat zobrazení rozvíjecích tlačítek vypnout resp. znovu zapnout.
rozvíjecích
seznamů v řádku nadpisů sloupců. Seznamy obsahují stejné nabídky
se stejnými možnostmi jako pro data nepřevedená na tabulku Excelu.
Stejně tak lze tlačítkem
Filtr na kartě
Seřadit a
filtrovat zobrazení rozvíjecích tlačítek vypnout resp. znovu zapnout.
Poznámka: Pro označení řádku s nadpisy sloupců tabulky Excelu zvolili autoři termín Headers.
Stejně jako pro „normální“ data pracuje nástroj pro obecné řazení
Data / Seřadit a filtrovat / Seřadit
Ve formuláři pro nastavení kritérií řazení se však vždy nabízí názvy sloupců (tedy už není možnost volit písmeno sloupce listu), protože tabulky Excelu vždy obsahují záhlaví tabulky s názvy sloupců (ať explicitně určené autorem tabulky nebo implicitně vytvořené Excelem.
Novější verze MS Office nabízí pro filtrování vztažené k Tabulkám Excelu a Kontingenčním Tabulkám další nástroj - Slicers, v českých lokalizacích překládán jako Průřezy. Informace o tomto nástroji je poměrně obsáhlá a je uvedena jako samostatná pod-kapitola níže.
Agregační funkce v řádku souhrnů (Totals)
Stejně jako mnohé databázové programy umožňuje Excel pod posledním řádkem dat tabulky Excelu zapínat a vypínat zobrazení řádku, do jehož jednotlivých buněk má autor dat možnost umísťovat vzorce obsahující především tzv. agregační funkce (součet, počet, průměr a další). Provede to postupem
Nástroje tabulky / Návrh / Možnosti stylů tabulek / Řádek souhrnů
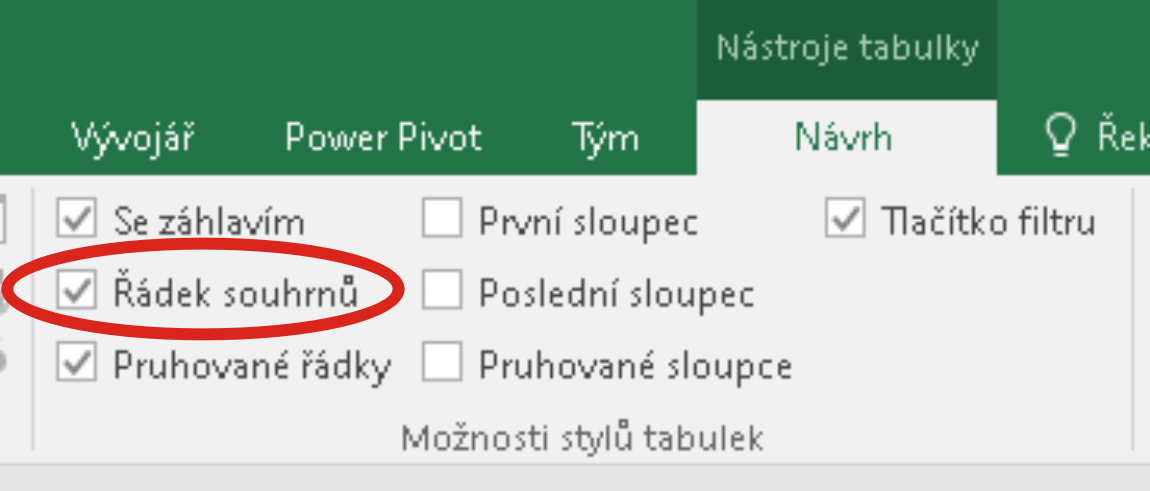
Vložený řádek souhrnů posune všechna data pod tabulkou (v šířce rovné šířce tabulky) o jeden řádek dolů. Aktivací některé buňky tohoto řádku bude zobrazena nabídka předvolených agregačních funkcí pracujícími nad všemi daty aktuálního sloupce tabulky:
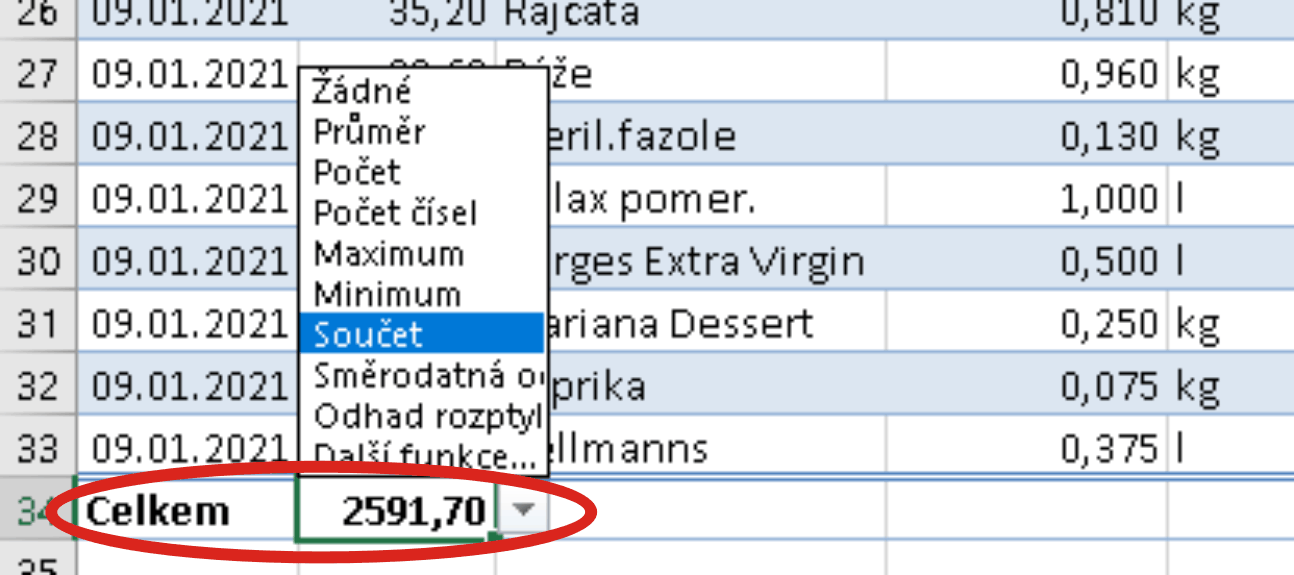
Pod první sloupec se v řádku souhrnů standardně umístí text Celkem, který lze jednak přepsat jiným textem, jednak lze do této buňky namísto textu umístit vzorec s agregační funkcí.
Filtrování pomocí průřezů (Slicers)
Excel ve vyšších verzích Office rozšiřuje možnost filtrování dat v Tabulkách Excelu (Excel Tables), v Kontingenčních tabulkách (Pivot Tables), a v datových zdrojích dostupných buď pomocí připojení, nebo pomocí datového modelu.
Z důvodu zaměření této publikace budou popsány jen průřezy filtrující data Tabulek Excelu a Kontingenčních tabulek aktivního sešitu. Z hlediska uživatele jde o grafický nástroj s řadou tlačítek připojený ke zdroji dat, kterým je tedy jeden ze dvou uvedených typů tabulek. Následující příklad ukazuje použití dvou průřezů připojených ke stejné Tabulce Excelu:
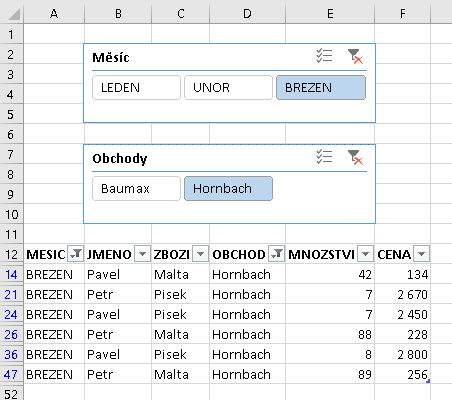
Příklad dvou různých průřezů připojených ke stejnému zdroji
V uvedeném příkladu filtruje první průřez měsíc Březen (vybrány jsou jen březnová data), druhý průřez filtruje obchod Hornbach (vybrána jsou jen data Hornbachu). Pokud jsou různé průřezy připojeny ke stejnému zdroji dat, jsou filtry jako logické podmínky vázány operací "a současně". Uvedený příklad tedy vybírá data z března a současně z Hornbachu (kostrbatě matematicky) = březnová data z Hornbachu (uhlazeně třeba pro moji babičku J).
Vytvoření pro tabulku Excelu
Základem jsou "normální" data, ovšem zaznamenaná podle pravidel relační databáze (viz) - tedy obdélníková oblast tvořená několika sloupci s nadpisy a daty v každém sloupci stejného typu. Formátování písma je irelevantní, stejně tak např. ohraničení buněk, jejich výplň a jiné. Oblast může být pojmenována (zde dtStaveb):
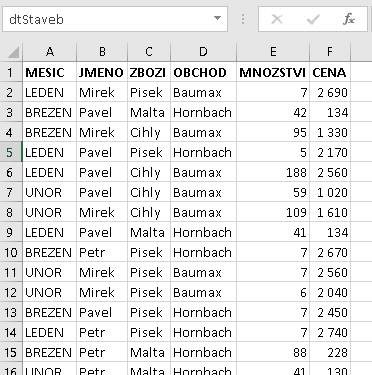
Výchozí data připravená pro převod na Tabulku Excelu
Postupem uvedeným shora se data převedou na Tabulku Excelu. Doporučuje se ji hned pojmenovat (zde tbStaveb) - toto pojmenování tabulky (Table) nemá žádný vztah k pojmenování oblasti v listu s daty (Range):
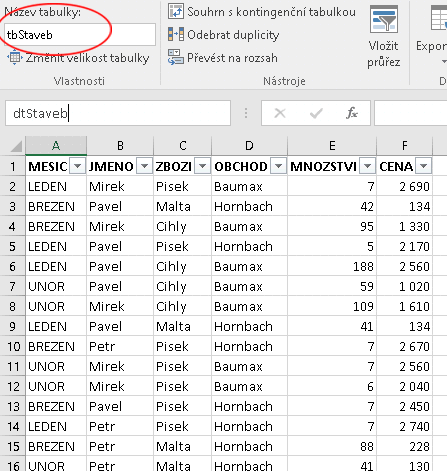
Data převedená na Tabulku Excelu
Další krok již směřuje k vlastnímu vytvoření jednoho nebo více průřezů. Excel je vytváří pro ten datový zdroj (zde Tabulka Excelu), v němž se nachází aktivní buňka nebo oblast (Selected Range). Je tedy zapotřebí nejprve aktivovat alespoň jednu buňku uvnitř příslušného datového zdroje a zadat posloupnost příkazů
Vložení / Filtry / Průřez
nebo
Nástroje tabulky / Návrh / Nástroje / Vložit průřez
Příkaz pro vložení průřezu
Pomocí následně předloženého formuláře se sdělí, pro které sloupce jsou požadovány průřezy:
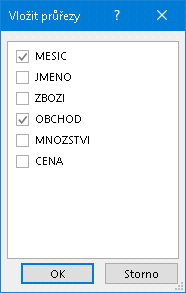
Volba průřezů a jejich propojení na sloupce zdroje
Po volbě OK vytvoří Excel příslušný počet průřezů v implicitní poloze s implicitním nastavením. Příklad vytvořeného průřezu pro data sloupce MESIC:

Implicitně navržený tvar průřezu
Průřezy je možno ihned začít používat. Následující text se bude zabývat jen jedním průřezem, pro ostatní je postup adekvátní.
Použití průřezů pro Tabulku Excelu
Průřez jako grafický ovládací prvek je vázaný na konkrétní list, ale nikoliv na buňku v něm. Uvedeným postupem ho Excel vloží na list se zdrojovými daty. Vytvořený průřez lze přemístit na jiný list běžnou operací Vyjmout (Cut) + Vložit (Paste).
Průřez jako ovládací prvek může být v režimu "Připraven k použití" nebo režimu "Vybrán pro editaci". Výběr pro editaci se provede nejjednodušeji myší obvyklým l-click kamkoliv dovnitř volné plochy (nikoliv na tlačítka s popisem hodnot sloupce). Vizuálně je výběr pro editaci znázorněn orámováním obdélníkem, v jehož rozích a středech stran jsou zobrazeny úchyty pro tažení:
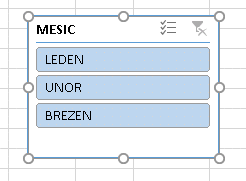
Průřez vybraný pro editaci
Příprava k použití (tj. zrušení režimu editace) se provede rovněž obvyklou aktivací nějaké - nejlépe prázdné - buňky listu.
Je-li průřez vybrán pro editaci, je hlavní menu doplněno o položku
Nástroje průřezu / Možnosti
jejíž aktivací je získán přístup k nastavení řady vlastností. Nejdůležitější jsou karty
- Průřez,
- Tlačítka,
- Velikost
pro zadání vlastního titulku (Caption), počtu sloupců tlačítek, jejich výšku a šířku, a výšku a šířku celého průřezu. Milovníci barviček se pomocí tohoto pásu karet mohou barevně vyřádit a dovést průřez k úžasné strakatosti.
Nastavení průřezu a jeho vlastností lze také pomocí r-click dovnitř volné plochy průřezu, a z předloženého kontextového menu zvolit jednu ze dvou posledních nabídek:
- Velikost a vlastnosti ...
- Nastavení průřezu ...
Po volbě nabídky Velikost a vlastnosti jest uživateli ukotven na pravou stranu panel Formát průřezu:
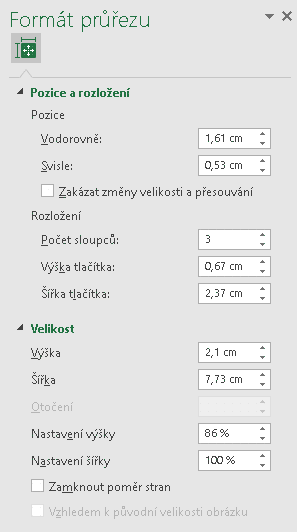
Formulář pro grafické nastavení průřezu
Jednotlivá pole jsou vcelku pochopitelná, jen k pozici: počátek [0,0] je v levém horním roku buňky A1, osa X směřuje vpravo, osa Y dolů. Pozici lze rovněž přibližně nastavit přemístěním celého průřezu tažením. Velikost výšky a šířky celého průřezu lze přibližně nastavit také tažením za úchyty průřezu vybraného k editaci.
Počet sloupců a výšku tlačítka (resp. všech tlačítek stejně) je nutno zadat „ručně“, šířka tlačítka (resp. všech tlačítek stejně) se pak automaticky přizpůsobuje šířce celého průřezu. Rovněž jsou svázány položky velikosti (výška a šířka celého průřezu) v délkových jednotkách a v procentech.
Po volbě nabídky Nastavení průřezu jest uživateli předložen formulář Nastavení průřezu:
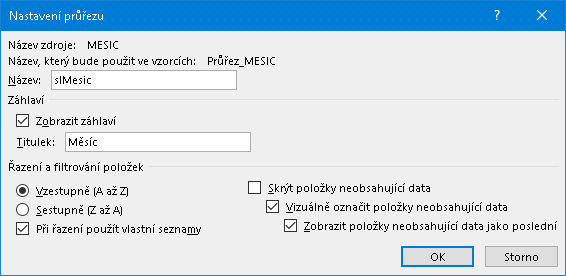
Formulář pro nastavení průřezu
Název zdroje (Source Name - zde MESIC) v prvním řádku informuje o jménu sloupce, ke kterému je průřez připojen. Jde o vlastnost objektové třídy SlicerCache (přesněji o klíč do kolekce SlicerCaches), který generuje automaticky Excel. Vlastnost je ReadOnly a tedy nelze měnit (ani programově). Při požadavku na změnu připojení je nutno odstranit celý průřez a vytvořit nový.
Datové pole Název obsahuje identifikátor, pod kterým bude průřez dostupný jako grafický objekt. Týká se především programového přístupu, běžný uživatel Excelu ho snad ani nevyužije. Jde o klíč do kolekce Shapes listu a současně do kolekce Slicers instance SlicerCache.
Poslední část formuláře „Řazení a filtrování položek“ se týká tlačítek (Slicer Items) resp. textových popisků v nich. Excel nejprve interně generuje množinu všech různých hodnot z připojeného datového sloupce. Průřez pak bude mít tolik tlačítek, kolik je těchto různých hodnot (ne všechna tlačítka však musí být zobrazena). Popisek každého tlačítka je jedna z generovaných různých hodnot.
V této třetí části formuláři lze ovlivnit pořadí zobrazených tlačítek podle jejich popisků. Pokud není zaškrtnuta volba „Při řazení použít vlastní seznamy“, pak se uplatní řazení podle hodnoty; pokud se do číselného sloupce připletou textové hodnoty, jsou tato tlačítka za všemi číselnými „dle abecedy“. V tom případě je význam voleb „Vzestupně“ a „Sestupně“ zřejmý.
Pokud však volba „Při řazení použít vlastní seznamy“ zaškrtnuta je, pak záleží na tom, zda a jak má uživatel ve své instalaci Excelu naplněn svůj vlastní seznam - viz nastavení
Soubor / Možnosti / Upřesnit / Obecné / Upravit vlastní seznamy
- Pokud některé jedinečné hodnoty jsou obsaženy v některém připraveném vlastním seznamu, použije se pořadí v tomto seznamu, jedinečné hodnoty dat neobsažené v tomto seznamu budou uvedeny jako poslední v pořadí dle svých hodnot.
- Pokud se žádný takový seznam nenajde, použije se pořadí dle jedinečných hodnot dat.
V případě použití hodnot z vlastního seznamu se řadí skutečně podle pořadí v tomto seznamu, volby řazení (vzestupně a sestupně) se vztahují k tomuto pořadí, nikoliv k hodnotám dat.
Nyní drobné poznámky pro používání průřezu.
Datová tlačítka (Slicer Items) v průřezu mají různou barvu. V tomto textu je ponecháno barevné provedení tak, jak ho implicitně při vytvoření generuje Excel (uživatel má možnost barvičky posléze změnit). V případě průřezů nejsou barvy tlačítek samoúčelné. Barva tlačítka je totiž přiřazena podle stavu filtru dle této hodnoty a mění se při změně tohoto stavu. Pro uživatele jsou asi nejpodstatnější dva stavy:
- Filtr pro tuto hodnotu je vybrán (zpracují se řádky s touto hodnotou dat v daném sloupci) - implicitně barva bleděmodrá <.
- Filtr pro tuto hodnotu není vybrán (řádky s touto hodnotou dat v daném sloupci nejsou zpracovány) - implicitně barva bílá o.
V pravém horním rohu průřezu jsou umístěna dvě tlačítka:
Nástroje v pravém horním rohu
Zcela vpravo je tlačítko pro odstranění filtru pro toto datové pole; po jeho stisknutí tedy budou opět zpracovány všechny hodnoty tohoto pole.
Vlevo od něj je aretační tlačítko, jehož nápověda (Tooltip) říká: Vícenásobný výběr (Alt-S). I jen trochu zběhlý uživatel grafického uživatelského prostředí (GUI) ví, že „vybrat“ více položek myší najednou lze pomocí Ctrl/l-Click - a to funguje i u průřezů, tak načpak tohle tlačítko pro vícenásobný výběr, že. Autor tohoto článku se domnívá, že je to určeno těm, kteří pro ovládání mají k disposici nanejvýš jednu ruku (protože ve druhé drží pohárek se vzpružujícím nápojem, např. s kávou). Přesně tlačítko funguje takto:
- Není-li ve stavu „stisknuto“ (tj. stav po vytvoření průřezu), pak nutno vícenásobný výběr provést skutečně s klávesou Ctrl - tedy jedna ruka klávesnice, jedna ruka myš. Dokud není uvolněna klávesa Ctrl, pak click myší na tutéž položku opakovaně označuje, odznačuje, označuje ...
- Je-li ve stavu „stisknuto“ (tj. aretovaný stav), pak pouhý click myší mění stav: označené odznačuje, neoznačené označuje - a stačí jedna ruka J.
Jak již bylo zmíněno v úvodu této kapitoly, vícenásobný výběr definuje logickou operaci „nebo“. Následující filtr
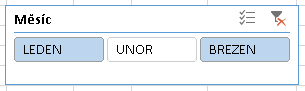
Filtr ve významu NEBO
tedy podle definice matematické operace vybírá jen ty řádky, kde hodnota v buňce sloupce MĚSÍC je rovna LEDEN nebo BŘEZEN (nebo OBOJÍ - což však v jedné buňce Excelu současně být nemůže).
Použití průřezů pro kontingenční tabulky (Pivot Tables)
Pro vytvoření a připojení průřezu k jedné kontingenční tabulce je postup shodný jako pro připojení k Tabulce Excelu (viz shora): Aktivovat jednu nebo více buněk kontingenční tabulky, vykonat posloupnost příkazů
Vložení / Filtry / Průřez
nebo
Nástroje kont. tabulky / Analýza / Filtr / Vložit průřez
a upravit vlastností a vzhled průřezu.
Na rozdíl od Tabulek Excelu však lze jeden nebo více průřezů připojit k více kontingenčním tabulkám (tj. aktivací položek jednoho průřezu budou filtrována data současně ve více kontingenčních tabulkách).
Důležitá podmínka: Má-li jeden (nebo více) průřezů fungovat pro více kontingenčních tabulek, musí všechny tyto kontingenční tabulky čerpat data ze stejného datového zdroje!
Pro ukázku mějme jako datový zdroj stejnou Tabulku Excelu jako shora (tj. pro účely výuky tabulku pojmenovanou tbStaveb).
Poznámka: Na rozdíl od průřezů pro Tabulky Excelu může být zdrojem pro kontingenční tabulky jakákoliv oblast, která by měla splňovat podmínky pro tabulky relační databáze (to pro případ maximálního využití síly tohoto nástroje).
Vytvořme první kontingenční tabulku, nezdržujme se formátováním jednotlivých buněk. Pojmenujme ji nápaditě třebas ktStavebMZ (jako Kontingenční tabulka Stavebnin pro Měsíce versus Zboží):
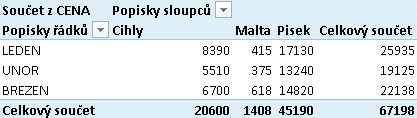
Kontingenční tabulka MĚSÍC x ZBOŽÍ
Vytvořme druhou kontingenční tabulku ze stejného zdroje, tu pojmenujme třebas ktStavebOJ (jako Kontingenční tabulka Stavebnin pro Obchody versus Jména):
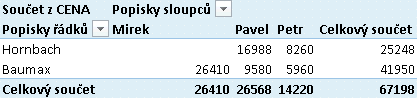
Kontingenční tabulka OBCHOD x JMÉNO
Vytvořme nyní pro první kontingenční tabulku průřezy pro datová pole MESIC a OBCHOD (stejné jako pro Tabulku Excelu shora). Průřezy lze hned vyzkoušet a sledovat vliv na první kontingenční tabulku.
Přiřazení stejných průřezů (všech nebo jen některých) druhé kontingenční tabulce zajistí po aktivaci některé buňky druhé kontingenční tabulky posloupnost příkazů
Nástroje kont. tabulky / Analýza / Filtr / Připojení filtru
mající za následek předložení formuláře
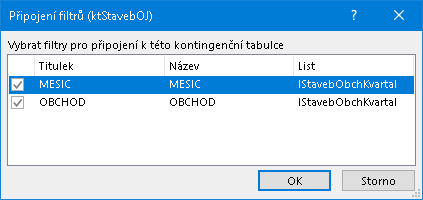
Formulář pro připojení existujících průřezů
ve kterém se zvolí, které logicky přípustné existující průřezy se mají k této kontingenční tabulce rovněž připojit.
Aktivace jednoho nebo více tlačítek v jednom nebo více z průřezů pak mají vliv na data zpracovávaná všemi kontingenčními tabulkami, které tyto průřezy mají připojeny.
Automatická úprava vzorců
V tabulce tbVydaje vytvořené ve cvičném sešitu je připraven sloupec tabulky JEDCENA (= část sloupce H listu) pro vypočítávané hodnoty jednotkové ceny, zatím s prázdnými buňkami dat. Jednotková cena je rovna podílu zaplacené ceny (data ve sloupci B = KC) a množství (data ve sloupci D = MNOZSTVI). Jednotkovou cenu pro první řádek dat (= 2. řádek listu) tedy spočte vzorec zadaný do buňky H2:
= B2 / D2
Bezprostředně po umístění tohoto vzorce do buňky H2 Excel vzorec zkopíruje do ostatních buněk tohoto sloupce tabulky (nahoru i dolů) a automaticky upraví (automatically adjusts) adresy operandů pro každý řádek. Pokud v cílových buňkách už byl nějaký obsah, bude přepsán - jinak řečeno nebylo-li tam nic, budou tam vzorce vytvořeny.
Odkazy na data tabulky Excelu (Excel Table Data)
Poznámka: Praktické postupy jsou v této kapitole demonstrovány na datech listu lVydaje cvičného sešitu uvedeného v úvodu. Dále se v této kapitole rovněž předpokládá vytvořená tabulka tbVydaje podle předchozího odstavce.
Z nejrůznějších (většinou subjektivních) důvodů je mnoha uživateli požadováno od programu Excel něco, k čemu vůbec nebyl určen a k čemu se naprosto nehodí - totiž suplování databázových programů. Aby alespoň částečně takovým uživatelům autoři Excelu vyhověli, rozšířili kdysi nejprve množinu funkcí (!), a to ne vždy šťastným způsobem - viz např. funkce SVYHLEDAT a podobné. Poté, pro umožnění alespoň trochu inteligentního vkládání dat do pojmenované oblasti, zavedli mechanizmus tzv. seznamu, nyní nazývaného tabulka (viz předchozí kapitola).
V novější verzi programu Excel se jeho autoři také pokusili řešit jeden ze základních nástrojů relačních databází, a to logické vazby mezi tabulkami známými z databázové terminologie jako relace (z angl. relationship, vztah, zkráceně relation; nezaměňovat ovšem s matematickým pojmem stejného znění!). Tomu je věnována jedna z následujících kapitol.
Data listu lVydaje cvičného sešitu simulují reálný provoz nějaké pečlivé domácnosti. Data jsou záznamem skutečnosti, kdy a za kolik se čeho nakoupilo. Dále pro pozdější generování informací tam je i údaj, ve kterém obchodě to bylo (pro informaci, jak ve kterém obchodě je to či ono drahé). A také údaj o druhu zboží (informace, jakého druhu kupujeme nejvíc: pokud zeleniny a ovoce, budem zdraví jak řípa).
Na rozdíl od předchozích odstavců už tedy začíná nabývat na důležitosti i význam dat. Analýza struktury tabulky však překračuje záměr tohoto článku; pro zájemce viz literatura [2]. Zde jediná připomínka pro konstrukci demonstrační tabulky v Excelu: Jistě nás bude zajímat jednotková cena. I když ta je dnes uvedena na každém paragonu z pokladny, určitě ji z paragonu nebudeme ručně opisovat do sešitu resp. listu resp. sloupce. Od toho má Excel možnost zadávat nejen vlastní data, ale i vzorce s daty pracujícími (zde vydělit cenu množstvím). Musí být ale kam ty vzorce zadávat. Připravíme proto v tabulce pro jednotkovou cenu zatím prázdný sloupec, ovšem s vyplněným nadpisem.
Explicitní odkazy
Motivační otázka: máme-li data v tabulce tbVydaje, kolik jsme utratili celkem? Jaké byly jednotkové ceny?
Pro celkové výdaje je zapotřebí sečíst čísla ve sloupci B počínaje řádkem 2 a konče řádkem 33 (na hořejším obrázku není vidět, že zrovna ten je poslední). To vyřeší i začátečníkům známý vzorec (používáme identifikátory „počeštěných“ funkcí) zapsaný kdekoliv do prázdné buňky mimo oblast dat:
= Suma ( B2 : B33 )
Pokud je třeba zjistit výdaje jen počínaje desátou položkou, jde o vzorec
= Suma ( B11 : B33 )
Pro jednotkové ceny stačí do buňky H2 vložit vzorec
= B2 / D2
a roz-kopírovat ho dolů podél všech řádků dat.
Odkazy na buňky s daty v předchozích vzorcích jsou označovány jako explicitní odkazy (výslovné, přímé, přímo vyjádřené) a to bez ohledu na to zda, zda obsahují nebo neobsahují písmena sloupců a čísla řádků relativně nebo absolutně („s dolarem $“).
Nyní praktické připomínky:
- Nákupy budou přibývat. To máme po každém přidání měnit rozsah dat pojmenovaných naším identifikátorem tbVydaje?
- Nákupy budou přibývat. To máme po každém přidání dat měnit vzorec?
- Občas by se mohla změnit struktura tabulky (např. za první sloupec s datumem vložit sloupec s údajem, kdo z rodiny to koupil). Opět: To máme při každé restrukturalizaci dat měnit vzorec?
- Data budou mít časem 10 000 řádků a 87 sloupců. Když budeme mít uvedený vzorec „daleko“ od dat, budeme si pamatovat, co je vlastně ve sloupci B resp. v oblasti B2:B10001?
V některých případech je Excel schopen uvedené připomínky vyřešit automaticky. Pokud např. vložíme nový sloupec před existující druhý, Excel automaticky změní vzorce pro jednotkové ceny (obsahují jen explicitní relativní odkazy). Problém by však mohl nastat v některých vzorcích, které obsahují odkazy relativní i absolutní současně.
Pravidla, kdy Excel něco zajistí automaticky a něco ne, jsou pro běžného uživatele mírně řečeno nepřehledná. Je-li třeba vzorec pro celkovou cenu nákupů = Suma ( B2 : B33 ) alespoň tři řádky pod posledním řádkem pojmenované oblasti nebo tabulky Excelu, pak při zadání nového řádku dat bezprostředně za současný poslední Excel automaticky rozšíří pojmenovanou oblast o jeden řádek směrem dolů a upraví vzorec pro celkovou cenu. Pokud by však šlo o vzorec sčítající jen některá data = Suma ( B11 : B33 ), Excel sice pojmenovanou oblast rozšíří, ale vzorec neupraví.
Strukturované odkazy
Připomínky zmíněné v předchozím odstavci částečně řeší Tabulky Excelu zavedením strukturovaných odkazů. Strukturovaný odkaz je v prvním přiblížení tvořen kombinací jmen tabulky a sloupce. Je-li ve cvičných datech tabulka námi pojmenovaná tbVydaje a v ní druhý sloupec KC, pak celkové výdaje spočte vzorec vložený mimo tabulku
| vzorec s explicitními odkazy umístěný na listu s daty |
vzorec se strukturovanými odkazy umístěný kdekoliv v sešitu |
|
| = SUMA ( B2 : B33 ) | = SUMA ( tbVydaje [KC] ) |
K připomínkám v předchozím odstavci v kontextu Tabulky Excelu:
Ad 1: Při vložení byť jediné hodnoty do prvního volného řádku pod posledním řádkem tabulky rozšíří Excel pojmenovanou oblast tabulky automaticky o jeden řádek směrem dolů. Pokud by se „narazilo“ na již existující data pod tabulkou, k rozšíření nedojde. Stejně tak rozšíří Excel pojmenovanou oblast o jeden sloupec vpravo, zapíše-li se byť jediná hodnota do prvního volného sloupce vpravo vedle tabulky. Nejde-li o zápis do prvního řádku (tedy nadpisu), vytvoří Excel jméno tohoto nového sloupce sám; uživateli se doporučuje co nejdřív toto jméno změnit podle svých představ.
Ad 2: Při každé změně struktury tabulky Excel rovněž aktualizuje jednak odkaz na oblast dat příslušející jednotlivým jménům, jednak hodnoty vzorců obsahující strukturované odkazy.
Ad 3: Na závěr zřejmě nejpodstatnější vlastnost tabulek Excelu - přesněji grafického rozhraní Excelu při práci s tabulkami Excelu. Každá uživatelem vytvořená tabulka Excelu má - autorem dat nebo Excelem - pojmenované sloupce. Doporučuje se ve vzorcích místo explicitních odkazů používat odkazů strukturovaných. Při zápisu vzorce způsobem „ukazováním na operandy“ (kterými jsou oblasti dat tabulky) totiž pak sám Excel do vzorce dosadí nikoliv explicitní odkazy jako při použití „běžných“ dat, ale strukturované odkazy na základě jmen sloupců a kontextu řádku (řádků).
Ad 4: To je vyřešeno už tím, že se ve vzorcích vyskytují namísto odkazů explicitních odkazy strukturované, používající označení vytvořená autorem (a proto by ta označení měla být rozumně vypovídající o významu, ne tvaru např. BFLM).
Syntaktická pravidla strukturovaného odkazu
Označme:
| Označení | Význam | Příklad |
| JmTabulky | Identifikátor ve smyslu názvu tabulky | tbVydaje |
| ČástTabulky | Specifikace části tabulky (viz výčet možností níže) | [#Headers] nebo [#All] |
| ČástiTabulky | Prázdná nebo ČástTabulky; nebo ČástTabulky ČástiTabulky | Nic nebo [#Headers]; nebo [#Headers];[#Data]; |
| NázSloupce | Text ze záhlaví sloupce ve smyslu
názvu sloupce. Nemá-li tvar identifikátoru, musí být uzavřen mezi [ a ] |
DATUM nebo [% sazba daně] |
| Oblast | NázSloupce nebo NázSloupce:NázSloupce | DATUM nebo DATUM:DRUH |
Upozornění: V předchozí tabulce pozor na středníky a jejich umístění. Zvláště programátoři jsou zvyklí používat jako oddělovače v seznamech čárky.
Specifikací části tabulky se rozumí konstrukce podle následujícího výčtu (v prvním sloupci je za pomlčkou uvedený tvar v CZ mutaci, který je v CZ instalaci MS Office nutno používat):
| Specifikace části tabulky |
Odkazuje na: |
| [#Headers] - [#Záhlaví] | Pouze řádek záhlaví. |
| [#Data] - [#Data] | Pouze řádky dat. |
| [#Totals] - [#Součty] | Pouze řádek souhrnů. Pokud není, odkaz je Null. |
| [#All] - [#Vše] | Celou tabulka: záhlaví + data + souhrny (pokud existují). |
| [#This Row] - [#Tento řádek] @ @[NázSloupce] |
Pouze buňky toho řádku, ve kterém je umístěn vzorec (viz také poznámka níže). |
Poznámka: V poslední uvedené specifikaci jsou všechny tři možnosti ekvivalentní. Tuto specifikaci však nelze (na rozdíl od ostatních) kombinovat s jinými. Dále: pokud „ručně“ zapíšeme do vzorce specifikaci [#This Row], Excel ji sám změní na kratší @ - ale jen tehdy, má-li tabulka alespoň dva řádky dat. Pokud v jednořádkové tabulce dat zůstane specifikace [#This Row], upozorňují sami autoři Excelu na možné „unexpected calculation results“ (neočekávané výsledky výpočtu). Proto doporučují vkládat vzorce se strukturovanými odkazy až tehdy, mají-li data více řádků.
Strukturovaný odkaz bez kvalifikátoru má tvar:
[ČástiTabulky Oblast]
Strukturovaný odkaz s kvalifikátorem má tvar:
JmTabulky [ ČástiTabulky Oblast ]
Použije-li se strukturovaný odkaz ve vzorci uvnitř tabulky, může být bez kvalifikátoru. Použije-li se strukturovaný odkaz ve vzorci vně tabulky, musí být s kvalifikátorem.
Příklad: vzorec pro výpočet jednotkové ceny rohlíku (3. řádek listu) zapsaný do buňky H3 může mít tvar
=[@KC]/[@MNOZSTVI]
nebo jen
=[KC]/[MNOZSTVI]
protože je zapsán uvnitř tabulky. Vzorec pro výpočet téhož zapsaný do buňky J3 musí mít tvar
=tbVydaje[@KC]/tbVydaje[@MNOZSTVI]
nebo jen
=tbVydaje[KC]/tbVydaje[MNOZSTVI]
protože je zapsán vně tabulky.
Operátory nad strukturovanými odkazy
Jak známo, Excel pracuje s uživatelem vybranými (selected) oblastmi trojího typu, vizuálně znázorněné např. takto:
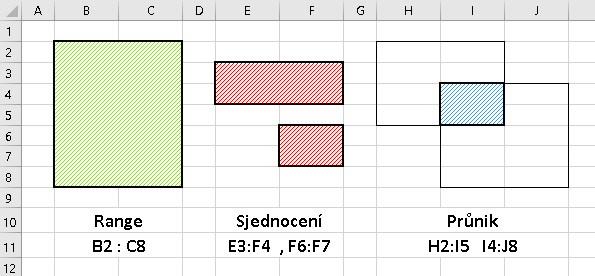
Poznámka: Pro jednu spojitou obdélníkovou oblast jsme ponechali objektový název „Range“, chápaný jako „Oblast variace mezi horní mezí (= levým horním rohem) a dolní mezí (=pravým dolním rohem) na konkrétní matici“. Těžko se totiž hledá odpovídající český termín, který by nekolidoval se stejným termínem, ale v jiném významu.
Na obrázku jsou rovněž zapsány explicitní odkazy. Je z nich patrné, že oblasti jsou výsledkem binárních operací nad dvěma operandy, kterými jsou oblasti. Na tomto místě však jde o zápis pomocí strukturovaných odkazů. Názorně ukazují operace konkrétní příklady; všechny používají cvičnou tabulku tbVydaje:
| Operátor | Odkazuje na: | Strukturovaným odkazem | Explicitním odkazem: |
| : (dvojtečka) | Všechny buňky dvou nebo více sousedních sloupců. Může to být formálně i jeden sloupec [KC]:[KC], funguje to, ale na kompletní strukturovaný zápis je to složité. |
tbVydaje [ [DATUM] : [CO] ] | A2 : C39 |
| , (čárka) | Sjednocení dvou oblastí | tbVydaje[JEDNOTKA] , tbVydaje[OBCHOD] | E2 : E33 , G2 : G33 |
| (mezera) | Průnik dvou oblastí | tbVydaje[[DATUM]:[KC]] _ tbVydaje[[KC]:[MNOZSTVI]] (znak _ zde znázorňuje MEZERU, nikoliv podtržítko!) |
B2 : B33 |
Příklady strukturovaných odkazů
Níže je uvedeno několik příkladů zápisu strukturovaného odkazu. Všechny příklady používají cvičnou tabulku tbVydaje. Pokud se použijí v CZ mutaci MS Office, je nutno příslušně zaměnit specifikaci části tabulky (viz shora Syntaktická pravidla).
| Strukturovaný odkaz: | Odkazuje na: | Explicitním odkazem: |
| tbVydaje [ [#All]; [MNOZSTVI] ] | Všechny buňky ve sloupci MNOZSTVI včetně řádku záhlaví a řádku souhrnů (existuje-li) | D1 : D33 |
| tbVydaje [ @ [KC] ] | Buňka v průsečíku řádku s tímto zápisem a sloupce KC. V tomto tvaru lze zapsat i mimo tabulku. | Je-li odkaz na řádku 5 listu, pak B5 |
| tbVydaje [ [#Headers]; [KC] ] | Pouze buňka záhlaví sloupce KC | B1 |
| tbVydaje [ [#Totals]; [KC] ] | Existuje-li řádek souhrnů (např. jako řádek 34 listu), pak odkaz vrací hodnotu souhrnu dat ve sloupci [KC]. Neexistuje-li, je zápis hodnocen jako neplatný odkaz. | B34 |
| tbVydaje [ [#Headers]; [KC] : [DRUH] ] | Pouze buňky záhlaví sloupců KC až DRUH | B1 : F1 |
| tbVydaje [ [#Totals]; [#Data]; [KC] ] | Pouze data a hodnota řádku souhrnu ve sloupci KC | B3 : B33 |
Vazby mezi tabulkami
Praktické postupy jsou demonstrovány na datech stejného cvičného sešitu uvedeného v úvodu tohoto článku, a to na listech lVydaje, lDruhy a lObchody.
Vazby mezi tabulkami
Data zmíněných listů cvičného sešitu simulují reálný provoz nějaké domácnosti. Především to jsou data poznamenávající, kdy a za kolik se toho nakoupilo (tedy jednotlivé VÝDAJE). V nich je pro pozdější generování informací i údaj, ve kterém obchodě to bylo, a jakého druhu to zboží bylo:
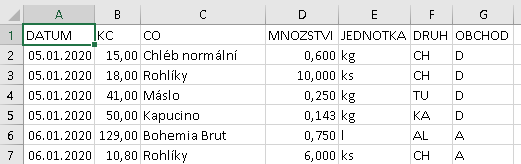
Zatímco údaj o nakoupeném zboží (chléb žitný, chléb vesnický, mléko plnotučné, mléko kefírové z Olešnice, mléko kefírové z ValMezu) je zde evidentně uveden jako otevřený text, údaj o druhu zboží se může skládat z hodně dlouhého označení a tedy druh jako otevřený text jistě nebude mnohokrát stejně zapisován přímo do výdajů (problém tzv. redundantních údajů), ale na jediném místě v jiné tabulce. Dalším podstatnou skutečností je vztah druhu zboží a sazby DPH, kterou je konkrétní druh zdaňován (článek je psán v březnu 2021; čtenář se v roce 2023 nebude stačit divit):
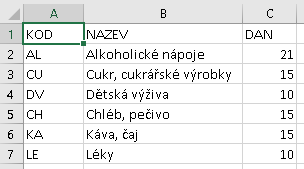
Teď ovšem nastane problém: když těch kódů druhů bude hodně, kdo si má při prohlížení výdajů pamatovat, že OB je Obuv a ne Oblečení? Ručně to je jednoduché: podívám se v daném řádku výdajů do sloupce Druh a v tabulce druhů si to ve sloupci Kód najdu. Tuto činnost však lze od databázového software očekávat už automatizovanou. V Excelu to nejprve řešili (a dodnes to lze použít) vyhledávacími funkcemi. Zde ukázka použití funkce SVyhledat:
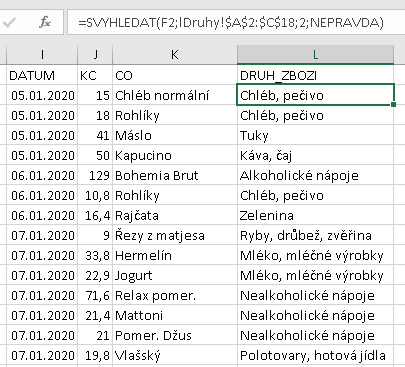
V databázové problematice jde o klasické čerpání dat nikoliv z jediného datového zdroje, ale ze dvou samostatných zdrojů, které jsou logicky propojeny nějakou přesně definovatelnou hodnotou společnou oběma zdrojům - zde hodnotou ve sloupci DRUH na straně výdajů a hodnotou ve sloupci KÓD na straně tabulky druhů zboží. Ke každému řádku tabulky VÝDAJE se logicky připojí ten jeden odpovídající řádek v tabulce DRUHY:
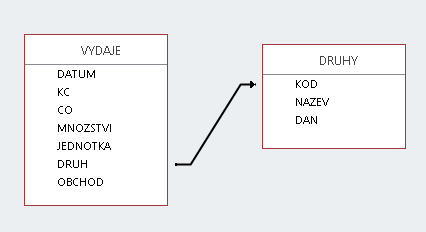
Při zpracování konkrétního řádku tabulky VÝDAJE tak lze čerpat data i z logicky připojeného řádku tabulky DRUHY.
Relace v Excelu 2016
Pro realizaci vazby z předchozího obrázku a hlavně jejího využití má Excel 2016 několik postupů. Zde popíšeme, jak vazbu využít v kontingenčních tabulkách. Nechť jest zpracovat částky uvedené ve výdajích jako součty v kontingenční tabulce s řádkovým kritériem z tabulky Druhy a sloupcovým kritériem z tabulky Obchody.
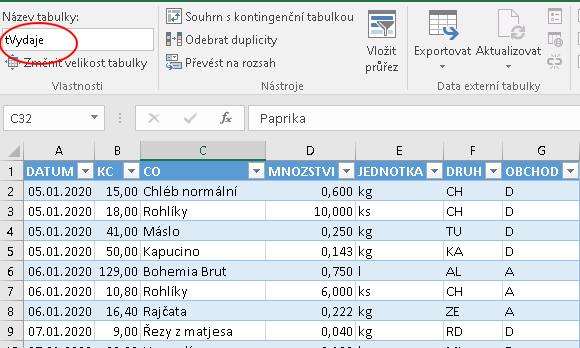
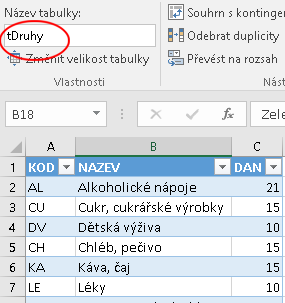
Především v tomto případě je celý mechanismus založen na jednotlivých pojmenovaných oblastech obsahujících data ve formátu tabulky relační databáze (viz shora). Ve fázi definování relace uživatelem však popisovaný nástroj předpokládá data nejen pouze v pojmenovaných oblastech, ale přímo jako tabulky Excelu (viz výše). Pokud tomu tak nebude, nástroj Excelu si je sám na tabulky převede, ale za cenu několika relativně nepřehledných kroků navíc. Proto je vhodné, aby si je uživatel připravil (a hlavně pojmenoval) sám jako další přípravný krok. Níže je tedy ukázka tohoto výchozího stavu. Aby bylo jasné, že jde o tabulky Excelu, bylo ponecháno strakaté formátování; pojmenování tabulek uživatelem je zvýrazněno:
Následuje vlastní definování logického vztahu (relationship, relace) mezi dvěma datovými zdroji, zde tabulkami Excelu. Zajistí to aktivace příkazu Relace posloupností
Data / Datové nástroje / Relace
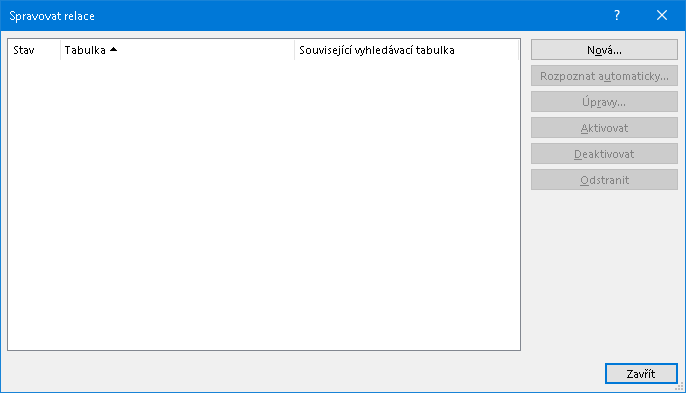
následkem čehož se otevře formulář Spravovat relace pro vytvoření, změn a odstranění konkrétní relace (může jich být samozřejmě více podle povahy úlohy). Zde evidentně požadujeme vytvořit relaci novou:
Spravovat relace / Nová
a nyní již (zatím prázdný) formulář pro jednu konkrétní relaci:
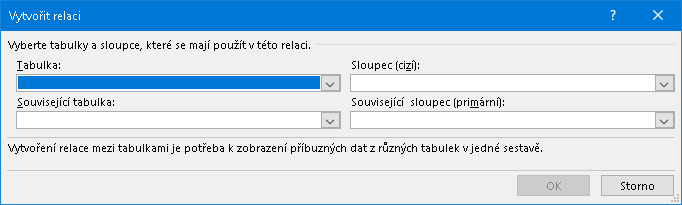
Demonstrovaný příklad požaduje vytvořit vazbu z tabulky námi nazvané tVýdaje vycházející ze sloupce DRUH (viz schéma nahoře) do související tabulky tDruhy směřující na sloupec KÓD:
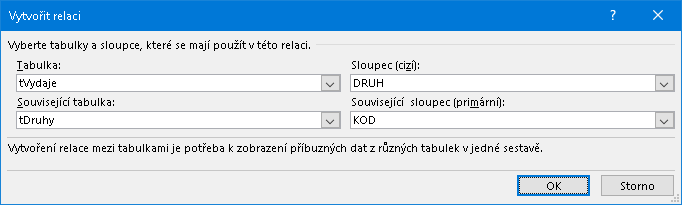
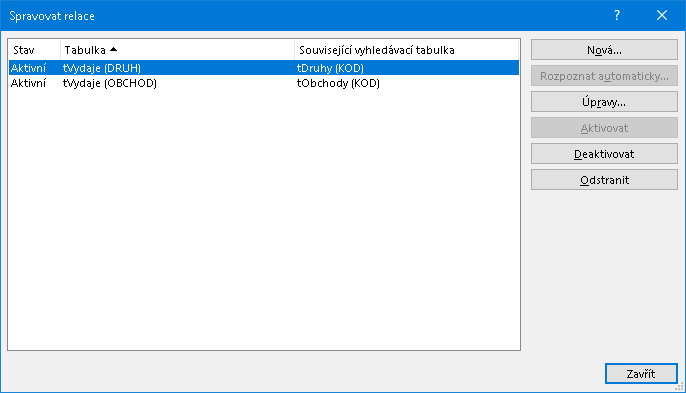
Po odeslání formuláře jest do seznamu správce relací vložen nový řádek vytvořenou relaci popisující:
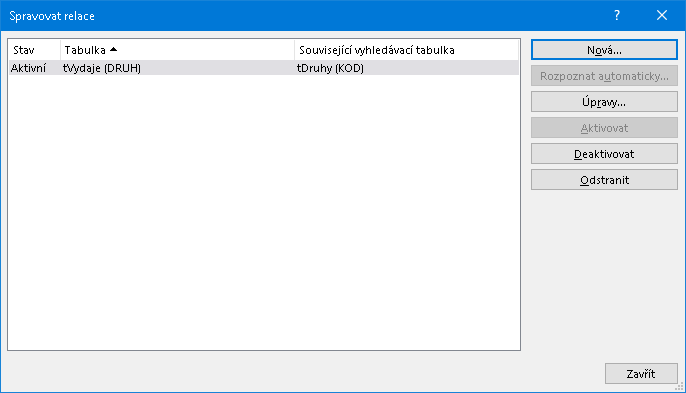
Ve cvičném sešitu jsou data připravena pro ukázku více vazeb. Jednak v datech tabulky VÝDAJE je to sloupec s OBCHOD kódem obchodu, kde se daný nákup uskutečnil. Dále jsou na samostatném listu lObchody data ve smyslu číselníku obchodů (v posledním sloupci OBCHODU je fiktivní počet provozoven v republice). Stejně jako v minulém kroku byla vytvořena vazba z Výdajů do Druhů, vytvořme analogicky vazbu z Výdajů do Obchodů - tentokrát přes sloupec OBCHOD ve VÝDAJÍCH do sloupce KÓD v OBCHODECH.
Nejprve tedy je třeba definovat oblast dat obchodů jako tabulku Excelu (nazvěme ji třeba tObchody):
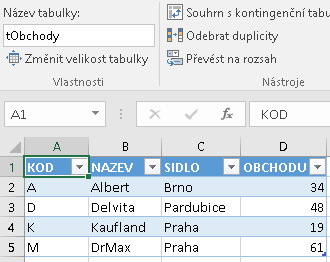
Nyní stejným postupem jako shora lze definovat další relaci, která se zobrazí ve správci relací:
Stručně o doplňku PowerPivot
V popisovaném rozšíření Excelu je možno používat několik nových doplňků (Add-in); jedním z nich je doplněk nazvaný PowerPivot. Jeho aktivaci zajistí posloupnost
Data / Datová nástroje / Spravovat datový model
následkem které se aktivuje hlavní karta PowerPivot a jí příslušný pás karet:
Poznámka: Text "Spravovat datový model" u shora zakroužkovaného příkazu se zobrazí jen při dostatečné šířce obrazovky (přesněji aktivního okna). Nápověda (tool-tip) k tomuto tlačítku bývá "Přejít do okna Power Pivot".
Hned první příkaz zleva
Power Pivot / Datový model / Spravovat
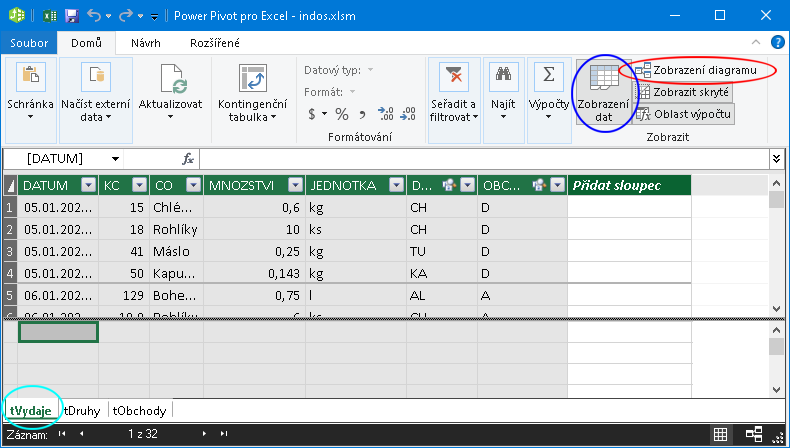
spustí paralelně k Excelu doplněk prezentovaný následujícím prostředím:
Tato kapitola se nezabývá podrobně doplňkem PowerPivot, ukazuje jen možnost grafické prezentace relací.
Na hlavní kartě Domů doplňku PowerPivot je vpravo skupina příkazů Zobrazit (viz předchozí obrázek). Prostředí PowerPivot zobrazuje při aktivní kartě Domů buď data, nebo diagram. Mezi těmito dvěma zobrazeními se přepíná příkazy Zobrazení dat (modře zakroužkované) a Zobrazení diagramu (červeně zakroužkované). Při aktivním zobrazení dat se zobrazí vždy data jednoho datového zdroje; záložkami vlevo dole se určuje, kterého (azurové zakroužkování).
Při zobrazení diagramu jsou vazby mezi datovými zdroji znázorněné graficky tak, jak je zvykem u databázových programů:
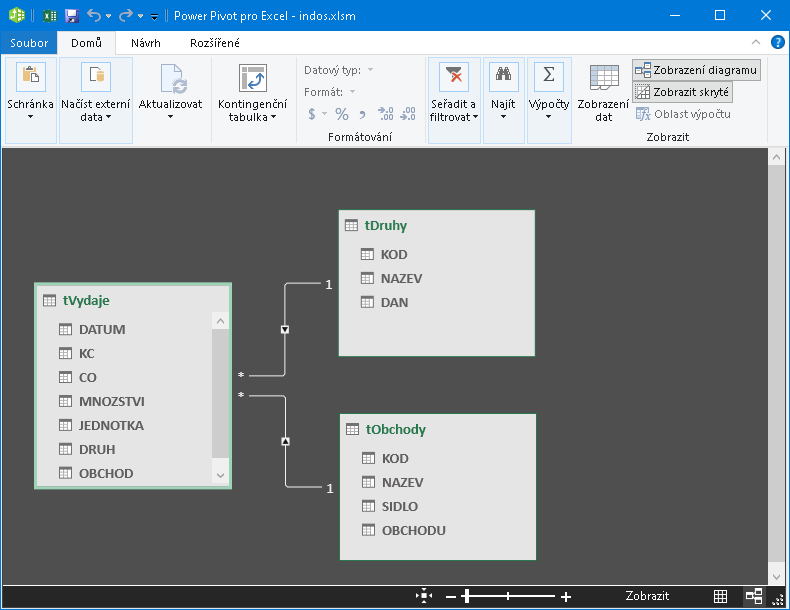
Jde o jednodušší způsob zobrazení vazby. Např. program Microsoft Access informuje navíc trvale polohou konců spojovacích čar o datových polích, která se vazby účastní. V PowerPivotu si s tím až tak moc nehráli, udělali to takto: pokud uživatel najede myší na některou spojovací čáru (červeně se zakroužkuje), v obou datových zdrojích se zeleně dočasně označí datová pole, na kterých je relace založena: Pokud uživatel tuto čáru označí (click), bude označení trvalé až do doby odznačení nebo označení čáry jiné.
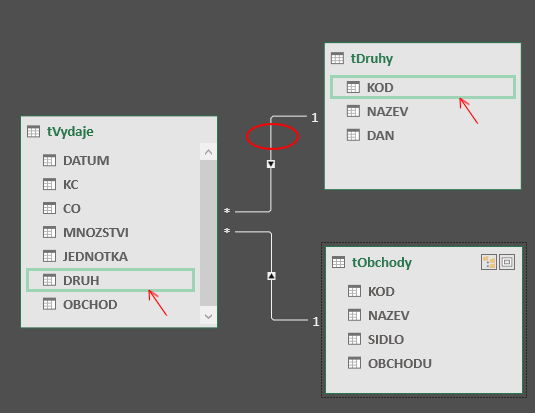
Double-click na spojovací čáru otevře formulář, ve kterém je možno konkrétní relace upravit. Jak již však bylo řečeno, podrobnější popis doplňku PowerPivot je nad rámec této publikace.
Použití relací v kontingenčních tabulkách
Shora je uvedena cvičná tabulka VÝDAJE, jejíž rozložení a data odpovídají definici relační databáze. Budeme směřovat ke kontingenční tabulce obsahující zpracovaná data (agregační funkce SUM) v maticovém tvaru:
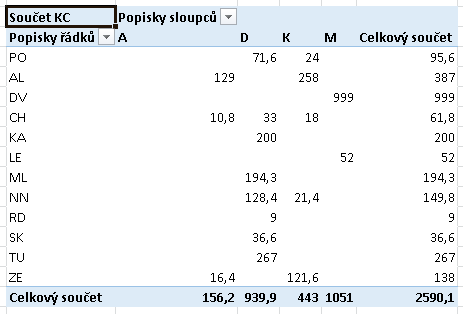
Řádkovým kritériem je tedy DRUH, sloupcovým je OBCHOD (obojí jsou kódy z tabulky VÝDAJE), součtovanou položkou jsou KČ (rovněž z tabulky VÝDAJE). Vytvoření takové tabulky zajistí běžně používaný známý postup.
Pokud jsme autory dat my sami, je nám význam kódu druhu ZE nebo kódu obchodu K důvěrně známý. Pokud však takovou tabulku předložíme někomu jinému, bude mírně řečeno zmaten. Jeho zmatek evidentně vyřeší náhrada kódů v záhlavích řádků a sloupců plnými texty. Tyto plné texty jsou však v jiných oblastech sešitu, přičemž dřívější verze Excelu umožňovaly jako zdroj dat buď jedinou oblast, nebo externí zdroj dat. Ona jediná oblast v sešitu mohla (a pořád může) být i výsledkem databázového dotazu, pro onen externí zdroj dat musí být předem definováno připojení. Obojí je podle mínění autora tohoto textu nad schopnosti běžného uživatele. V popisované verzi Excelu je však nabízena třetí možnost, tou je definovaný datový model. Příklad jeho definice včetně vytvoření vazeb mezi třemi datovými zdroji je obsahem předchozích odstavců, a tento datový model bude použit.
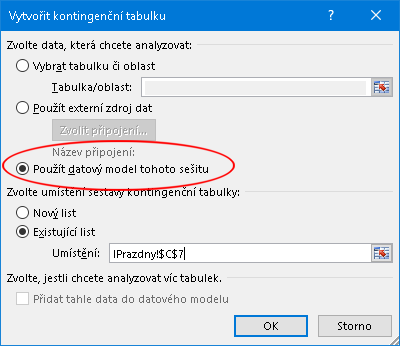
Vytvoření kontingenční tabulky (v ukázce v existujícím prázdném listu cvičného sešitu) začíná běžnou posloupností příkazů
Vložení / Kontingenční tabulka
následkem čehož je uživateli předložen formulář - na následujícím obrázku už připraven k odeslání, požadavek na použití datového modelu je vyznačen:
V panelu pro výběr polí kontingenční tabulky jsou v jeho levé části všechny dostupné datové zdroje datového modelu, u každého všechna jeho datová pole. Ta, která budou použita v ukázce, jsou zvýrazněna:
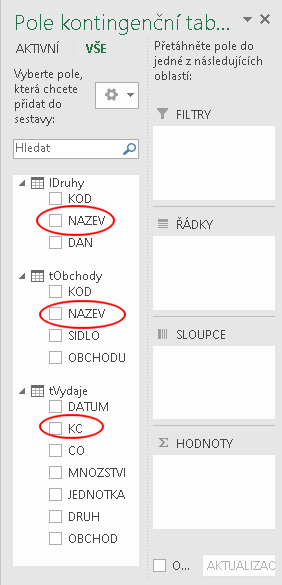
Nyní stačí běžným způsobem přetáhnout požadovaná pole do požadovaných oblastí:
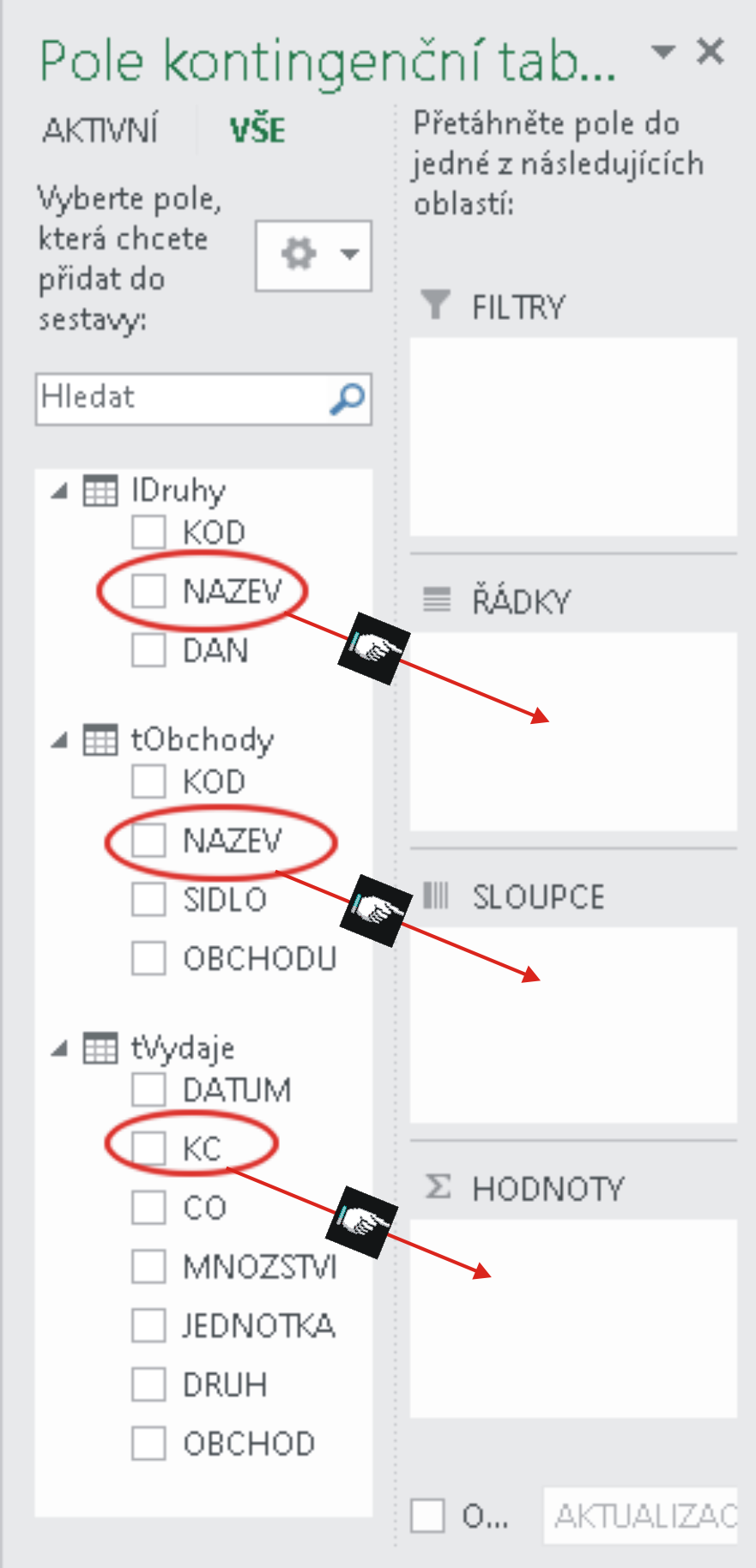
s očekávaným výsledkem:
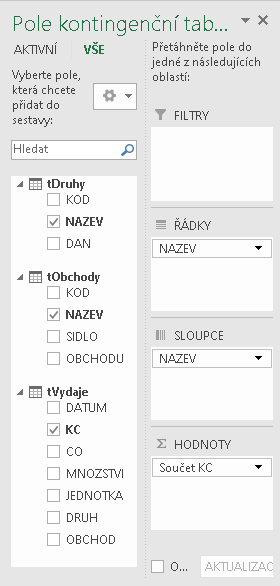
Bezprostředně poté je v cílové oblasti generována požadovaná kontingenční tabulka:
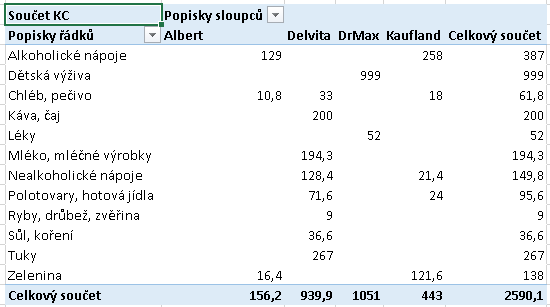
Tu je pak možno formátovat a jinak upravovat běžnými postupy definovanými pro kontingenční tabulky.
Literatura a další výukové zdroje
[1] DROZDOVÁ, J., HOMOLA, V.: Základy použití tabulkových procesorů. in: Informatika pro geovědní a montánní turismus.. VŠB - TU Ostrava, 2018, p. 40 - 65. ISBN 978-80-248-4145-8.
[2] HOMOLA, V., DROZDOVÁ, J.: Základy tabulkového procesoru Excel (učební texty pro distanční vyučování) [online]. VŠB - TU Ostrava, 2021, [cit. 06.05.2025]. Dostupné z http://homel.vsb.cz/~hom50/EXCEL/EXCOFFL/EXCDIST.HTM
[3] Review guidelines for customizing a number format in support.microsoft.com [online]. Microsoft, 2025 [cit. 06.05.2025]. Dostupné z W1W2W3, kde W1W2W3 vznikne spojením následujících třech textůW1, W2, W3 bez úvozovek:
W1 = "https://support.microsoft.com/en-us/office/"
W2 = "review-guidelines-for-customizing-a-number-format-"
W3 = "c0a1d1fa-d3f4-4018-96b7-9c9354dd99f5"