Relační databáze při monitoringu znečištěných vod důlních podniků
Doc. Dr. Vladimír Homola, Ph.D.
Abstrakt
Již několik let se provozuje v důlních podnicích Ostravsko - karvinského regionu informační systém založený na databázové aplikaci teorie grafů. Důlní vody jsou pojímány jako jeden z několika druhů monitorovaných vod ve vodohospodářské síti podniků. Relační model sítě pak dovoluje měsíčně zadávaná data o objemech vod a koncentraci znečišťujících látek sumarizovat, průběžně vyhodnocovat a zvláště poskytovat závěrečná roční vyhodnocení požadovaná např. zákonnou vyhláškou o poplatcích za vypouštění škodlivých látek. Článek se soustřeďuje na problematiku modelování potřebných datových struktur a vytváření vazeb mezi nimi.
Abstract
Northern Moravian coal mine companies are monitoring their water management by information system. This system is based on relational database application of graph theory. Mine waters are interpreted as one of several categories of waters monitored in the company net. In the environment of relational databases there is possible to enter the data about water volume, contamination concentration, consecutively evaluate continuously, and, mainly, to give the annual report of contamination required by Czech Water Protection Act. The article takes a focus to the required data structures and to the relationship between this structures.
Úvod
Důlní podniky jsou obecně jedním z největších producentů znečištěných vod. V oblasti Severní Moravy pracují hlubinné doly s vodami povrchovými i podzemními, z nich zvláště pak s vodami důlními s různým stupněm mineralizace. Vlastní výrobní činností vzniká enormní množství znečištěné vody. Ty jsou vodohospodářskou sítí podniku s různým stupněm těsnosti (a tedy s různým potenciálem průsaku do podloží) vedeny do čistíren odpadních vod příp. soustav kalových lagun opět v různém technickém stavu. Čištěné (a mnohé i nečištěné) vody jsou vypouštěny do vodních toků. Zákon 254/2001 Sb. a násl. (Vodní zákon) a prováděcí vyhláška 293/2002 Sb. a násl. stanovují zpoplatnění za vypouštění odpadních vod do vod povrchových; s ohledem na množství vod a jejich kvalitu jde o obrovské částky. Důlní podniky proto velmi pečlivě sledují své vodní hospodářství, zvláště vývoj jak spotřeby vody, tak jejího znečištění. Navíc jsou podle zmíněných zákonů povinny vývoj znečištění dokladovat.
Vodohospodářskou síť podniku je možno modelovat sítí i z pohledu matematické teorie grafů. Data stanovená pro sledování zákony na druhé straně tvoří entity relačních databází. Informační systém monitorující vodní hospodářství důlních podniků je proto založen na teorii grafů a aplikuje ji v prostředí relačních databází jak na topologii vodohospodářské sítě, tak na vlastní datová ohodnocení. Tato práce uvádí základní myšlenky modelu sítě a jeho praktického provedení, a některé algoritmy spojené s výpočty množství vod a obsahu znečišťujících látek příkazy databázových dotazovacích jazyků - xBase a SQL.
Vodohospodářská síť
Informační systém je založen na základních pojmech matematické teorie grafů, zvláště části zabývající se sítěmi. Pro uživatele informačního systému, kterými jsou především vodohospodáři jednotlivých podniků, z toho však neplynou žádné zvláštní požadavky na znalosti teoretických podkladů. Popis systému pro ně připravený sice ponechává pojem uzel sítě, ale pojem hrana nahrazuje často pojmem trasa nebo transportní cesta sítě, což jsou běžně chápaná synonyma.
Systém používá modely odpovídající vodohospodářské soustavě v povodí Odry. Jde o oblast geologicky výraznou, s extrémní hlubinnou důlní a průmyslovou činností a jejími negativními pozůstatky, které zasahují do všech oblastí lidského bytí. Je zřejmé, že i pouhé monitorování byť jediné veličiny v rámci celé soustavy je nesmírně náročný problém. Protože prioritní je při hospodaření s vodou udržení její kvality, lze při jedné z možných dekompozic systému použít kriterium změny kvality.
Označme symbolem P množinu všech důlních podniků Ostravsko - karvinské aglomerace a podniků na ně výrobně navazujících. Označme symbolem V podniky Ostravské vodovody a kanalizace a Severomoravské vodovody a kanalizace. Subsystém, který je programově pokryt, tvoří všechny
-
transportní cesty ležících v katastru některého podniku z P,
-
umělé transportní cesty některým podnikem z P zbudovaných nebo využívaných,
-
transportní cesty spojující některý podnik z P s některým podnikem z V,
-
podzemní zdroje ležící v katastru některého podniku z P,
-
přirozené i umělé nádrže, ležící buď v katastru některého podniku z P, nebo spojených transportní cestou s místem v katastru některého podniku z P.
Takto pojatý subsystém nezahrnuje přirozený vodní tok jako cestu, ale uvažuje z něj pouze (bodová) místa styku vodního toku a transportní cesty podniku z P.
Pojem síť je v teorii grafů pojmem zcela abstraktním. Ve spojení s přídavným jménem vodohospodářská však budí dojem, že jde o pouhý formalizovaný popis topologie rozvodu vod, tedy o popis fyzických objektů a fyzických spojení mezi nimi. Protože tak tomu není, upřesňují následující odstavce jednotlivé pojmy z hlediska aplikace teorie grafů do vodního hospodářství podniků.
Graf, síť
Pro orientaci uveďme bez dalšího komentáře nejnutnější definice z teorie grafů.
Definice grafu
Mějme konečnou množinu V; její prvky nazývejme vrcholy nebo také uzly; množina V je tedy množina vrcholů nebo také množina uzlů. Mějme konečnou množinu E; její prvky nazývejme hrany. Množina E je tedy množina hran. Označme ve shodě s obecně známou množinovou symbolikou:
V2 = V x V = { [u,v] | u Î V Ù v Î V }
V2 = V * V = { {u,v} | u Î V Ù v Î V }
V2 je tedy kartézský součin (= množina uspořádaných dvojic) vrcholů, uzlů z V. V2 je množina všech dvouprvkových množin (= neuspořádaných dvojic), jejichž prvky jsou vrcholy, uzly z V. Označme dále
J = VxV È V*V = V2 È V2
(konečnou) množinu, jejímiž prvky jsou všechny uspořádané dvojice vrcholů, uzlů (prvky VxV) a všechny neuspořádané dvojice vrcholů, uzlů (prvky V*V). Označme konečně F zobrazení
F: E ® J
(F je obecně zobrazení z E do J). Je-li tedy e Î E hrana jakožto vzor v zobrazení F, je F(e)=v Î J buď uspořádaná dvojice vrcholů (uzlů) nebo neuspořádaná dvojice vrcholů (uzlů) jakožto obraz ve zobrazení F. Zobrazení F nazývejme zobrazení incidence.
Definice: Trojici G = (V,E,F), kde V je množina vrcholů (uzlů), E množina hran a F zobrazení incidence, nazýváme grafem; v některých literaturách se také používá termínu obecný graf. Množinu všech e Î E takových, že F(e) Í V2 nazýváme množinou neorientovaných hran grafu G a její prvky neorientované hrany. Množinu všech e Î E takových, že F(e) Í V2 nazýváme množinou orientovaných hran grafu G a její prvky orientované hrany.
Poznámka z oblasti monitoringu vod: Je jen velmi málo příkladů na neorientované hrany. Většina hran ve vodním hospodářství je zobrazena na uspořádanou dvojici uzlů - to proto, že voda v hraně v naprosté většině proudí, a to z prvního do druhého uzlu.
Ohodnocení
Nechť je dána množina M, na které je definována binární operace Å : MxM ® M. Jsou-li m1, m2, ... , mn prvky M, budeme používat zřejmého označení åmi pro prvek (((...(m1 Å m2) Å ... ) Å mn. Dále nechť je nad M definována reflexivní, antisymetrická a tranzitivní relace, kterou budeme označovat £ (neostré uspořádání).
Definice: Nechť je dán graf G = (V,E,F). Existuje-li zobrazení OH:E(G)®M, říkáme, že graf G je hranově ohodnocený. Prvek OH(e) = m Î M se nazývá ohodnocení hrany e. Existuje-li zobrazení OV:V(G)®M, říkáme, že graf G je vrcholově (uzlově) ohodnocený. Prvek OV(v) = m Î M se nazývá ohodnocení vrcholu (uzlu) v.
Poznámka z oblasti monitoringu vod: Je-li u každého vrcholu (uzlu) známo, jaké jsou ztráty při průchodu vody vrcholem (uzlem), je tím dáno jedno z vrcholových ohodnocení grafu. Toto ohodnocení je podstatné zvláště u modelů průmyslových podniků, protože determinuje chování celého systému. Ztráty mohou být jak kladné (odpary, použití do výrobku), tak i záporné (např. průsak vody z podloží, srážková činnost).
V naprosté většině praktických aplikací jsou hrany a vrcholy (uzly) ohodnoceny numericky. Množinou M je pak množina všech reálných čísel, případně pro konkrétní úlohy množina racionálních, celých nebo i jen přirozených čísel.
Sítě, toky
Definice: Libovolný orientovaný hranově ohodnocený graf se nazývá síť, je-li ohodnocením zobrazení OH:E(G)®R (R je množina reálných čísel). Toto zobrazení se nazývá kapacita sítě. Hodnotu OH(e)=rÎR se nazývá kapacita hrany e. Protože na jednom grafu může být dáno více ohodnocení, upřesňuje se pak síť XY podle příslušného konkrétního ohodnocení XY.
Poznámka z oblasti monitoringu vod: Libovolný vodohospodářský subsystém je sítí, je-li na něm definována kapacita. Tou může být např. číslo udávající maximální průtok každou hranou. Z vodohospodářského hlediska je pak zajímavá úloha směřující k určení maximálního množství vody, které může protékat celou sítí.
Definice toku 1: Nechť je dána síť. Její ohodnocení OH se nazývá tokem, platí-li pro každý vrchol (uzel) vÎV tzv. 1. Kirchhoffův zákon:
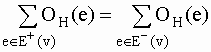 (1)
(1)
("v uzlech se nic nehromadí").
Poznámka: Kromě maximálního průtoku hranami je nejčastějším ohodnocením ve vodohospodářských subsystémech ohodnocení množstvím vody prošlé každou hranou za jisté období (průtok). Libovolný vodohospodářský subsystém je pak tokem, platí-li pro jeho hranové ohodnocení: množství vody přitékající do kteréhokoliv uzlu je rovno množství vody, které z něj odteče. Na první pohled je zřejmé, že ohodnocení množstvím vody pro většinu vodohospodářských subsystémů není v praxi tokem. Např. přírodní nádrže - zvláště s větší plochou - mají jednak ztráty způsobené výparem, jednak průsaky mohou vodu jak přivádět, tak odvádět. Souhrn množství těchto neevidovatelných pohybů může být značný vzhledem k přirozeným přítokům a odtokům. Navíc (protože k obdobným disproporcím dochází ze stejných důvodů i u hran) není hranové ohodnocení konstanta.
Poznámka: Ohodnocení množstvím vody lze na tok převést přidáním jednoho nebo více fiktivních uzlů; nazvěme je "Ostatní zdroje vod" a "Ostatní ztráty vod" a směrujme do nich fiktivní hrany z jednoho nebo více uzlů, kde dochází ke ztrátám nebo přírůstkům vod.
V praxi není tokem mnoho ohodnocení, které by (1) splňovaly, protože graf modelující vodohospodářský subsystém obsahuje uzly, které jsou kořeny a (nebo) listy. Proto pojem toku lze proto modifikovat takto:
Definice toku 2: Ohodnocení je tokem, platí-li (1) pro všechny vrcholy až na případný konečný počet vrcholů, pro které platí, že buď levá strana (1) nebo pravá strana (1) je rovna nule.
Poznámka z oblasti monitoringu vod: Ohodnocení množstvím vody je podle definice toku 2 tokem i pro subsystémy obsahující např. studny nebo bezodtoká místa vypouštění.
Právě grafů, na kterých je definován tok, se týká řada úloh aplikovatelných beze změny ve vodohospodářských subsystémech. Jde např. o výpočet maximálního toku nebo (v případě dolního a horního omezení pro ohodnocení hran) o obecnější úlohu stanovení přípustného toku. Je-li oceněním finanční hodnota, pak často řešenou úlohou je zjištění nejlevnějšího toku atd.
Uzly vodohospodářské sítě
Uzel vodohospodářské sítě je pro potřeby monitoringu chápán zejména jako místo, kde se mění kvalita vody nebo její kvantita. K takovým změnám dochází například v provozních místech (koupelny, úpravny, chlazení). Uzel je rovněž místem, kde se stýká nebo větví několik fyzických objektů transportní cesty, například potrubí nebo kanálů. Konečně je uzlem místo, ze kterého se voda odebírá (např. místo napojení na vodovodní síť dodavatele pitné vody, reprezentované vodoměrem) a místo, do kterého se voda vypouští (např. vyústění potrubí do řeky). Právě poslední zmíněné uzly jsou jednotlivými výpustěmi sledovanými pro účely zákona 254/2001 Sb.
Ztráty, ke kterým dochází v průběhu rozvodu resp. použitím vody, jsou rovněž jistým druhem vypouštění. Proto je v konkrétním modelu sítě zaveden jeden nebo více fiktivních uzlů označených právě jako Ztráty.
Takto pojatým pojmem "uzel" je dána jedna z jeho důležitých charakteristik: rovnost kvality všech vod z uzlu odváděných. Do uzlu mohou vstupovat vody z několika sousedních uzlů, a to i vody různých kvalit. V uzlu se voda použije (nejen prakticky např. při výrobní činnosti, ale i jen pouhým smísením). Jestliže se pak z uzlu voda rozvádí do více následujících uzlů, pak všechny tyto odváděné vody musí mít nutně stejné chemické složení a tedy stejnou kvalitu. Pokud by z jednoho uzlu byla odváděna do druhého uzlu voda pitná a do třetího voda splašková, pak nutně v prvním uzlu probíhají dvě rozdílné činnosti týkající se kvality vody a nejde o jeden uzel, ale o uzly dva.
Místo, kde se stýká nebo větví několik fyzických objektů transportní cesty, je rovněž uzlem. Z praktických důvodů je jako uzel chápáno také jediné místo na transportní cestě (např. na otevřeném kanále) - má jediný vstup a jediný výstup, nulové ztráty a nedochází v něm ke změně kvality vodu. Takové pojetí uzlů umožňuje lokalizovat místa odběru vzorků pro chemickou analýzu a analyzované hodnoty vztáhnout na kterýkoliv výstup z uzlu resp. na uzel jako takový.
Jednak zákony a vyhlášky, jednak vlastní provozní režimy podniku stanoví nejrůznější náležitosti vztažené k uzlům. Jde o nějaké označení každého z uzlů, způsob použití vody v něm, ale i koncentrace látek ve vodách z něj odcházejících. Je tedy zřejmé, že v síťovém modelu vodního hospodářství jde o několik uzlových ohodnocení.
Připomeňme, že popisovaný informační systém je provozován pro rozsáhlý vodohospodářský subsystém severní Moravy zahrnující mnoho podniků několika trustů. Uzel jako teoretický bod se vždy nachází ve správě jediné právnické nebo fyzické osoby. Proto se zmíněným ohodnocením uzlů nejsou v praxi problémy: všechny údaje zajistí daný správce uzlu jednak ze zákonné povinnosti, jednak z vlastního zájmu. Jiná situace může však nastat u tras - viz dále.
Trasy vodohospodářské sítě
Trasou (= hranou, řečeno termíny teorie grafů) je především jakékoliv transportní zařízení vedoucí vodu z jednoho uzlu do druhého. Může jít o fiktivní "zařízení" - např. odpařování v chladících zařízeních je modelováno jako transport (vzduchem) z místa chlazení do fiktivního uzlu Ztráty.
Charakteristikou trasy je konstantní kvalita vody v celé trase, kterou je kvalita vody vystupující z počátečního uzlu trasy. Naopak kvalita vody trasy je kvalitou vody vstupující do jejího koncového uzlu. Důsledkem je, že kvalita vody vystupující z nějakého uzlu je rovna kvalitě vody vstupující do kteréhokoliv jeho bezprostředního následníka. To je významný fakt, na němž je založena podstatná část výpočtů pohybu znečištění v síti.
Ideální stav vodohospodářské sítě je takový, když během transportu vody nedochází k jejím únikům. Popisovaný model s takovým stavem počítá. Pokud však ve skutečném provozu dochází k ne nepodstatným a přitom vyčíslitelným ztrátám, řeší to provozovatel zadáním transportního uzlu do takové trasy, a odvodem jistého množství vod z tohoto uzlu do uzlu Ztrát (= rozdělí trasu na dvě). Jen připomeňme, že v jistých situacích mohou být ztráty (většinou jednorázově) i záporné - vody přibude. Příkladem mohou být přívalové vody do otevřených kanálů za extrémních klimatických podmínek.
Obdobně jako u uzlů stanoví jednak zákony a vyhlášky, jednak vlastní provozní režimy podniku nejrůznější náležitosti vztažené k trasám. Jde o nějaké označení každé z tras, způsob jejího provedení, ale i množství a koncentrace látek ve vodách trasou procházející. Je tedy zřejmé, že v síťovém modelu vodního hospodářství jde o několik hranových ohodnocení.
Jsou-li oba krajní uzly trasy ve správě stejné fyzické nebo právnické osoby, je celá trasa ve správě téže osoby. Pak nejsou se zmíněným ohodnocením v praxi problémy: všechny údaje zajistí daný správce trasy jednak ze zákonné povinnosti, jednak z vlastního zájmu. Stejně tak nejsou problémy, je-li jeden uzel sice ve správě jiného subjektu, ale slouží pro odběr nebo vypouštění pouze danému podniku - např. vodoměr je ve správě Vodáren a kanalizací, zbytek trasy je ve správě podniku.
Jiná situace může nastat, jsou li oba krajní uzly ve správě různých osob, například dodává-li jeden podnik upravenou vodu druhému podniku nebo přijímá-li jeden podnik do své ČOV znečištěnou vodu jiného podniku. Ohodnocení téže trasy pak může být různé - nejčastěji se různí objemy vod prováděné kvalifikovaným odhadem nestejně informovanými nebo fundovanými odhadci. Nejde však o časté případy, sjednocení hodnot se řeší konzultací obou zúčastněných. Informační systém přesto případnou neshodu v některých případech zpracovává.
Model sítě jako relační databáze
Relační databázový model je obecně znám. Jeho základem jsou pojmy kartézský součin dvou a více množin, a n-ární relace jako podmnožina kartézského součinu. Ta je často označována jako tabulka relační databáze; má tedy hodnoty uspořádané do řádků = záznamů a sloupců = polí. Nejpodstatnější vlastností relačních databází je možnost vytvářet mezi tabulkami vazby ať už jednoduché na základě pouze hodnot sloupců (realizace typu Microsoft Jet), nebo na základě úplných výrazů (realizace typu Microsoft Fox).
Databázové prostředí
Popisovaný informační systém vznikl původně v prostředí PC pod systémem DOS 6, kde tabulky uložené jako samostatné soubory DBF zpracovával programový sytém Fox. Šlo - a dodnes v prostředí PC jde - o nejbezpečnější a nejrychlejší řešení. V současné době (až na průběžné inovace dané požadavky zákonů a uživatelů) je v podstatě provozován stejně, avšak s těmito dalšími aspekty:
-
Provoz je zajišťován na počítači s grafickou nadstavbou (GUI) známou jako Microsoft Windows.
-
Programové řešení je zajištěno prostřednictvím VBA v nějaké nosné aplikaci, na žádost provozovatele byl zvolen Microsoft Excel.
-
Data jsou soustředěna v souboru MDB resp. ACCDB, který odpovídá instanci objektové třídy Database.
-
Vstupy jsou dostupné v počítačové síti mapováním sdílených adresářů cizích počítačů.
-
Výstupy jsou generovány jako HTM soubory následně zobrazované běžným prohlížečem (iExplorer, Chrome aj.).
Přes bezesporné výhody provozu samostatné úlohy na jediném PC je nutno akceptovat stále se rozšiřující prostředí distribuovaných zdrojů dat v síťovém prostředí. Z ekonomických i jiných důvodů se popisovaný systém začal přepracovávat do prostředí Microsoft Windows, přičemž správa dat je koncentrována v objektu Database řízeného Microsoft Database Jet Engine. Tato práce popisuje vodohospodářský systém modelovaný v prostředí relačních databází poměrně obecně, bez ohledu na cílové prostředí, nicméně některé rozdílné aspekty dvou různých dotazovacích jazyků (xBase a SQL) se odrazí i ve vlastním řešení systému - nikoliv však v logice. Tyto rozdíly jsou v příslušných odstavcích vytknuty.
Množiny uzlů a hran
Teoretickým základem vodohospodářské sítě je graf; otázka modelu grafu v prostředí relačních databází je tedy prioritní. Je-li graf definován (viz shora) jako trojice uzly - hrany - zobrazení, je zapotřebí se zabývat především těmito třemi množinami. Dále musí úvahy směřovat k sítím a tokům, tedy ke grafům uzlově resp. hranově ohodnoceným.
Obecně model množiny vyplývá přímo z definice
relace jako podmnožiny kartézského součinu, tedy jako množina
uspořádaných n-tic. Jakákoliv množina tedy může být modelována jako
množina "jednic":
 |
Množina --> Tabulka |
|
kde hodnota ve sloupci Prvek je rovna
nějaké jednoznačné identifikaci prvku množiny. Pokud daná aplikace
logicky vylučuje, aby se nějaký prvek vyskytoval v množině dvakrát a
vícekrát, je možno určit sloupec Prvek jako primární klíč
tabulky.
Nechť tedy je dána množina uzlů. Nechť je na
množině uzlů dáno (obecně více než jedno) ohodnocení. Přirozeným
rozšířením shora uvedeného modelu je množina (n+1)-tic, kde n
je počet ohodnocení - příklad pro dvě ohodnocení g a
h:
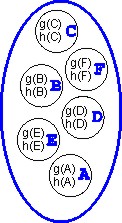
|
Množina uzlů s ohodnocením --> Tabulka |
|
Analogicky by bylo možno dospět k tabulkové reprezentaci ohodnocené množiny hran. Třetím v pořadí by mělo být zobrazení incidence. Tabulkovou reprezentací je evidentně množina trojic, kde prvním prvkem je zobrazovaná hrana a dalšími dvěma jsou počáteční a koncový uzel. Graf jako takový by pak byl reprezentován třemi tabulkami se zřejmými vazbami.
Tabulka hran a tabulka zobrazení incidence však mají totožný počet řádků pro totožné prvky, kterými jsou hrany. Po formální stránce se přiřazení počátečního a koncového uzlu hraně jeví jako dvě další ohodnocení. Nic tedy nebrání modelovat hrany a zobrazení incidence jedinou tabulkou se strukturou
[Hrana, Počáteční_uzel, Koncový_uzel, Ohodnocení_1, Ohodnocení_2, ... ]
s možností vytvořit vazby přes Počáteční_uzel do množiny uzlů a přes Koncový_uzel do téže množiny uzlů.
Připomeňme jen, že ohodnocení jsou v aplikacích typu GIS nazývána Uživatelské atributy a podobně. Termín Atributy bude dále používán v naznačeném smyslu.
Vazby, relace
Termín relace je používán ve spojení s databázemi ve dvou významech. Prvotní, matematický význam (viz shora) dal jméno relačním modelům. V nich je však používán termín relace ve druhém významu odvozeném z anglických slov relation, relationship - vazba, vztah.
V modelu vodohospodářské sítě tomu odpovídá např.
následující grafické znázornění odpovídající textu předchozího
odstavce:
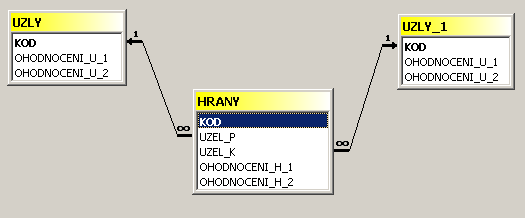
Při vytváření databázových aplikací se však ukazuje, že možnosti skutečná realizace vazeb je poplatná použitému databázovému systému. To může značně ovlivnit logiku vytvářené aplikace. Vysvětleme to na konkrétních příkladech.
xBase a soubory DBF
Databázový systém používající jazyk xBase pro zpracování především DBF souborů vytváří (a dovoluje použít) vazby dynamicky podle požadavku aplikace. Informace o tom, že dvě nebo více tabulek spolu logicky souvisí, není nikde uchována a teprve příkazy aplikace vazbu pro daný účel ustanoví a posléze zase zruší. Příkladem může být následující sekvence příkazů:
use HRANY in
1
&& "řídící" tabulka
use
UZLY in 2 order KODUZL
&& první
podřízená tabulka
use UZLY in 3 order KODUZL again alias
UZLY_1
&& druhá podřízená tabulka
set relation to UZEL_P into UZLY, UZEL_K into UZLY_1
&& vytvoření vazby
set skip to UZLY,
UZLY_1
&&
vazba 1:N
...
...
&& zpracování
dat z logické vazby
...
set relation to
&& zrušení vazby
Po zrušení vazby se může kdykoliv analogicky ustanovit a použít vazba jiná.
Podstatným faktem, bohužel v jiných systémech nerealizovaných, je toto: vazba je vytvářena z řídící tabulky (zde HRANY) přes vazební hodnotu (zde např. UZEL_P) do podřízené tabulky (zde např. UZLY), přičemž pořízená tabulka musí mít připojenou indexovou tabulku (zde KODUZL). To má celkem stejnou logiku jako ostatní systémy. Ovšem v xBase může být jak vazební hodnota tak indexová tabulka vytvářena z obecných výrazů, nikoliv jen z hodnot jednoho (či více) sloupců, jak je to v uvedeném zjednodušeném příkladu. Tedy místo UZEL_P může stát libovolný obecný, jakkoliv složitý výraz, stejně tak i indexová tabulka KODUZL může být vytvářena na základě libovolného výrazu. To je vynikající vlastnost výrazně usnadňující práci programátorů databázových aplikací. Uvažme jen, jak pracně by se bez této vlastnosti vytvářela vazba např. přes den v týdnu nějakého datumového sloupce.
Neméně podstatným faktem je aktualizovatelnost všech dat propojených tabulek. Přesněji: při procházení relací vytvořenou virtuální datovou strukturou je možno v této struktuře změnit jakákoliv data v ní, a to dokonce taková, která jsou prvky indexových výrazů a (nebo) vazebních výrazů.
SQL a soubory MDB (ACCDB)
Ze systémů používajících jazyk SQL uvažujme celkem zdařilý databázový objekt firmy Microsoft, v prostředí Windows definovaný např. v knihovně DAO360.DLL jako třída database. Fyzicky jsou data tohoto objektu uložena v jediném souboru se standardní příponou MDB, kterou - neurčí-li uživatel jinak - asociuje Microsoft programu Access. Proto se také někdy těmto databázím říká nepřesně "databáze Accessu". V novějších verzích je definice příslušných objektových tříd obsahem knihovny Microsoft Office 14.0 Access Database Engine Object Library, soubory s instancemi mají pak příponu ACCDB a další; ty jsou opět asociovány programu Access.
Samotná relace je zde definována a vytvářena jako jediná množina obsahující jedno nebo více spojení (vazeb) typu tabulka - tabulka. Obrázek z úvodu tohoto odstavce je právě příkladem. Každé z těchto spojení má několik vlastností: která tabulka je řídící, zda je vazba 1:N a hlavně která data se na vazbě podílí. Takto "natvrdo" vytvořená relace je pak uložena jako součást databáze v souboru MDB. Ne že by relace nešly programově měnit; jednak je to značně složité, ale hlavně to snad v reálném provozu aplikace nepřipadá v úvahu logicky.
Podstatným faktem pro takto vytvářené relace je to, že především vazba vychází z řídící tabulky přes vazební hodnoty, kterými však mohou být pouze hodnoty konkrétních sloupců. Dále, vazba směřuje do podřízené tabulky, která musí mít připojenou indexovou tabulku - a tu jde vytvářet opět pouze na základě hodnot jednoho nebo více konkrétních sloupců. Neexistuje tedy zde indexový výraz.
Autory v Microsoftu vedla k tomuto řešení zřejmě odlišná idea využití takto chápaných relací. Vytvořenou (jedinou) relaci jakožto množinu vazeb používají především k zajištění - jak tomu říkají - referenční integrity: zda data v řídící tabulce mají ekvivalent v podřízené tabulce (klasická "kontrola na číselník"). Dále díky tomu lze elegantně, bez nutnosti doprogramování, změnit "kód v číselníku" s následnou změnou ve všech tabulkách, z nichž vazba do číselníku směřuje. Konečně lze opět automaticky nechat vypustit odpovídající řádky v nadřízených tabulkách při vypuštění řádku v "číselníku".
Microsoftem dodávaný program Access dále využívá vazeb definovaných v relaci ve svých návrhových prostředích (dotazy, sestavy), kdy předkládá návrháři již provázané tabulky - a řekněme upřímně, často je návrhář ani nechce a stejně často jsou navíc zmatené a v těchto prostředích neodpovídají vazbám skutečným.
Alespoň částečnou náhradu za neexistující výraz v indexech a vazbách dává SQL příkaz Select díky klauzulím right join resp. left join. Množina záznamů řídící tabulky s propojením na údaje v podřízených tabulkách odpovídající vazbě v xBase předchozího odstavce je vytvořena příkazem SQL tvaru
select H.*, UP.*, UK.*
from
(HRANY H left join UZLY UP on
H.UZEL_P = UP.KOD)
left join UZLY UK on
H.UZEL_K = UK.KOD
Ačkoliv to v referenčních materiálech SQL není psáno, některé systémy (včetně systémů Microsoftu) připouští na místě podmínky on nejen podmínku typu pole=pole, ale minimálně elementární logický výraz. To pak zjednodušuje vytváření vazeb zprostředkovaných více hodnotami. Bohužel pro aplikačního programátora, virtuální datová struktura vytvořená pomocí výrazů není aktualizovatelná v žádném poli, ani takovém, které se nepodílí na indexech nebo vazbě (srov. s xBase).
Praktická realizace topologie sítě
Předchozím obrázkem je vyjádřen schematicky
databázový model topologie sítě. Při jeho praktické realizaci v
konkrétním databázovém prostředí mohou však nastat problémy popsané
níže. Pro jejich vysvětlení uvažujme jednoduchou vodohospodářskou
síť modelového podniku P podle následujícího obrázku (zdroj - mapy.cz):
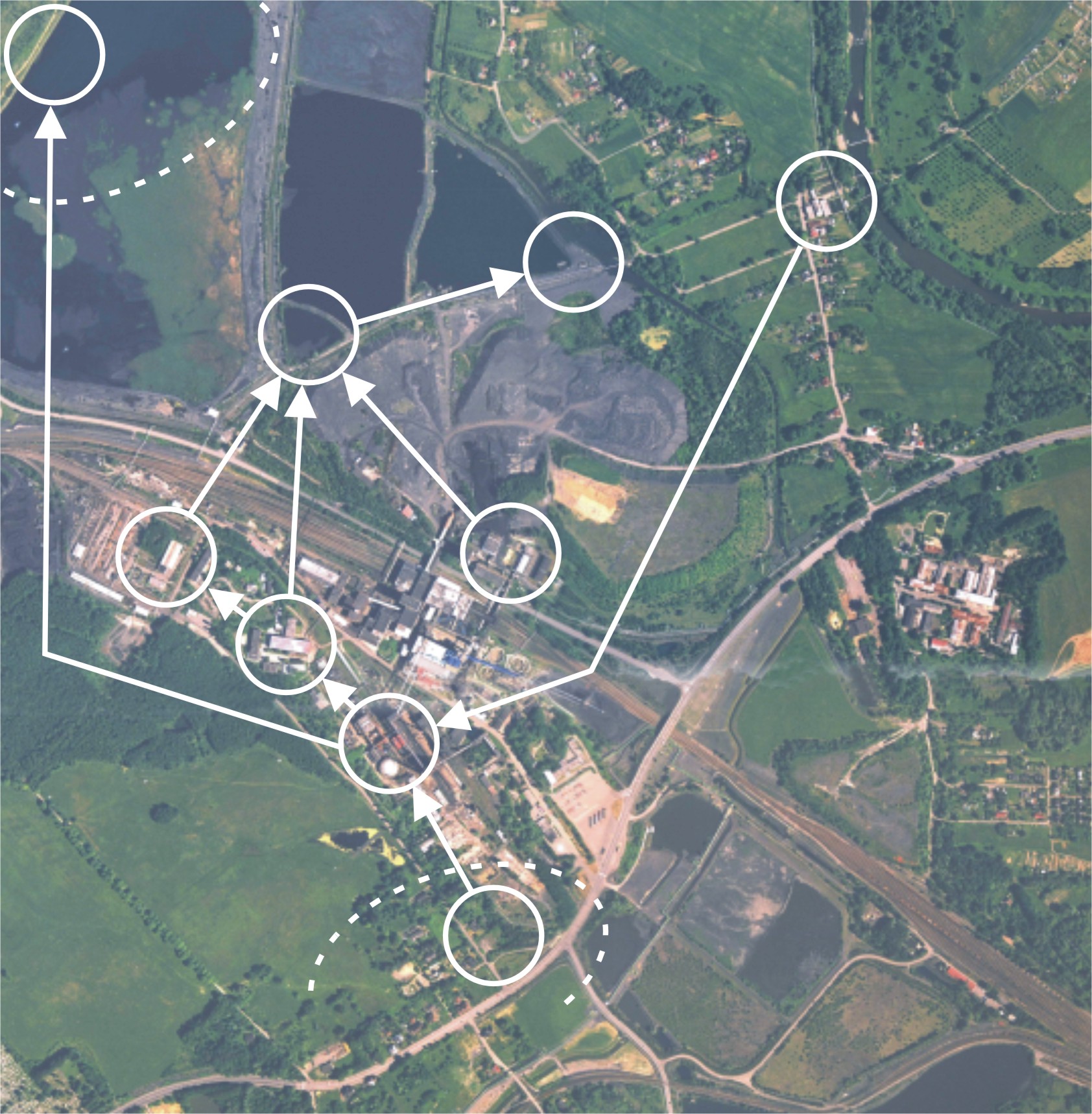
Na obrázku jsou čárkovaně znázorněny hranice podniků jakožto právních subjektů. Ve spodní části je takto vymezen jeden uzel, který je místem odběru pitné vody z podniku V (Vodovody a Kanalizace), v horní části obrázku jde o čistírnu odpadních vod jiného důlního podniku D.
Zmíněný problém spočívá v označení uzlů resp. hran a zajišťování vazeb mezi hranami a uzly. Z jistých historických důvodů je vodohospodář podniku P zvyklý na označení uzlu typu např. 1234 (a hned ví, že jde o uzel typu "Úpravna užitkové vody"). Ze stejných důvodů je na to zvyklý vodohospodář podniku D. Ovšem 1234 v (P) je fyzicky jiný uzel než 1234 v (D). Ze stejných historických důvodů jsou podniky samotné nějak "okódovány" - řekněme např. kódem typu P a D. Jednoznačná identifikace uzlu by pak mohla být tvaru P1234 a D1234. To je sice možné, ale v takovém případě má kód uzlu vypovídací schopnost minimálně o podniku, kde se nachází. Kód podniku je evidentně vazebním prvkem do tabulky podniků. Shora však bylo vysvětleno, že ne všechny databázové systémy podporují výraz (zde např. volání funkce tvaru left(KOD_UZLU,1)) při vytváření vazeb. Na druhé straně někde mezi atributy uzlu jistě musí být zjistitelná identifikace podniku, v jehož správě se uzel nachází. Avšak přítomnost kódu podniku jednak v kódu uzlu a jednak v samostatném sloupci znamená v databázích nejméně vhodnou věc - redundantní údaj.
V popisovaném systému bylo přijato kompromisní
řešení (už s ohledem na budoucí transformaci pod řízení jiným
databázovým systémem), kdy identifikace uzlu je dána nikoliv jedinou
položkou [kód] tvaru např. P1234, ale dvojicí tvaru [Podnik;Uzel],
který je v systémech xBase vyjádřen výrazem Podnik+Uzel a systémech SQL dvěma
poli:
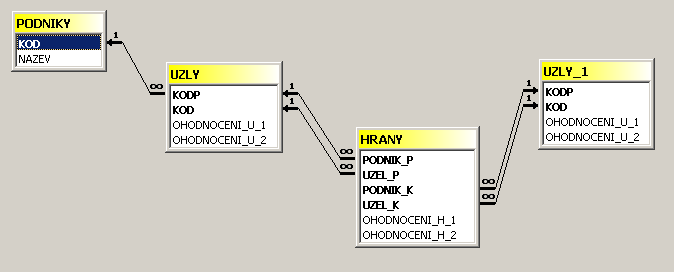
Dynamické vytvoření relace v systémech s xBase je analogické jednoduššímu případu popsanému shora. Příkaz SQL realizující množinu záznamů souboru HRANY s připojenými poli ostatních souborů dle předchozího obrázku by mohl být např. tento:
select H.*, UP.*, UK.*, P.*
from
UZLY UK right join
(
(PODNIKY P right join UZLY UP on P.KOD = UP.KODP)
right join HRANY H on UP.KODP+UP.KOD =
H.PODNIK_P+H.UZEL_P
)
on UK.KODP+UK.KOD = H.PODNIK_K+H.UZEL_K
Tučně je v příkaze znázorněna vazba výrazem. Je však zřejmé, že právě zde je ve skutečnosti použita vazba jednotlivými poli, protože aplikace není ochuzena o aktualizovatelnost výsledné datové struktury.
Základní operace nad modelem sítě
Operace s objemy vod
Jde "jen" o to, zadávat průběžně pro každou trasu objem, který trasou protekl od minulého zadání. Toto zadávání objemů je však jedním z největších problémů v celém systému.
Poznámka: Samo zjištění objemu vodohospodářem na konkrétní trase je významným problémem, avšak pro samotného. Příčiny jsou diskutovány v kapitole 5 - zmiňme jen častou nemožnost instalace vodoměrů, výsledky namátkových měření nepřenositelných v čase, velký rozptyl kvalifikovaného odhadu apod. Popisovaný informační systém bere hodnotu, zadanou vodohospodářem (a zjištěnou jakýmkoliv způsobem) za jedinou možnou a nediskutovatelnou (samozřejmě na pokyn vodohospodáře změnitelnou).
Zmíněný problém spočívá v tom, že:
-
Vždy existují trasy, které vodohospodář ohodnotit objemem prostě nemůže, aniž by nad získáváním údaje strávil neúnosný čas nebo vydal neúnosné finanční prostředky.
-
Některé trasy jsou čas od času (nebo od jisté doby trvale) uzavřeny.
-
Jednou zadaná data je možno měnit (např. zpětným zpřesněním odhadu).
-
Zadaných objemových dat může být libovolný počet, nejméně však jedna měsíčně.
-
Nejmenší jednotkou požadovaných výstupních informací je jeden měsíc.
-
Jednotkou požadovaných souhrnných informací je jeden (kalendářní) rok.
Body 5 a 6 předurčují model vodohospodářské sítě jako model statický; lze na něj pohlížet jako na soustavu statických "snímků" uspořádaných měsíc po měsíci. Nejde tedy o klasický dynamický model pracující navíc s časovou dimenzí. Proto lze problematiku zpracování objemů redukovat na zpracování objemů v jednom měsíci. Tato redukce je popsána v bezprostředně následujícím odstavci "Měsíční objemy". Bod 3 lze řešit opakovanou redukcí na měsíční objemy po změně dat. Bod 2 lze automatizovat indikací v trasách: objemy v indikovaných trasách jsou vždy generovány jako nulové, pokud nejsou explicitně zadány vodohospodářem. Teprve po všech těchto dílčích krocích lze přistoupit k řešení bodu 1; to je popsáno dále v odstavci "Dopočty nezadaných objemů".
Měsíční objemy
S ohledem na bod 4 se před zpracováním objemů za jeden měsíc provede relační operace
OBJEMY(*) - OBJEMY(*: INDIKACE='P') + OP(*)
kde symbol * zastupuje všechny atributy relace OBJEMY (tj. "všechny sloupce" databáze objemů) a relace OP se vytvoří následujícím algoritmem:
Algoritmus 1:
-
Vytvoř prázdnou relaci OP se stejnou množinou atributů jako OBJEMY.
-
Zjisti datum D odpovídající poslednímu dni požadovaného měsíce požadovaného roku.
-
Pro všechny trasy T aplikuj následující kroky.
-
Jestliže pro trasu T existuje v OBJEMY prvek s datem D, pokračuj krokem 9.
-
Jestliže pro trasu T existují v OBJEMY prvky s daty DG > D a současně prvky s daty DL < D, přičemž měsíc alespoň jednoho z DL, DG je roven měsíci D, zařaď do OP prvek s datem D, indikací P a objemem lineárně interpolovaným v <max(DL);min(DG)> a pokračuj krokem 9.
-
Jestliže pro trasu T existují v OBJEMY prvky s daty DL < D, přičemž měsíc alespoň jednoho z DL je roven měsíci D, zařaď do OP prvek s datem D, indikací P a objemem rovným "konstantnímu prodloužení" objemu v max(DL), a pokračuj krokem 9.
-
Jestliže pro trasu T existují v OBJEMY prvky s daty DG > D, přičemž měsíc alespoň jednoho z DG je roven měsíci D, zařaď do OP prvek s datem D, indikací P a objemem rovným "konstantnímu prodloužení dopředu" objemu v min(DG), a pokračuj krokem 9.
-
Nezařazuj do OP pro trasu T a měsíc data D nic.
-
Jestliže nejsou takto zpracovány všechny trasy, pokračuj další trasou T a krokem 4.
Po provedení algoritmu 1 pro všechny měsíce doposud zadané stačí substituovat tabulku OBJEMY tabulkou
S OBJEM | trasa,měsíc,rok (OBJEMY(*))
tj. tabulkou se stejnou strukturou, v níž jsou pro každou trasu sečteny objemy v jednotlivých měsících jednotlivých let. Operace S je korektní, protože na OBJEMY byla aplikována operace uvedená před popisem algoritmu 1 a tudíž obsahuje pro každou trasu a každý měsíc alespoň jeden objem (typu "k datu") a vždy objem "k poslednímu dni měsíce".
Dopočty nezadaných objemů
Poznámka 1: Celý tento odstavec se týká jednoho "statického snímku" vodohospodářské sítě ve stavu ke konci daného měsíce získaného podle předchozího odstavce. Všechna zmiňovaná objemová data jsou data právě pro tento stav, tj. za daný měsíc.
Poznámka 2: Výchozím stavem je taková tabulka OBJEMY, ve které za daný měsíc nejsou ohodnoceny všechny trasy sítě. Cílovým stavem je tabulka doplněná tak, že již všechny trasy ohodnoceny jsou. Pro rozlišení, jakým způsobem byly hodnoty objemu získány, slouží atribut INDIKACE. Hodnoty získané dopočtem zde mají indikaci 'D'.
Mějme trasu T Î TRASY. Podle definice grafu je tato trasa zobrazena zobrazením incidence F na [UZ,T, UC,T], kde UZ,T, UC,T Î UZLY. Definujme D(U)
D(U) = {TÎ TRASY | F(T)=[Y,U] Ů Y,U Î UZLY}
jako množinu všech tras, jimž je uzel U cílovým uzlem (tedy jako množinu tras, které "vstupují" do uzlu U). Obdobně definujme V(U)
V(U) = {TÎTRASY | F(T)=[U,Y] Ů U,Y Î UZLY}
jako množinu všech tras, jimž je uzel U zdrojovým uzlem (tedy jako množinu tras, které "vystupují" z uzlu U). Použijme dále následujících označení:
-
N(A) ... počet prvků množiny A
-
O(T) ... objem vody vstupující do trasy T
-
OD(U) ... objem vody vstupující do uzlu U
-
OV(U) ... objem vody vystupující z uzlu U
-
Z(T) ... procento ztrát na trase T
-
Z(U) ... procento ztrát v uzlu U
Je proto
OV(U) = S O (T ) | T Î V(U)
a obdobně
OD(U) = S O (T ) . (1+Z(T)/100) | T Î D(U)
Ze zákona o zachování hmoty plyne
OV(U) = OD(U) - Z(U)
pro každý uzel U. Jde v podstatě o Kirchoffovu rovnici pro uzly modifikované ztrátami; v "čisté" Kirchoffově rovnici by se ztráty objevily jako odvod vody do fiktivního uzlu ZTRÁTY.
Principielně by bylo možno sestavit soustavu tolika (lineárních) rovnic, kolik je uzlů v síti, pro tolik neznámých, kolik je tras s nezadaným objemem. Nehledě na počet rovnic (pro popisovaný vodohospodářský subsystém okolo 1000) brání takovému postupu výpočtu nezadaných objemů zejména
-
fakt, že ztráty v uzlech jsou sice dány jako standardně předpokládané ztráty, ale zadáním objemů pro všechny trasy vstupující a vystupující z uzlu je požadován výpočet skutečných aktuálních ztrát v uzlu
-
to, že jednoznačné řešení vyžaduje přesně tolik nezadaných objemů, kolik je rovnic (tj. kolik je uzlů); většinou je však soustava přeurčená.
Je zřejmé, že korektní výpočet je úzce svázán s konfigurací vodohospodářské sítě a s určením minima tras, pro které vodohospodáři objem zadávat musí (pro ostatní trasy objemy zadávat mohou). Pro určování nezadaných objemů byl proto zvolen jiný postup než přímý výpočet; tento postup zároveň dovolí odhalit kritická místa v konfiguraci sítě.
Poznámka: Logiku vysvětlíme na zjednodušeném modelu - takovém, kde ani na trasách ani v uzlech nejsou ztráty. Aplikace ztrát však je evidentní a vyplyne z výkladu.
Rozeberme nejprve, jaké mohou logicky nastat
případy částečného ohodnocení tras objemy z hlediska každého
jednotlivého konkrétního uzlu nebo trasy.
|
U1. Jsou známy objemy všech tras do uzlu vstupujících i vystupujících (na obrázku tučně, v barvě zeleně). |
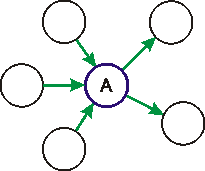
|
|
U2. Jsou známy objemy všech tras do uzlu vstupujících i vystupujících (na obrázku tučně, v barvě zeleně) kromě jediné (na obrázku tence, v barvě červeně). Neznámý objem je jednoznačně vypočitatelný (viz však níže případ H1). |
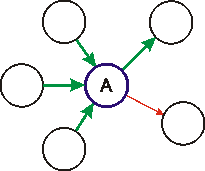
|
|
U3. Jsou známy objemy některých tras do uzlu vstupujících nebo vystupujících (na obrázku tučně, v barvě zeleně) a některých ne (na obrázku tence, v barvě červeně). Je zřejmé, že v tomto případě neznámé objemy určit nelze. |
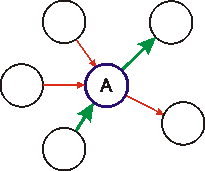
|
|
H1. Nastane "dvojnásobný" případ U1 pro vpravo uvedenou konfiguraci. Existuje osm různých možností řešení této situace, z nichž jen tři jsou jednoznačné. Po řadě konzultací s vodohospodáři se tato situace řeší jedním ze třech jednoznačných výpočtů, a to určením aktuální ztráty na trase. Na základě uzlu A pomocí U2 se zjistí množství vody do trasy vstupující a stejným způsobem na základě uzlu B množství vody z trasy vystupující. Rozdíl těchto hodnot je aktuální ztrátou trasy. Stejně jako v případě uzlu může být ztráta i záporná. |
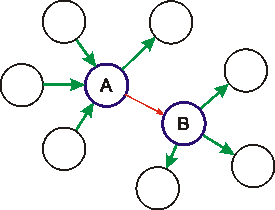
|
|
H2. Nastane "dvojnásobný" případ U1, avšak vázaný přes případ U3 pro následující konfiguraci. Existují principielně tři řešení. Z nich bylo - opět po konzultacích s vodohospodáři - zvoleno toto řešení: nejprve se pomocí U2 spočte objem v trase CA, poté stejně v trase AB, a nakonec se zjistí aktuální ztráta v uzlu A pomocí U1. |
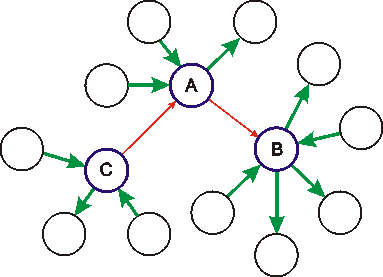
|
Každý další případ je převoditelný na U1 až U3, H1 až H2.
Nyní tedy lze uvést způsob výpočtu použitý pro dopočet nezadaných objemů. Výchozím stavem je "nedoplněná" databáze objemů. Provede se tedy nejprve operace (pro význam položky INDIKACE viz poznámka 2 shora)
OBJEMY(*) - OBJEMY(*: INDIKACE='D')
která odstraní event. dříve dopočtené hodnoty. Při výpočtu se opakovaně zjišťují počty doposud zjištěných a nezjištěných objemů. Používá se k tomu pomocná tabulka zjištěná následujícím způsobem:
Algoritmus 2:
* Podprogram na základě stavu objemů zjistí počty
zadaných a nezadaných
* tras v jednotlivch uzlech (do STUPUZL).
select ;
KODPZ as KODP, KODZ as KOD, ;
0 as CELKVST, ;
0 as ZADVST, ;
0 as OBJVST, ;
count (KODZ) as CELKVYST, ;
sum (iif (empty (INDIKACE), 0, 1)) as ZADVYST, ;
sum (iif (empty (INDIKACE), 0, OBJEM)) as OBJVYST ;
from (OBJEMY) ;
into table (M_TEMP2) ;
group by KODP, KOD ;
union ;
select ;
KODPC as KODP, KODC as KOD, ;
count (KODC) as CELKVST, ;
sum (iif (empty (INDIKACE), 0, 1)) as ZADVST, ;
sum (iif (empty (INDIKACE), 0, OBJEM-OBJEM*ZTRATA/100)) as
OBJVST, ;
0 as CELKVYST, ;
0 as ZADVYST, ;
0 as OBJVYST ;
from (OBJEMY) ;
group by KODP, KOD
select ;
KODP, KOD, ;
sum (CELKVST) as CELKVST, ;
sum (ZADVST) as ZADVST, ;
sum (OBJVST) as OBJVST, ;
sum (CELKVYST) as CELKVYST, ;
sum (ZADVYST) as ZADVYST, ;
sum (OBJVYST) as OBJVYST, ;
sum (CELKVST) - sum (ZADVST) as CHYBIVST, ;
sum (CELKVYST) - sum (ZADVYST) as CHYBIVYST, ;
sum (CELKVST) - sum (ZADVST) + sum (CELKVYST) - sum (ZADVYST)
as CHYBICELK ;
from (M_TEMP2) ;
into table (STUPUZL) ;
group by KODP, KOD
Identifikátory tabulky STUPUZL mají tedy následující význam:
|
CELKVST |
Celkový počet tras vstupujících do uzlu |
| ZADVST | Počet vstupujících tras, pro které je znám objem |
| OBJVST | Známý objem, který do uzlu vstupuje |
| CELKVYST | Celkový počet tras vystupujících z uzlu |
| ZADVYST | Počet vystupujících tras, pro které je znám objem |
| OBJVYST | Známý objem, který z uzlu vystupuje |
| CHYBIVST | Počet tras vstupujících do uzlu, pro něž není znám objem |
| CHYBIVYST | Počet tras vystupujících z uzlu, pro něž není znám objem |
| CHYBICELK | Celkový počet tras incidujících s uzlem, pro něž není znám objem |
Nyní lze uvést algoritmus použitý pro dopočet chybějících objemů (k operaci ® viz poznámku dole); odvolává se přitom na počty tras a objemy vstupující a vystupující do a z uzlů uložených v tabulce STUPUZL:
Algoritmus 3:
-
Proveď algoritmus 2. Pak prováděj následující kroky tak dlouho, dokud je alespoň jednou proveden dopočet ®. Jestliže není proveden ani jednou, pokračuj krokem 5.
-
Pro všechny trasy s nezadaným objemem, pro jejichž vstupní uzly platí CHYBICELK=1 a pro jejichž výstupní uzly platí CHYBICELK=0 nebo CHYBICELK>1, proveď OBJVST-OBJVYST ® objem trasy. Bylo-li provedeno alespoň jednou, pokračuj krokem 1, jinak krokem 3.
-
Pro všechny trasy s nezadaným objemem, pro jejichž výstupní uzly platí CHYBICELK=1 a pro jejichž vstupní uzly platí CHYBICELK=0 nebo CHYBICELK>1, proveď OBJVYST-OBJVST ® objem trasy. Bylo-li provedeno alespoň jednou, pokračuj krokem 1, jinak krokem 4.
-
Pro všechny trasy s nezadaným objemem, pro jejichž vstupní uzly platí CHYBICELK=1 a pro jejichž výstupní uzly rovněž platí CHYBICELK=1, proveď A = (OBJVST - OBJVYST)VST ® objem trasy, B = (OBJVYST - OBJVST)VYST je objem trasou vstupující do jejího výstupního uzlu (=odtok z trasy) a A-B je tedy aktuální ztráta na trase. Bylo-li provedeno alespoň jednou, pokračuj krokem 1, jinak krokem 5.
-
Jsou-li nyní objemy ohodnoceny všechny trasy sítě, algoritmus končí úspěchem. Ne-li, končí neúspěchem.
Poznámka: Operací ® je myšlen dopočet objemu z uzlu vystupujícího danou trasou, přičemž se bere ohled na standardní ztráty v uzlu a na trase, případně se dopočte i ztráta trasy. Do dopočtené trasy přitom přiřadí indikaci "D".
Z algoritmu 3 je zřejmé, že jeho úspěch nebo neúspěch závisí na konfiguraci sítě a na tom, pro které trasy je objem znám při vstupu do algoritmu. V případě úspěchu je ohodnocení objemy hotovo. Případ neúspěchu je využíván před rutinním započetím používání vodohospodářského informačního systému. Dovoluje totiž určit trasy kritické z hlediska zadávání objemů vodohospodáři podniků. Vodohospodáři pak musí buď zajistit provedení kvalifikovaného odhadu pro (většinou jen některé) nedopočtené trasy, nebo od počátku změnit množinu jimi ohodnocovaných tras tak, aby algoritmus 3 končil úspěchem.
Poznámka: Algoritmus 3 by mohl být nazván metodou protlačování, nasávání a vyrovnání. Nejprve se voda "protlačí" do jediné neznámé výstupní trasy. Když není co protlačovat, zkouší se "nasávat" z jediné neznámé vstupní trasy. A když není ani co nasávat, zkouší se "vyrovnávat" rozdíl mezi protlačeným na jedné a nasátým na druhé straně.
V každém případě se v současném rutinním provozování předpokládá organizační i jiné zabezpečení toho, že výsledkem operací nad objemy vod v trasách je úplné ohodnocení tras sítě objemy (tedy algoritmus dopočtu končí úspěchem). Opačný případ ale nemá žádný fatální dopad na výsledky systémem produkované. Pouze do některých informačních výstupů nebudou zahrnuty trasy s nezadaným objemem.
Operace s látkovým znečištěním vod
Ohodnocením, jehož základním cílem je sledovat množství znečištění vypouštěné právním subjektem do vodních toků (ale i přenášené jiným právním subjektům), je především samo množství dané látky vztažené k nějakému časovému období. Toto množství však v řadě případů prakticky nelze měřit přímo. Určuje se proto zprostředkovaně výpočtem z objemu vod a látkové koncentrace. Problematika ohodnocení objemy je diskutována v předchozí podkapitole.
Konkrétní způsob výpočtu množství na základě objemů a látkové koncentrace je dán zákonem a zákonnými vyhláškami. Zde tedy jen zopakování podstatného:
-
Vzorky vod se odebírají v lokalitách vzorkování, které leží buď na trase sítě nebo v jejím uzlu. Tyto vzorky se analyzují předepsanými postupy, výsledkem analýz je hodnota látková koncentrace těch látek, pro něž se analýza provádí.
-
Je-li lokalita vzorkování v uzlu vodohospodářské sítě, vztahuje se koncentrace současně ke všem trasám sítě, které z uzlu vystupují, není-li na některé trase samotné lokalita vzorkování trasy.
-
Je-li lokalita vzorkování na trase sítě, vztahuje se k této trase a ve spojení s objemem na trase dovoluje určit, jaké množství dané látky bylo trasou dopraveno do jejího koncového uzlu.
Ze zákona je dáno, kde lokality vzorkování být musí (např. na výtoku odpadní vody z podniku do povrchového toku, případně do kanalizace). Podniky však zajímají i např. přenášené objemy znečištění na jejich území jinými podniky (toto množství znečištění mohou odečíst od vlastních pokut). Stanovují si tedy další lokality vzorkování, které však nemusí být přesně na trase v místě katastrální hranice, dokonce ani ne na "přechodové" trase samotné. Vyvstává pak požadavek určení koncentrace i množství znečištění pokud možno ve všech trasách vodohospodářské sítě.
Pokus o toto stanovení je analogický metodě protlačování, nasávání a vyrovnání uvedené v předchozí podkapitole o operacích nad objemy. Proto uvedeme způsob určení jen heslovitě. Je přitom užito symbolů U pro uzel sítě, T pro trasu sítě, M pro množství látky, m pro látkovou koncentraci stanovenou dle zákona a V pro objem vody jako nosiče znečištění. Určení se dělá postupně pro všechny látky, na něž byly vzorky vod analyzovány. Uvedené symboly se vztahují k jedné konkrétně určované látce.
-
Nejprve se spočtou množství M pro ty trasy, na nichž přímo leží lokality vzorkování a je tedy látkové znečištění známo přesně: M = m . V (stejně to platí pro trasy, které mají za počáteční uzel s lokalitou vzorkování a přebírají tedy jeho koncentraci).
-
Poté se znečištění "protlačí" do těch tras sítě, které jsou jako jediné neohodnocené koncentrací vzhledem ke svému počátečnímu uzlu U, přičemž uzel U je takový, ve kterém se nemění kvalita vody. Mějme jednu takovou trasu T. Množství látky dopravené do uzlu U jeho vstupními trasami je rovno Mvst = S mi . Vi pro i probíhající vstupní trasy uzlu U, množství znečištění odvedené výstupními trasami se známým ohodnocením koncentrací (tj. všemi výstupními trasami až na jedinou určovanou T) je analogicky Mvýst = S mi . Vi pro i probíhající výstupní trasy uzlu U kromě T. Množství látky v trase T je pak MT = Mvst - Mvýst. Koncentrace látky na trase je pak mT = M / V.
-
Následuje pokus o zjištění znečištění "nasátím" z těch tras sítě, které jsou jako jediné neohodnocené koncentrací vzhledem ke svému koncovému uzlu U, přičemž uzel U je takový, ve kterém se nemění kvalita vody. Mějme jednu takovou trasu T. Množství látky dopravené do uzlu U jeho vstupními trasami se známým ohodnocením koncentrací (tj. všemi vstupními trasami až na jedinou určovanou T) je rovno Mvst = S mi . Vi pro i probíhající vstupní trasy uzlu U kromě T, množství znečištění odvedené výstupními trasami je analogicky Mvýst = S mi . Vi pro i probíhající výstupní trasy uzlu U. Množství látky v trase T je pak MT = Mvýst - Mvst. Koncentrace látky na trase je pak mT = M / V.
-
Kroky 2 a 3 se opakují tak dlouho, pokud je co "protlačovat" a "nasávat".
-
Odlišný je další krok, kterým ještě není "vyrovnání". Kroky 2 až 4 se opakují analogicky pro ty uzly, z nichž vychází (resp. do nichž vstupuje) několik tras neohodnocených koncentrací. Množství znečištění se proporcionálně rozdělí podle množství objemů na jednotlivých neohodnocených trasách, tj. předpokládá se u nich stejná koncentrace. Protože tento předpoklad podle konzultací s vodohospodáři nemusí být za každé situace korektní, je možno krok 5 neprovádět.
-
Krok "vyrovnání" je v případě látkového množství nutno nazírat takto: analogicky kroku 2 se spočte množství, které by mělo do trasy vstupovat, analogicky kroku 3 se spočte množství, které by mělo z trasy vystupovat. Jsou-li množství rovná, je určení úspěšné. Nejsou-li rovna, znamená to, že na trase došlo k naředění nebo naopak zahuštění, určení končí neúspěchem, provozovatel obdrží zprávu o všech takových trasách a ve spolupráci s příslušným vodohospodářem učiní patřičné rozhodnutí: buď explicitně určí koncentraci, nebo taková trasa zůstane neohodnocena danou látkou.
Je zřejmé, že ne všechna ohodnocení koncentrací a látkovým množstvím jsou možná. Způsob stanovení resp. nestanovení je pak indikován v příslušné databázi a v informačních výstupech.
Informační výstupy
Výstupy ze systému jsou značně ekonomicky citlivé. Má k nim proto přístup pouze omezený okruh uživatelů, především vodohospodáři jednotlivých podniků. Informační výstupy systému jsou ve formátu stránek Internetu a v této elektronické podobě je mohou oprávnění uživatelé získat u provozovatele úlohy. Stránky s jednotlivými informačními výstupy tvoří hierarchický strom a lze jej prohlížet (a jeho jednotlivé části tisknout) kterýmkoliv "webovským" prohlížečem (Explorer, Netscape apod.).
Výstupy informačního systému jsou dvojího charakteru: výstupy pro vodohospodáře jednotlivých podniků (dále označované jako Podnikové výstupy) a výstupy pro hlavního vodohospodáře (dále označované jako Souhrnné výstupy). Informační výstupy se týkají jen jednotlivých podniků a data jiných podniků se v nich objeví jen jako údaje tras sítě překračujících hranice podniku. Souhrnné výstupy pak sumarizují data jednotlivých podniků podle skupin podniků: Českomoravské doly, OKD - a dále činné doly, doly v útlumu atd. Jsou sestaveny po skupinách podniků tak, jak je požaduje hlavní vodohospodář. Jak příslušnost podniku ke skupině, tak samotné skupiny podniků lze dynamicky měnit.
Podnikové výstupy obsahují např.:
- Základní ekonomické údaje
- Sumarizace vodohospodářských zpráv
- Příjem vody do podniku
- Bilance vlastních zdrojů
- Odtoky vod z podniku
- Distribuce pitné vody
- Bilance míst použití vody
- Vývoj použití vody
- Vlastní výroba vody
- Bilance vlastních ČOV
- Produkce znečištěné vody
- Seznam lokalit vzorkování
- Přehled hodnocení jakosti
- Rekapitulace rozborů
- Vyhodnocení rozborů
- Produkce znečištění dle různých kriterií
- Látkové znečištění dle různých kriterií
Souhrnné výstupy obsahují např.:
- Základní ekonomické údaje
- Odběry a vlastní zdroje vod
- Dodávky a vypouštění vod z podniku
- Bilance zdrojů upravených a recirkulovaných vod
- Bilance vlastních ČOV
- Bilance použití vody
- Produkce odpadních vod
- Provozní ztráty
- Přehled provedených rozborů
- Celková produkce znečištění
- Produkce znečištění dle různých kriterií
Závěr
Článek se pokusil naznačit problematiku monitoringu důlních a jiných znečištěných vod ve vodohospodářské sítě důlních podniků. Ukázal praktickou realizaci v prostředí relačních databází, zvláště modelování prvků z teorie grafů resp. sítí. Popisuje nejdůležitější aspekty informačního systému postaveného na teoretických základech jednak teorie grafů, jednak teorie dat obecně.
Informační systém je provozován pro důlní podniky Ostravsko - karvinské průmyslové aglomerace, v popsané podobě od roku 1998. Provozovatelem je DPB OKD Paskov, a.s. Uživateli jsou všichni vodohospodáři jednotlivých podniků, kteří každoročně získávají v tištěné podobě tabulkové výstupy systému doplněné komentářem provozovatele.
Z hlediska dat je systém připraven na širší využití. Po doplnění geologickými údaji by např. mohl být rozšířen o zhodnocení globálního znečištění důlními podniky a podniky na ně navazujícími nebo o geostatistické vyhodnoceních rizik znečištění v areálech podniků. Rovněž výstupní informace jsou připraveny na rozšíření dle požadavků uživatelů jak kvantitativně, tak zejména kvalitativně.
Rev. 09 / 2015