Interpolace a extrapolace v rovině
Doc. Dr. Vladimír Homola, Ph.D.
Obecné úvahy
Mějme statistický soubor S s rozsahem N, přičemž každému prvku s Î S je přiřazena uspořádaná dvojice [x,y] dvou argumentů X, Y. Mluvíme pak o statistickém souboru se dvěma argumenty X, Y nebo také o dvourozměrném statistickém souboru s argumenty X a Y.
Takový statistický soubor bývá nejčastěji dán tabulkou mající dva sloupce X, Y a N řádků (=jednotlivých dvojic). Lze jej samozřejmě zkoumat metodami jednorozměrných statistik, tj. samostatně “sloupec” X a samostatně “sloupec” Y. Dvourozměrné statistické soubory se však vytváří právě za účelem zkoumání X a Y “dohromady”: ví se nebo se předpokládá, že X a Y nějak spolu souvisí a úkolem je tuto souvislost co nejpravděpodobněji popsat.
Z tohoto hlediska jsou zřejmé pojmy nezávisle a závisle statistická proměnná. Předpokládá se, že např. Y závisí na X a X nezávisí na Y. Jest tedy Y závisle proměnná, X nezávisle proměnná.
Takové pojetí má výhodu snadného grafického znázornění. Dvojice [x,y] lze totiž chápat také jako souřadnice bodů v rovině, na které je zavedena (např. kartézská) soustava souřadná. Vizualizací dvourozměrného statistického souboru je pak rovinný graf.
Mějme např. následující tabulku statistických dat:

Datům odpovídá následující rovinný graf:
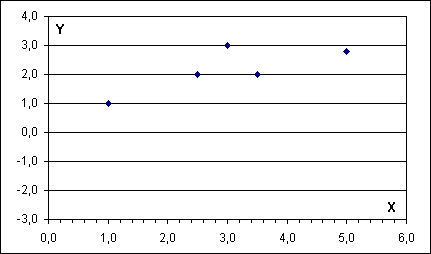
Na první pohled je zřejmé: se zvětšující se hodnou X se zvětšuje i hodnota Y přibližně “polovičním tempem”. Jistá závislost je tedy patrná.
V praxi se v souvislosti s dvourozměrnými statistickými soubory vyskytují dva typy úloh:
-
Zjištění závislosti Y na X
-
Zjištění hodnoty yk Î Y pro takové xk Î X, které není v tabulce dat.
Zjištění (nejlépe funkční) závislosti Y na X současně umožní i zjišťování neznámých hodnot – např. pouhým dosazením xk do rovnice funkční závislosti. Naopak zjištění hodnoty yk pro “nezadané” xk nemusí být vázáno na zjištění závislosti.
Problém ad A. řeší úlohy interpolace a extrapolace, problém ad B. řeší úlohy lokálních a globálních odhadů.
Interpolace a extrapolace
Obecná úloha interpolace:
-
Najít k funkci y=f(x) takovou funkci y=g(x), která nabývá pro n různých argumentů x1, x2, ... , xn stejných hodnot jako funkce f (tj. pro kterou platí f(xi)=g(xi) pro i=1, ... ,n).
-
Odhadnout nepřesnost náhrady hodnot funkce f(x) hodnotami funkce g(x) pro x ą xi.
-
Počítat z tabulky funkce yi = f(xi) přibližné hodnoty f(x) pomocí g(x) pro x ą xi.
Pro statistické účely se úloha interpolace definuje ve zjednodušeném tvaru; jest při tom xi Î X, yi Î Y:
-
Určit vhodnou funkci y=f(x) takovou, která v daných bodech (někdy nazývaných uzlové body) xi nabývá předem daných hodnot yi – tedy pro níž je yi=f(xi).
-
Počítat z tabulky funkce yi=f(xi) hodnoty f(x) pro x ą xi, x Î X, a prohlásit je za pravděpodobné hodnoty y Î Y.
-
Odhadnout nepřesnost takto zjištěného y pro x ą xi.
Pokud je při zjišťování y podle předchozího odstavce x Î < min {xi}, max{xi} >, jedná se o interpolaci. Je-li x < min {xi} nebo x > max{xi}, jedná se o extrapolaci. Funkce g(x) z obecné úlohy interpolace bývá nazývána funkcí, která aproximuje funkci f(x) na zadaném intervalu.
Polynomická interpolace
Polynom - mnohočlen - stupně k je obecně vyjádřen součtem
![]()
Polynomiální funkcí je pak analogicky
![]() (1)
(1)
Polynomická funkce stupně k má (k+1) koeficientů. Je-li tedy naopak známo (k+1) dvojic [xi, yi = f (xi)], kde f(x) je polynom stupně k, lze sestavit (k+1) lineárních rovnic o (k+1) neznámých koeficientech ai. Jejich řešením se získají koeficienty toho (jediného) polynomu stupně k, který danými k+1 “body přesně prochází”.
Aplikováno na statistický problém interpolace nastíněný shora: má-li tabulka dat [x,y] celkem n řádků (=je-li známo n “bodů”), pak existuje jediný polynom stupně n-1, který danými “body” přesně prochází. Řešme tedy soustavu
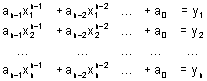 (2)
(2)
Až na případy singulární matice soustavy existuje jediné řešení [an-1, an-2, ... ,a0] koeficientů polynomu, který “přesně” prochází danými “body” [xi, yi].
Zdálo by se, že problém výpočtu hodnot v “neznámých místech” x na základě “známých míst” xi je vyřešen: známými n body proložíme polynomickou funkci stupně (n-1) a pak stačí jen dosazovat.
Teoreticky to jistě pravda je. Pokusme se uvedený postup aplikovat na data ve shora uvedené tabulce. Rozšířená matice soustavy je
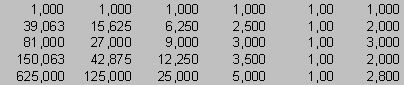
Jejím řešením jsou hodnoty koeficientů [a4, ... ,a0] polynomické funkce stupně 4, která je uvedena v následujícím grafu. Tamtéž je však patrný zásadní důvod praktické nepoužitelnosti tohoto postupu pro zjišťování pravděpodobných hodnot v “neznámých” místech: pokud data vyjadřují např. experimentálně zjištěné hodnoty délkové roztažnosti (Y) v závislosti na teplotě (X), pak záporná hodnota pro x=1.5 nebo x=4.5 je vysoce nepravděpodobná!
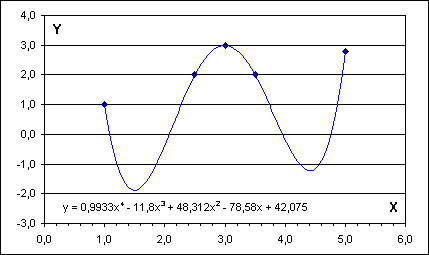
Uvedenou metodu je proto nutno aplikovat velmi uvážlivě.
Odhad hodnot lineární interpolací
Při lineární interpolaci je interpolační funkcí funkce lineární: y = f(x) = a.x + b (grafem této funkce je přímka). Obecně však pro daný statistický soubor taková přímka neexistuje (data by musela být kolineární, a to obecně nejsou). Lineární funkce má totiž dva parametry (a a b) a ty jsou jednoznačně dány dvěma dvojicemi [xi, yi] a [xk, yk] dat. Řešíme pak soustavu
yi = a . xi + b
yk = a . xk + b
Tomu odpovídá tvrzení Eukleidovské geometrie, že dvěmi různými body prochází jediná přímka. Pro různé dvojice dat statistického souboru pak existují různé lineární funkce.
Odhad hodnot metodou lineární interpolace především předpokládá, že statistická data jsou "seřazena podle X" (pokud ne, lze je evidentně takto uspořádat), tj xmin = x1 Ł x2 Ł .. Ł xn = xmax. Nechť jest odhadnout y0 = f(x0) pro nějaké x0Î <xmin, xmax>. Existuje-li i tak, že x0=xi, pak je odhadem y0=yi. Pokud ne, jistě existuje k tak, že x0 Î (xk, xk+1). Je logické předpokládat, že bude i y0Î (yk, yk+1). Dvojicí [xk, yk], [xk+1, yk+1] je určena jediná "přímka" - jediná lineární funkce y = a.x + b, jejíž koeficienty a a b se spočtou pomocí soustavy uvedené shora. Je pak odhad y0 y0 = a . x0 + b
Geometricky vzato, bod [x0, y0] leží uvnitř úsečky <[xk, yk], [xk+1, yk+1]>. Metoda lineární interpolace tedy místo přímky používá soustavu úseček tvořících lomenou čáru.
Právě z geometrického hlediska vyplývá druhý způsob výpočtu odhadu y0 (viz následující obrázek):
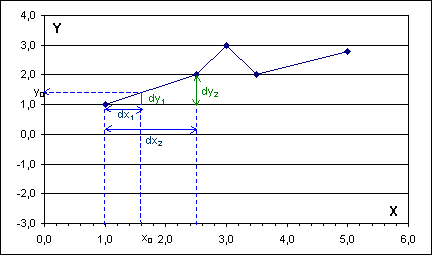
Z podobnosti trojúhelníků vyplývá rovnost
dy1 : dx1 = dy2 : dx2
(a podíl rovný oběma stranám rovnosti je mj. směrnice přímky, jejíž částí je první úsečka). Je tedy
dy1 = dy2 : dx2 . dx1
a proto
y0 = y1 + dy1 = y1 + dy2 : dx2 . dx1
Proveďme výpočet pro x0 = 1,6 tak, jak je to naznačeno na hořejším obrázku. Je x0 = 1,6 Î <1; 2,5>. Nejprve odhadněme y0 řešením dvou rovnic pro koeficienty přímky a dosazením do její rovnice. Je
1,0 = a . 1,0 + b
2,0 = a . 2,5 + b
Odečtením první rovnice od druhé je
1,0 = a . 1,5
a tedy a=2/3 a proto b=1/3. Rovnice přímky je
y = 2/3 . x + 1/3
Dosazením x0=1,6 je y0=1,4, což je v dobrém souladu s grafickým řešením.
Nyní druhým způsobem:
dy1 : (1,6 - 1,0) = (2,0 - 1,0) : (2,5
- 1,0)
dy1 : 0,6 = 1 : 1,5
dy1 = 0,4
y0 = 1,0 + 0,4 = 1,4
Interpolace vyšších řádů
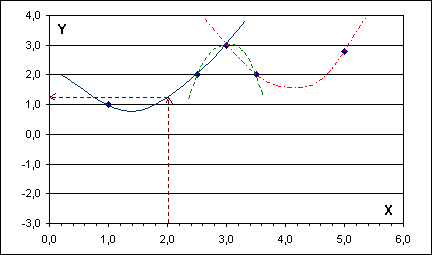
Zobecněním postupu uvedeného pro lineární interpolace získáme interpolace vyšších řádů. Jde však o postup mechanický, užívaný jen v odůvodněných případech. Princip vyplývá z obrázku uvedeného níže; používá interpolaci druhého řádu, tj. kvadratickou.
Analogicky k lineární interpolaci: při kvadratické interpolaci je interpolační funkcí funkce kvadratická: y = f(x) = a.x2 + b.x + c (grafem této funkce je parabola). Obecně však pro daný statistický soubor jediná taková parabola neexistuje. Kvadratická funkce má totiž tři parametry (a, b a c) a ty jsou jednoznačně dány třemi dvojicemi [xi, yi], [xm, ym] a [xk, yk] dat. Řešíme pak soustavu
yi = a . xi2 + b
. xi + c
ym = a . xm2 + b . xm + c
yk = a . xk2 + b . xk + c
Tomu odpovídá tvrzení, že třemi různými (nekolineárními) body prochází jediná parabola. Pro různé trojice dat statistického souboru pak existují různé kvadratické funkce.
Odhad hodnot metodou kvadratické interpolace především předpokládá, že statistická data jsou "seřazena podle X" (pokud ne, lze je evidentně takto uspořádat), tj xmin = x1 Ł x2 Ł.. Ł xn = xmax. Nechť jest odhadnout y0 = f(x0) pro nějaké x0Î <xmin, xmax>. Existuje-li i tak, že x0=xi, pak je odhadem y0=yi. Pokud ne, jistě existuje k tak, že x0 Î (xk, xk+1). Trojicí [xk, yk], [xk+1, yk+1], [xk+2, yk+2] (resp. [xk-1, yk-1], [xk, yk] , [xk+1, yk+1] pro poslední interval) je určena jediná "parabola" - jediná kvadratická funkce y = a.x2 + b.x + c, jejíž koeficienty a, b a c se spočtou pomocí soustavy uvedené shora. Je pak odhad y0 y0 = a . x02 + b . x0 + c
Geometricky vzato, bod [x0, y0] leží uvnitř segmentu paraboly <[xk, yk], [xk+1, yk+1]>. Metoda kvadratické interpolace tedy místo celé paraboly používá soustavu parabolických segmentů.
Splain křivky
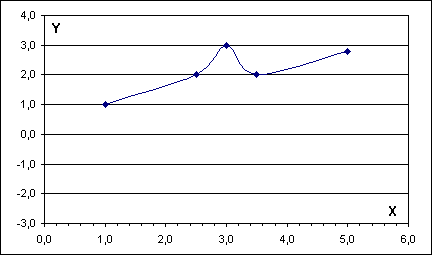
Odhady hodnot pomocí splain křivek patří k velmi populárním metodám zvláště při grafickém zobrazení, kdy jsou body "spojeny hladkou čarou". Metoda je značně náročná jak teoreticky, tak početně; proto je využívána nejvíce v počítačovém prostředí.
Princip je následující: vychází z interpolace pomocí - nejčastěji kubických - funkcí (viz předchozí kapitola). "Spojuje" tedy dvojice daných bodů segmenty kubické křivky (ten je dán čtyřmi body). Z prvních čtyř bodů se spočte kubická křivka a první dva body se spojí jejím segmentem. Pak se z druhého až pátého bodu spočte kubická křivka a druhé dva body se spojí jejím segmentem, atd.
Nevýhodou takového postupu je to, že v daných bodech na sebe jednotlivé segmenty "nenavazují hladce"; je tam prostě zub. Při konstrukci splain křivek je proto jednou z určujících podmínek pro výpočet jedné kubické křivky to, že v koncovém bodě jejího segmentu (např. [xp, yp]) má společnou tečnu se segmentem druhé, "následující" kubické křivky, jejímž je [xp, yp] bodem počátečním.
Matematicky je podmínka vyjádřena tím, že derivace zleva v xp jedné kubické funkce je rovna derivaci zprava v xp druhé kubické funkce. Problémem je však to, že pro určení té druhé musíme znát tu první, a to v okamžiku, kdy právě tu první počítáme. Právě proto jsou tyto algoritmy realizovány především programově.
Výsledný efekt ukazuje následující obrázek. Body tabulky jsou spojeny křivkou, přičemž body křivky byly spočteny splain interpolací.
Extrapolace
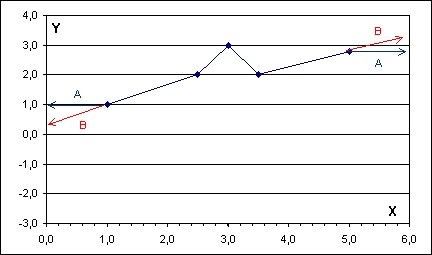
Extrapolací se provádí odhad hodnot pro x0 < xmin nebo pro x0 > xmax. Je nutno zdůraznit, že v praxi mají význam odhady jen "blízko" koncovým bodům intervalu <xmin, xmax>. Používá se dvou metod, přičemž jejich volba je dána povahou řešeného problému.
A. "Až do x1 jsou všechny y rovny y1 (od xn jsou všechny y rovny yn)":
y = f(x) = y1 pro x Ł
x1=xmin,
y = f(x) = yn pro x ł xn=xmax.
B. "Až do x2 se vše spočte jako pro <x1, x2> (už od xn-1 se vše spočte jako pro <xn-1, xn>)". Způsob výpočtu zde závisí na použité interpolační metodě (viz shora).
Rozdíl mezi oběma metodami ukažme na lineární interpolaci:
Rev. 10 / 2002