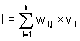
SQL a indexové hodnocení geo- jevů
Doc. Dr. Vladimír Homola, Ph.D.
V počítačovém prostředí je uloženo značné množství dat, převážně spravovaných relačními databázovými systémy. Pro některé způsoby jejich zpracování není zapotřebí používat nákladný specializovaný software. Dobře poslouží opomíjený, přesto velmi silný prostředek pro formulování dotazů do databází, Structured Query Language (SQL). Jeho hlavní součást, příkaz SELECT, je vhodným nástrojem jednak pro dotazy se seskupováním, jednak s kombinováním údajů v tabulkách. Příkladem prvního typu úlohy je hodnocení geo- jevů souhrnným indexem získaným z vážených ocenění jednotlivých faktorů spolupůsobících na jev. Příkladem druhého typu úlohy je tzv. “gridování”, tj. odhad hodnot v uzlech pravidelné sítě na základě hodnot v několika lokalitách terénu. V postupném použití dotazu nejprve jednoho, pak druhého typu spočívá např. hodnocení zranitelnosti akviferu povrchovým znečištěním. Pouhými dvěma dotazy je možno nejen provést vlastní hodnocení, ale i připravit data pro plošné nebo prostorové zobrazení standardním software. Na počítačích třídy PC je prakticky použitelný už i jen samotný MS Office: relační databázový systém Access a tabulkový procesor Excel.
In computer environment, there is a great amount of geo- data stored mainly in relational database tables format. Some particular methods of that data processing need not powerful, expensive specialized software systems. Structured Query Language (SQL), strong but unfamiliar data processing tool is sufficient for either grouping queries or combining queries. Index phenomenon evaluation based on weighted factor rates is the example of first type of such query. The second type represents gridding, i.e. estimation of net node values depending on known spatial data values. The only one SELECT query followed by the second one is sufficient for not only the proper enumeration, but data outputting in standard software packages format, too. In PC environment, Microsoft Office is usable for both data processing (Access) and graphic presentation (Excel).
Mezi zdroji geo- dat (uloženými v počítačovém prostředí databázových systémů) a koncovými informacemi (požadovaných odbornou veřejností) stojí programové vybavení. Jeho pořízení - zvláště software kategorie GIS - dnes představuje často násobky ceny samotných počítačů a ne vždy umožňuje analyzovat data právě tím způsobem, které požaduje uživatel.
Na druhé straně existují obecné nástroje pro formulování dotazů do relačních databází (které jsou nejčastější formou uspořádání obecných dat) dodávaných jako součást některého programového systému. Příkladem může být Structured Query Language (zkratka SQL) implementovaný jak v řadě operačních systémů přímo (Unix), tak formou různých programových mezivrstev (SQL server fy. Microsoft), ale i přímo ve většině RDBS (Oracle, SyBase, Informix, Access, Fox aj.).
Geo- data jsou charakterizována značným množstvím typů. Po konverzi reálných typů na typy dat databázových systémů se sice počet typů jako takových zmenší, ale hodnoty jednotlivých typů (byť stejných) zůstávají neporovnatelné.
Pro úlohy, které hodnotí úroveň nějakého geo- jevu (=“závisle proměnná”) na základě několika jiných, navzájem neporovnatelných geo- atributů (=“nezávisle proměnných”, faktorů), je možno použít metody výpočtu indexu jevu; jeho hodnota se pak stává hodnotícím kriteriem (závislého) jevu v relaci na (nezávislé) faktory.
Tato metoda je právě jednou z metod, která není přímo řešena ve specializovaných softwarových systémech. Přesto její použití pro hodnocení geo- jevů je rychle a jednoduše možné pomocí SQL tak, jak je to popsáno dále.
Matematická podstata metody je následující (viz také Homola, 1998):
Mějme n faktorů F1 až Fn. Každému faktoru Fi je přiřazena váha vi, což je obecně reálné číslo. Každý faktor Fi nabývá jedné z konečného počtu hodnot, které určují rozklad množiny všech hodnot faktoru na třídy. Faktor Fi tedy nabývá jedné z hodnot {Ti,1, Ti,2, … ,Ti,ki}. Každé třídě Ti,j každého faktoru Fi je přiřazeno ocenění wi,j, což je obecně reálné číslo.
Hodnotící index I je pak dán jako součet vážených ocenění.
| |
(1) |
kde se sčítá přes všechny faktory.
V praxi nebývá faktorů mnoho (do deseti) a samotný výpočet jednoho indexu podle (1) tedy není problém.
Dva problémy se však vyskytují jinde. Především se v praxi - zvláště v geo- vědách zkoumajících rozsáhlé plochy a geologická tělesa - nepožaduje výpočet jednoho, ale spíše statisíců indexů. To je problém praktický.
Teoretickým problémem je stanovení jednak samotných vah jednotlivých faktorů, jednak ocenění jednotlivých tříd tak, aby výsledný index odpovídal realitě v místech, kde je možno ocenění provést i přímým způsobem. Pro ověřování a “dolaďování” číselných hodnot vah a ocenění je opět zapotřebí provádět stovky a tisíce opakovaných výpočtů podle (1).
Z hlediska uvedených dvou problémů se výpočet podle (1) stává kritickým místem jak teoretické přípravy, tak praktického použití. Následující kapitoly ukazují využití SQL pro řešení tohoto problému mimo drahé softwarové produkty, které navíc jednoduché přímé řešení této úlohy neobsahují (pokud vůbec nějaké obsahují).
Poměrně široce se popisovaná metoda. uplatnila např. při hodnocení zranitelnosti akviferu (Aller, 1987); v US EPA je známa jako DRASTIC, její modifikace jako SINTACS. V obou aplikacích je použito sedmi faktorů.
Jako modelový příklad bude použito právě hodnocení zranitelnosti akviferu, ovšem v podobě redukované jak vzhledem k počtu faktorů, tak vzhledem k počtu tříd.
Nechť jsou tedy dány tři faktory:
Jest ohodnotit riziko, s jakým bude případné lokální povrchové znečištění infiltrovat směrem k podzemním vodám.
Je logické, že
Poznámka: Zájemci o právě tento problém najdou jeho úplnou aplikaci pro oblast Ostravy a Karviné v (Paganelli, 1996), obecnější pak v (Fabbri, 1995)..
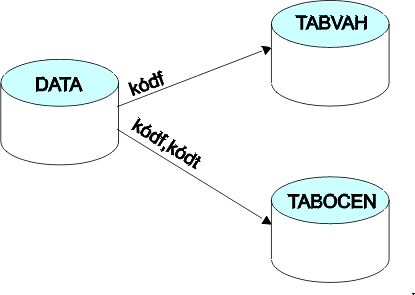
Obr. 1: Příklad datových vazeb
Protože dotaz SELECT umožňuje vytvořit relační datový model (dále jen tabulka) v podstatě libovolným výběrem z libovolných jiných tabulek, budou dotazy zde uváděné pracovat s tabulkami dat redukované struktury. Schéma datových vazeb uvádí předchozí obrázek (DATA - tabulka dat, TABVAH - tabulka vah, TABOCEN - tabulka ocenění):
Řídící datová tabulka přitom může mít např. následující strukturu (LOKALITA - kód lokality, KÓDF - kód faktoru zjištěného na dané lokalitě, KÓDT - kód třídy daného faktoru zjištěného na dané lokalitě):
| DATA | ||||||
| lokalita | kódf | kódt | lokalita | kódf | kódt | |
| A02 | P | gr | A31 | P | lm | |
| A02 | S | 02 | A31 | S | 02 | |
| A02 | V | 05 | A31 | V | 05 | |
| A04 | P | gr | A33 | P | lm | |
| A04 | S | 04 | A33 | S | 04 | |
| A04 | V | 05 | A33 | V | 05 | |
| A05 | P | gr | A37 | P | lm | |
| A05 | S | 02 | A37 | S | 02 | |
| A05 | V | 10 | A37 | V | 10 | |
| A07 | P | gr | A39 | P | lm | |
| A07 | S | 04 | A39 | S | 04 | |
| A07 | V | 10 | A39 | V | 10 |
Tab. 1: Příklad dat
Váhy jednotlivých faktorů mohou být uvedeny v následující tabulce (KÓDF - kód faktoru, FAKTOR - popis faktoru, VÁHA - váha daného faktoru):
| TABVAH | ||
| kódf | faktor | váha |
| P | Typ půdy | 2 |
| S | Sklon terénu | 1 |
| V | Vsak ze srážek | 4 |
Tab. 2: Příklad vah faktorů
Obdobně lze ocenění jednotlivých tříd jednotlivých faktorů umístit např. do tabulky (KÓDF - kód faktoru, KÓDT - kód třídy, TŘÍDA - popis třídy, OCENĚNÍ - hodnota ocenění dané třídy daného faktoru):
| TABOCEN | |||
| kódf | kódt | třída | ocenění |
| P | gr | Štěrky | 10 |
| P | lm | Hlíny | 5 |
| … | … | … | … |
| S | 02 | do 2% | 10 |
| S | 04 | od 2% do 4% | 9 |
| … | … | … | … |
| V | 05 | <50,100) mm | 3 |
| V | 10 | <100,150) mm | 5 |
| … | … | … | … |
Tab. 3: Příklad ocenění
Vazby ze souboru dat do “číselníků” vah a ocenění (viz obr. 1) jsou tedy zprostředkovány údaji ve sloupci kódf (do tabulky vah faktorů) a údaji ve sloupcích kódf a kódt (do tabulky ohodnocení tříd).
Vytvoření tabulky s indexy pro jednotlivé lokality provede např. dotaz
SELECT
lokalita, SUM (váha*ocenění) AS index
FROM data a, tabvah b, tabocen c
INTO TABLE indexy
WHERE a.kódf=b.kódf AND a.kódf=c.kódf AND a.kódt=c.kódt
GROUP BY lokalita
ORDER BY index
Výsledkem dotazu provedeného pro uvedená data je následující tabulka INDEXY:
| INDEXY | |
| lokalita | index |
| A05 | 50 |
| A07 | 49 |
| A02 | 42 |
| A04 | 41 |
| A37 | 40 |
| A39 | 39 |
| A31 | 32 |
| A33 | 31 |
Tab. 4: Výsledek dotazu
Největší index zranitelnosti akviferu (50) má podle toho lokalita A05, tj. lokalita tvořená štěrky, s minimálním sklonem a většími srážkami, zatímco nejmenší index zranitelnosti akviferu má lokalita A33 tvořená hlínami na svažitějším terénu a malými srážkami. Tato zjištění neodporují skutečnosti. Účelem článku však není diskutovat konkrétní použití, ale obecný mechanismus.
Poznámka: Výpočet indexu pro jedinou lokalitu (např. A37) provede stejný dotaz jako shora doplněný o podmínku
where
lokalita = ”A37” and ... ;
Předchozí odstavec ukázal výpočet indexů v konkrétních místech (bodech plochy). Zvláště v geo- vědách je často požadováno provést na základě hodnot nějaké veličiny v několika izolovaných bodech jisté oblasti odhad chování této veličiny v celé oblasti. Nechť jsou pro shora uvedené lokality známy také polohy v terénu dané souřadnicemi nějaké soustavy souřadné:
| POLOHA | ||||||
| lokalita | x | y | lokalita | x | y | |
| A05 | 4283 | 5516 | A37 | 4311 | 5498 | |
| A07 | 4294 | 5491 | A39 | 4302 | 5492 | |
| A02 | 4297 | 5509 | A31 | 4262 | 5503 | |
| A04 | 4318 | 5511 | A33 | 4276 | 5484 | |
Tab. 5: Polohy lokalit
Lokality jsou tedy umístěny v obdélníkové oblasti
[4260;5480] x [4320;5520]
Princip odhadů na ploše spočívá v pokrytí plochy obdélníkovou příp. čtvercovou sítí (o potřebné hustotě) a zjištění bodových odhadů ve všech uzlech sítě. Hodnoty v uzlech pak s přesností odpovídající hustotě sítě aproximují hodnoty plochy vyjadřující chování sledované veličiny na ploše.
Zjednodušeně pak zmíněný princip ukazuje následující obrázek:
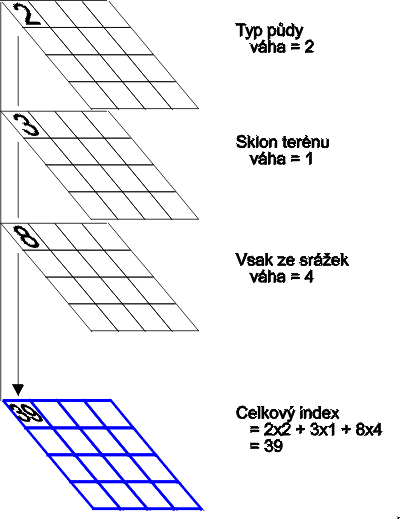
Obr. 2: Výpočet pro síť na ploše
Postup naznačený na předchozím obrázku je vhodný pro ty situace, kdy nejsou pro všechny lokality známy hodnoty všech faktorů. Pokud známy jsou, je výhodnější opačný postup: nejprve spočíst všechny indexy a teprve poté (jednou) provést odhady pro síť.
Síť pokrývající obdélníkovou plochu je dána množinou x-ových a množinou y-ových souřadnic svých uzlů. Mějme tyto hodnoty ve dvou tabulkách:
| XSIT | YSIT |
| x | y |
| 4260 | 5480 |
| 4265 | 5485 |
| 4270 | 5490 |
| 4275 | 5495 |
| 4280 | 5500 |
| 4285 | 5505 |
| 4290 | 5510 |
| 4295 | 5515 |
| 4300 | 5520 |
| 4305 | |
| 4310 | |
| 4315 | |
| 4320 |
Tab. 6: Určení sítě
Všechny uzly sítě jsou pak dány kombinacemi "každý z X s každým z Y".
Pro výpočet odhadů v uzlech lze použít např. metodu inverzní vzdálenosti, při níž je odhadovaná hodnota v uzlu P dána vztahem
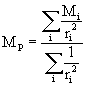 |
(2) |
kde i probíhá všechny známé body s hodnotami Mi a ri je vzdálenost i-tého známého bodu od uzlu P.
Vytvoření tabulky se všemi uzly sítě a odhady v nich provede dotaz
SELECT x, y,
SUM (index/((x-x0)^2+(y-y0)^2)) / SUM (1/((x-x0)^2+(y-y0)^2)) AS odhad
FROM xsit, ysit, indexy c, poloha d
INTO TABLE odhady
WHERE c.lokalita = d.lokalita
GROUP BY x, y
ORDER BY x, y
Výsledná tabulka má tvar
| ODHADY | ||
| X | Y | ODHAD |
| 4260 | 5480 | 35,85 |
| 4260 | 5485 | 35,61 |
| 4260 | 5490 | 35,26 |
| 4260 | 5495 | 34,19 |
| 4260 | 5500 | 32,62 |
| 4260 | 5505 | 32,42 |
| … | … | … |
Tab. 7: Odhady v uzlech sítě
a ve skutečnosti obsahuje všech 13 x 9 = 117 uzlových hodnot. Tuto tabulku lze pak dále zpracovat ať přímo relačními databázovými systémy (Oracle, Access, Fox) a tabulkovými procesory (Lotus, Excel), tak otevřením nebo importem do specializovaných systémů (GIS-y, Surfer, mapové systémy apod).
Článek ukázal na opomíjený, přitom levný a rychlý způsob zpracování a předzpracování dat bez nutnosti zakoupení a instalace drahého specializovaného software. Výhodou je standardizovaná údržba dat v běžně používaných tabulkách relačních databázových systémů (v systému DOS počítačů třídy PC soubory s příponou .DBF). Ty jsou bezproblémově přímo použitelné (nebo alespoň bezproblémově přenositelné) do všech komerčně úspěšných specializovaných systémů.
To dokumentuje následující obrázek. Tabulka ODHADY byla otevřena v Excelu a vykreslena jako prostorový graf (obr. 3).
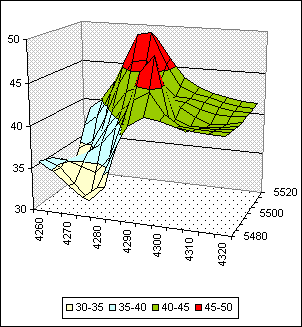
Obr. 3: Odhady hodnot na ploše
Stejně tak tabulka INDEXY může být zpracována dále numericky
i graficky např. systémem Surfer, jak to dokumentuje obrázek 4.
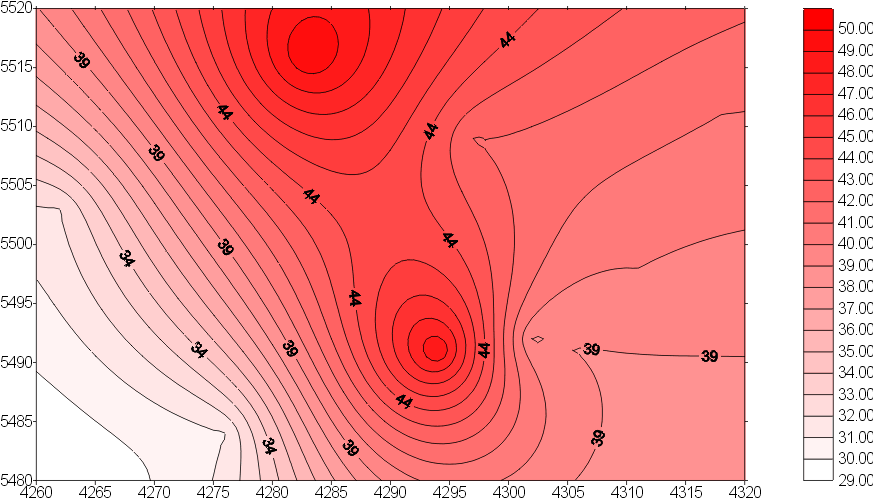
Obr. 4: Příklad zpracování
výsledku dotazu jako topografická mapa
|
Tento článek vznikl v polovině roku 1999 a revidován byl v polovině roku 2016, tedy po 17 letech. Během této doby se vyvíjel software, ale především hardware. Je zajímavé, že software se měnil v porovnání s hardware daleko méně zřetelně. Jistě, vznikly nové programové celky pokrývající nejrůznější oblasti života i vědních oborů. Avšak ten software, který vydržel v konkurenci, více méně zachoval svou logickou podstatu. Díky znásobené výkonosti hardware a dokonalejšímu prostředí operačních systémů byly přidány další výpočetní funkce, další typy např. výstupů, komunikace s uživatelem byla přizpůsobena rozhraní - ale vlastní podstata zůstala zachována. V kontextu tohoto článku to lze dokumentovat např. na výše zmíněném produktu Surfer firmy Golden Software. Databázový systém Fox je dnes Microsoft Visual Fox, ale vše co bylo shora popsáno, v něm beze změny pracuje. I uvedené příkazy samotného dotazovacího jazyka SQL lze po nepatrných úpravách využít v jiných databázových systémech. Co se však podstatně změnilo, je obrovský nárůst rychlosti zpracování. Článek původně končil následujícími odstavci. V roce 2016 jsou údaje uvedené v nich samozřejmě zcela nesmyslné. Autor však soudí, že takové ohlédnutí za minulostí může být nejen nostalgické, ale může naznačit i budoucí trendy. Jen pro ilustraci - popsaná úloha trvá v roce 2016 velmi těžko měřitelný zlomek sekundy. Nyní tedy původní text z roku 1999: |
Na závěr je vhodné se zmínit o rychlosti zpracování. První dotaz SELECT zde uvedený (vytvoření tabulky INDEXY) je vcelku bezproblémový, probíhá sekvenčně a i tisíce dat nejsou z časového hlediska kritické. Na druhé straně dotaz SELECT pro zjištění údajů na ploše už principielně je kvadraticky závislý na počtu dělení os.
Následující obrázek ukazuje závislost času výpočtu jednak na počtu dat (=zde lokalit), jednak na hustotě čtvercové sítě. Výpočet byl proveden na počítači třídy PC s procesorem Pentium 150MHz, 64MB vnitřní paměti - tedy na podzim’99 zcela průměrný počítač. Jako RDBS sloužil obyčejný FoxPro 2.0 spouštěný v prostředí Windows 95.
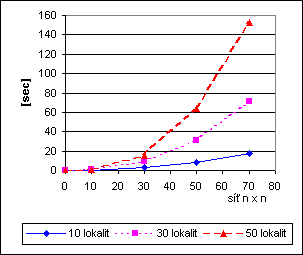
Obr. 4: Časy výpočtu
Pro zajímavost je dále uvedena tabulka časů výpočtu na tomtéž počítači pro síť 70 x 70 a 10 lokalit různými verzemi RDBS v různých prostředích. Časová závislost pro různý počet dat a různou hustotu sítě je proporcionální obrázku 4.
| RDBS | Prosředí |
Čas [sec]
|
| Access | Win95 |
36.2
|
| Fox 2.0D | Win95 |
17.5
|
| Fox 2.0D | DOS 6.2 |
13.9
|
| Fox 2.6W | Win95 |
13.2
|
| Fox 5.0W | Win95 |
10.1
|
| Fox 2.5D | DOS 6.2 |
9.1
|
Tab. 8: Časy výpočtu v různých systémech
Porovnání rychlosti provedení stejného dotazu SELECT jako shora v systémech Microsoft Access a Microsoft Fox 5.0 ukazuje následující tabulka:
| Síť n x n | Lokalit |
Access [sec]
|
Fox 5 [sec]
|
| 10 | 10 |
2,01
|
0,19
|
| 10 | 30 |
4,25
|
0,53
|
| 10 | 50 |
6,42
|
0,91
|
| 20 | 10 |
5,01
|
0,76
|
| 30 | 10 |
6,90
|
1,69
|
| 30 | 30 |
28,91
|
5,05
|
| 30 | 50 |
47,14
|
8,53
|
| 70 | 10 |
36,17
|
9,53
|
| 70 | 30 |
152,28
|
78,34
|
Tab. 9: Porovnání Access a Fox
Oba systémy byly spuštěny v prostředí Windows 95.
Aller L., Bennet T., Leher J. H., Petty R. J., Hackett G.: DRASTIC: A standardized system for evaluating groundwater pollution potential using hydrogeological settings. U. S. EPA 600 / 2-87-035. EPA 1987.
Fabbri, A. G.: The use of environmental indicators in the geosciences. ITC, Enschede. 1995.
Homola, V.: Geostatistika a teorie datových struktur. Disertační práce doktorandského studia. Ostrava, 1998.
van den Meer, F. D.: Introduction to Geostatistics. Enschede, ITC 1992.
Paganelli F.: Monitoring Spectral Characteristics of Vegetation in Karviná and Ostrava District. ITC Enschede, 1996.
Rev. 6 / 2016