|
VŠB
|
TECHNICKÁ UNIVERZITA OSTRAVA |
HORNICKO GEOLOGICKÁ FAKULTA |
KATEDRA GEOLOGICKÉHO INŽENÝRSTVÍ |
Lineární regrese nelineární funkcí
Výukové materiály předmětu Statistika vč. programového řešení
doc. Dr. Vladimír Homola, Ph.D.
Ostrava 2019
Úvod
Častým dílčím cílem při výzkumu je odhalení dosud nepublikovaných závislostí mezi studovanými veličinami. K disposici jsou naměřená nebo jiným způsobem získaná data, kterých z ekonomických důvodů nemůže být libovolný počet (je jich tedy spíše méně než více). Konkrétní funkční závislost, kterou se zkoumané veličiny řídí a které odpovídají naměřená data, je dána jednak funkčním předpisem, jednak jeho konkrétními parametry (koeficienty). Pro daný funkční předpis existují postupy nalezení jeho koeficientů na základě daných dat. Některé z nich jsou relativně početně jednoduché, některé poměrně náročné (srov. lineární vs. nelineární regrese). Pro tento počtářský aspekt je dnes nabízena pro různá systémová prostředí řada programů.
Pro řešitele výzkumů, odborníky ne-matematického naturelu, je však kamenem úrazu funkční předpis. Málokterý z nich po zhlédnutí svých dat ihned prohlásí: to je ale krásná hyperbola říznutá sinusovkou ... S konkrétními funkčními předpisy pracovat dovedou, ale funkcionální analýza je jim přeci jen trochu vzdálená.
Tento článek obsahuje dva logické celky. První, teoretický, vysvětluje alespoň ve zjednodušené formě závěry tzv. metody nejmenších čtverců odchylek a její aplikaci na některé nelineární funkce. Druhý, praktický celek, popisuje jednu z možných programových aplikací vyhledávající z množiny 1369 různých funkcí y = f(x) se dvěma koeficienty tu, která má vzhledem k zadané množině dat {xi, yi} nejmenší součet kvadrátů odchylek. Tato aplikace je nabízena jako sešit formátu Excel a zpracovává data rovněž tohoto formátu.
Teoretická část
Poznámka: Tento článek přímo navazuje na kapitoly Lineární regrese a Lineární regrese funkcí se třemi parametry (viz).
Vymezení problematiky
Zopakujme nejprve závěr zmíněné kapitoly Lineární regrese funkcí se třemi parametry. Pro vztah z = z (x,y) tvaru
z = a × x + b × y + c
byla pro metodu nejmenších čtverců odchylek odvozena soustava normálních rovnic
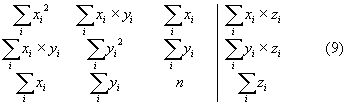
pro tři neznámé koeficienty a, b, c. V tomto případě pohlížíme na z jako na prostorovou funkci. Pro funkci y = y (x1, x2) má soustava normálních rovnic formálně stejný tvar jako (9) s tím, že nejprve místo x píšeme x1, pak místo y píšeme x2 a nakonec místo z píšeme y.
Tato myšlenka vede k velmi zajímavé metodě. Což kdyby se stejně formálně v (9) psalo místo x např. ex? Soustava (9) by pak měla tvar
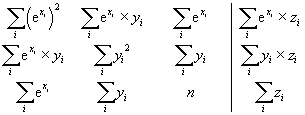
a byla by normálními rovnicemi ne pro funkční předpis
z = a × x + b × y + c
ale pro funkční předpis
z = a × ex + b × y + c
Když se dále místo z bude formálně psát z2 a místo y bude ln y, pak rovnice (9) budou mít tvar
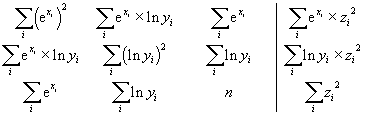
a příslušný funkční předpis bude
z2 = a × ex + b × ln y + c
což zapsáno pro z je
z = ²√ ( a × ex + b × ln y + c )
Tato funkce - přestože je sama nelineární - vede k lineární soustavě normálních rovnic.
Naznačenou metodu popišme obecněji. Jak bylo možno sledovat, místo x, y, z se zapisovaly nějaké jiné hodnoty X, Y, Z takové, že
X = j(x) Y = y(y) Z = s(z) (10)
Touto substitucí bylo dosaženo lineární soustavy normálních rovnic (9) v X, Y, Z. Jinak řečeno: jsme-li schopni k funkci
z = z (x, y)
nalézt takové funkce j resp. y resp. s, že platí
z = z (x, y) = s-1 ( a × j (x) + b × y(y) ) (11)
tj.
s (z) = a × j(x) + b × y(y)
pak při označení (10) po vyřešení soustavy
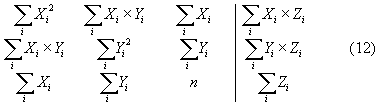
jsou nalezeny koeficienty a, b, c takové, že funkce (11) má právě s těmito koeficienty ze všech možných funkcí stejného tvaru nejmenší součet kvadrátů odchylek pro {j(xi), y(yi)}.
Závěrečný krok spočívá v rozšíření (10): na X nemusí být transformováno pouze x, ale jakákoliv funkční kombinace všech tří proměnných x, y, z. Rovnice (10) pak přechází na tvar
X = j(x, y, z) Y = y(x, y, z) Z = s(x, y, z) (13)
a upravený vztah (11) na tvar
s(x, y, z) = a × j(x, y, z) + b × y(x, y, z) + c (14)
přičemž zůstávají v platnosti všechna tvrzení kapitoly Lineární regrese funkcí se třemi parametry.
Vymezení množiny funkcí
Předchozí odstavec ukazoval teoretickou část pro případ prostorový (= tři veličiny), shodou okolností rovněž se třemi koeficienty. Pro aplikaci v níže uvedené praktické části se omezíme na analogický případ rovinný (= dvě veličiny) prostým snížením dimenze. Důvodem je především to, že z rovnice (jednodušší) rovinné křivky si přeci jen mnozí dokážou zjistit její průběh, tvar. Z rovnice prostorové plochy to však dokáže málokdo. Pro snadnější aplikaci soustavy normálních rovnic se omezme také na dva koeficienty.
Půjde tedy o případ
X = j(x, y) Y = y(x, y)
a upravený vztah tvaru
y(x, y) = a × j(x, y) + b
Další zjednodušení se týká transformačních funkcí j a y: Půjde o funkce jen jedné proměnné:
y(y) = a × j(x) + b
což - psáno ve tvaru pro y - dává
y = y-1 ( a × j(x) + b )
Soustava normálních rovnic má v tomto případě tvar
a × ∑ j2(xi) + b × ∑ j(xi) = ∑ j(xi) × y(yi)
a × ∑ j(xi) + b × n = ∑ y(yi)
Jejím řešením jsou koeficienty a, b takové funkce y=f(x), která vykazuje pro zadanou množinu {j(xi), y(yi)} nejmenší součet kvadrátů odchylek.
Mějme na paměti, že cílem je poskytnout prvotní informace o potenciálním vztahu dvou veličin za situace, kdy o tomto vztahu není naprosto nic známo. Samozřejmou myšlenkou vedoucí k nalezení tohoto vztahu je tato: Probereme všechny možné funkce, a dále budeme uvažovat tu s nejmenším součtem kvadrátů odchylek. Drobným problémem je, že funkcí i jen se dvěma koeficienty je nekonečně mnoho.
Proto pro praktickou aplikaci (nejen v programovém řešení) je nutno se omezit na konečnou množinu funkcí. Dále je vhodné uvažovat relativně jednoduché funkce. Konečně ještě jeden aspekt při volbě transformačních funkcí (zvláště pro transformaci y): V množině zkoumaných funkcí by měla být nejen funkce y zajišťující transformaci yi, ale i funkce k ní inverzní y-1 zajišťující výpočet f(xi). I když to není nutně zapotřebí, nic nebrání transformační funkci j volit ze stejné množiny.
Po úvaze byla zvolena množina těchto osmi jednoduchých funkcí:
| fi | Funkce | Popis | Omezení | Inverzní |
| 1 | x | Identita | x | |
| 2 | 1 / x | Reciproká hodnota | |x| > 10-36 | 1 / x |
| 3 | x2 | Druhá mocnina | |x| < 1018 | 2√x |
| 4 | 2√x | Druhá odmocnina | x ≥ 0 | x2 |
| 5 | x3 | Třetí mocnina | |x| < 1012 | 3√x |
| 6 | 3√x | Třetí odmocnina | x3 | |
| 7 | ex | Exponenciální funkce | |x| < 83 | ln x |
| 8 | ln x | Přirozený logaritmus | x > 0 | ex |
Může tedy být j = fp(x) a y = fq(y). Pro osm zvolených transformačních funkcí je tedy (teoreticky - viz níže) 8 x 8 = 64 různých funkcí tvaru
y = fq-1 ( a × fp(x) + b )
pro p ∈ <1,8>, q ∈ <1,8>.
Pokračujme však dále: fp(xi) transformuje i-tou datovou hodnotu veličiny x na hodnotu, kterou označme např. xip. Jistě nic nebrání tomu, aby tuto hodnotu transformovala další funkce fr na hodnotu
fr(xip) = fr(fp(xi))
- označme ji Xi. Zcela analogicky dojdeme dvojí transformací k hodnotě
Yi = fs(yiq) = fs(fq(yi))
Označení: Opusťme v dalším matematické značení typu yiq a používejme názornější, vyjadřující postavení každé ze čtyř transformačních funkcí:
- Txvni bude značit první "vnitřní" transformaci dat veličiny x,
- Txvne bude značit následnou "vnější" transformaci dat veličiny x,
- Tyvni bude značit první "vnitřní" transformaci dat veličiny y,
- Tyvne bude značit následnou "vnější" transformaci dat veličiny y.
Každou z veličin tedy můžeme podrobit jedné z 8 x 8 = 64 transformačních funkcí. Dohromady je k disposici (teoreticky) 64 x 64 = 4096 funkcí. Některé možné kombinace dvojic funkcí se však opakují. Je jedno, jestli se nejprve transformuje reciprokou funkcí a pak druhou mocninou nebo naopak. Vyloučením těchto duplicit se získá následující množina funkcí (zde pro x):
| Txvne
→ ↓ Txvni |
x | 1 / x | x2 | 2√x | x3 | 3√x | ex | ln x |
| x | x | |||||||
| 1 / x | 1 / x | e1/x | ||||||
| x2 | x2 | 1 / x2 | x4 | ex² | ||||
| 2√x | 2√x | 1 / 2√x | 4√x | e²√x | ||||
| x3 | x3 | 1 / x3 | x6 | 2√(x3) | x9 | ex³ | ||
| 3√x | 3√x | 1 / 3√x | 3√(x2) | 6√x | 9√x | e³√x | ||
| ex | ex | 1 / ex | e2.x | 2√(ex) | e3.x | 3√(ex) | eex | |
| ln x | ln x | 1 / ln x | ln2x | 2√(ln x) | ln3x | 3√(ln x) | ln ln x |
Množina funkcí pro transformaci veličiny y je totožná (v předchozí tabulce jen formální záměna x za y).
Transformovaná funkce tedy bude mít tvar, který vyjadřuje posloupnost provádění jednotlivých dílčích transformačních funkcí:
Tyvne ( Tyvni (yi) ) = a × Txvne ( Txvni (xi) ) + b
což v obecném tvaru s vyjádřením pro y dává
y = Tyvni-1 ( Tyvne-1 ( a × Txvne ( Txvni (xi) ) + b ) )
kde Tyvni-1 značí inverzní funkci k Tyvni, Tyvne-1 značí inverzní funkci k Tyvne.
Proto zajímavější tabulka než výše uvedené složené transformace pro y by byla tabulka funkcí právě ve vyjádření pro y. Ta by však musela obsahovat všech 342=1369 různých funkčních předpisů, což je v publikaci tohoto typu těžko typograficky řešitelné. Protože však oněch 8 základních transformačních funkcí je velmi jednoduchých, zvládne přepis na explicitní tvar i matematicky méně erudovaný čtenář. Uveďme jako příklad alespoň jednu z 1369 možností:
Tyvni = 2√y ( Tyvni-1
= y2 )
Tyvne = ey ( Tyvne-1 = ln y )
Txvni = x3
Txvne = 1 / x
pro funkci tvaru
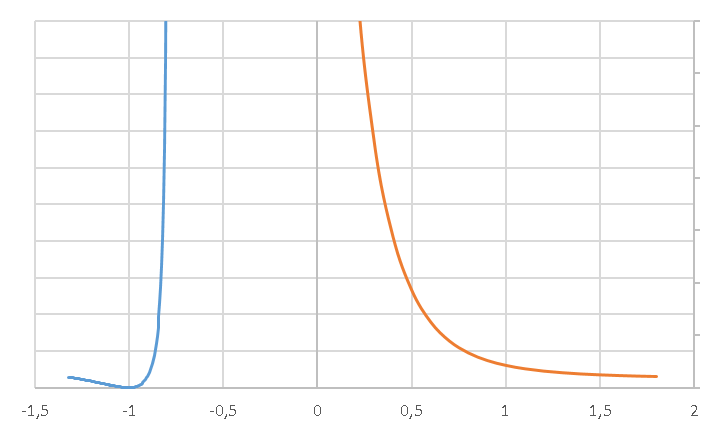
e²√y = a / x3 + b
Po logaritmování je
²√y = ln (a / x3 + b)
a po umocnění na druhou
y = ln2 (a / x3 + b)
Graf takové funkce (např. pro a=1, b=2) je následující (funkce není definována v intervalu (-³√(a/b); 0), v jehož krajních hodnotách má svislé asymptoty, vodorovnou asymptotu má v y=ln b):
Praktická část
Logika programového řešení
Teorie podaná výše byla aplikována v programovém řešení, které je možno stáhnout zde. Vychází přitom z následujícího:
- Nástroj pro výpočty musí být použitelný co nejjednodušeji, bez jakékoliv instalace.
- Data musí být uživatelem poskytnuta v co nejrozšířenějším formátu - takovém, jehož znalost lze předpokládat u většiny uživatelů.
- Ovládání - byť odpovídající shora popsané matematické teorii - musí být co nejjednodušší, pokud možno intuitivní, se standardními ovládacími prvky.
- Výsledky musí být uživateli dostupné bezprostředně, bez nějakého drastického pátrání typu "kde to proboha je".
- Výsledky musí být jednoduchým způsobem přenositelné do jiných systémů.
V současné době jsou nejrozšířenější a nejdostupnější výpočetní systémy třídy PC se systémy firmy Microsoft. Kancelářský "balík" Office této firmy v základní konfiguraci bývá předinstalován na nových počítačích, zaměstnavatelé běžně předpokládají u svých zaměstnanců znalost práce alespoň s jeho textovou (Word) a datovou a výpočetní (Excel) komponentou. Proto byla zvolena následující koncepce programového řešení:
- Kompletní programové řešení je soustředěno do jednoho sešitu otevíraného programem Excel. To zajišťuje bezinstalační provoz - uživatel prostě otevře sešit, který si stáhne z odkazu výše. Veškerá funkčnost se pak odehrává pouze v prostředí programu Excel.
- Zpracovávaná data jsou rovněž předkládána jako oblasti na listu (listech) sešitu. To je relativně obecný mechanismus, protože uživatel programu Excel má bohaté možnosti přístupu k datům v řadě nejrůznějších formátů a v řadě nejrůznějších zdrojů.
- Zadávání informací a požadavků je realizováno běžným formulářem s ovládacími prvky grafického rozhraní systému Windows, se kterými se uživatel setkává v tomto systému všude.
- Výstupy programového řešení jsou generovány do listů téhož sešitu, ve kterém jsou vlastní programy - uživatel tedy nemusí přecházet do jiných aplikací, zůstává pořád v prostředí jednoho otevřeného sešitu (tedy samozřejmě pokud nehodlá výsledky systémem CTRL/C - CTRL/V kopírovat jinam).
- Při každém otevření sešitu s programovým řešením se dříve vygenerované výsledky smažou - nedochází tedy k nepřehledné kumulaci dalších a dalších výsledků.
Pro uživatele
Po otevření
Po otevření sešitu uživatelem jsou provedeny inicializační akce a uživateli je předloženo prostředí prvního listu (je nazván lŘídící):
Dole nad stavovým řádkem jsou zobrazeny záložky všech listů: aktivní je první list, další listy (vyprázdněné při inicializaci) jsou připravené pro výsledky:

Dále mohou být na prvním listu zobrazena data uložená uživatelem při předchozím použití programu. Tato data se na rozdíl od dat na listech výsledků při inicializaci nemažou. Bezprostředně po stažení programu jsou na prvním listu data funkce y = e2/√x + 3 ± 5%, na kterých může uživatel vyzkoušet funkčnost:
Vlastní zpracování zahájí uživatel stisknutím tlačítka Inicializace a poté tlačítka Regrese - viz dále.
Definice dat a funkce
Zpracování jedné připravené množiny dat {xi, yi} zahájí uživatel stisknutím tlačítka Inicializace a poté stisknutím tlačítka Regrese.
Poznámka: Tlačítko Inicializace inicializuje proměnné programu, odstraní ze sešitu všechny listy kromě prvního, a pak znovu přidá (nyní už prázdné) čtyři listy pro výsledky. Tyto inicializační akce se provedou automaticky také bezprostředně po otevření sešitu. Následuje-li tedy hned po otevření sešitu požadavek na výpočet regresí, není nutno v tomto okamžiku tlačítko Inicializace použít.
Po stisknutí tlačítka Regrese je uživateli předložen následující formulář:
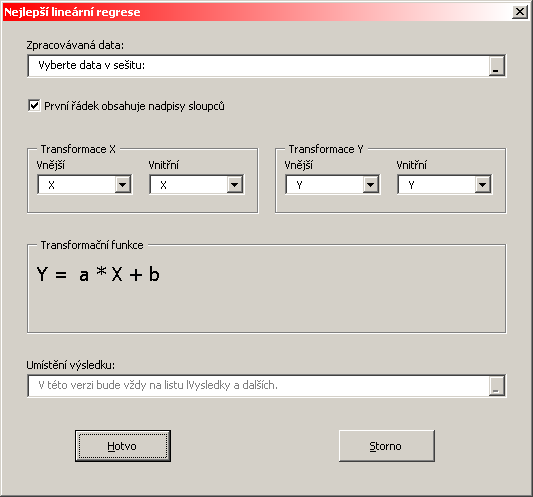
Jako první činnost uživatel vybere data připravená jako vstup zpracování. Výběr se provádí standardním mechanismem Excelu. Data {xi} veličiny X musí tvořit jeden sloupec, data {yi} veličiny Y musí tvořit druhý sloupec. Oba sloupce musí mít stejný počet numerických hodnot, ale nemusí tvořit spojitou oblast (tj. nemusí být vedle sebe). Oba sloupce (současně) mohou, ale nemusí mít ve svém prvním řádku nadpisy - pokud nemají, budou použity jednopísmenové texty X a Y. Informaci o přítomnosti nadpisů sdělí uživatel zaškrtnutím pole v horní části formuláře.
Pro hodnoty dat platí toto: Jestliže pro některé xi nebo yi nebude splněno omezení na transformovanou hodnoty v řetězci transformací (viz výše základní tabulka 8 transformačních funkcí), pak tato datová dvojice bude vyloučena ze zpracování.
Program posléze provede vždy jako svou první výpočetní činnost regresi jednou konkrétní funkcí - a to takovou, kterou uživatel definuje rozvíjecími seznamy Transformace X resp. Y:
Pokud uživatel tuto možnost nechce využít, pouze ponechá nabízené implicitní nastavení. Regrese jedinou funkcí se stejně provede, v takovém případě přímkou.
Při postupném výběru dílčích transformačních funkcí se průběžně zobrazuje tvar modelované funkce ve tvaru y=f(x). Není to sice obvyklý matematický zápis, ale protože jde o lineární zápis rovnice běžně používaný ve formulích Excelu, měl by být pro běžné uživatele srozumitelný.
Po vyplnění může mít formulář tento závěrečný tvar:
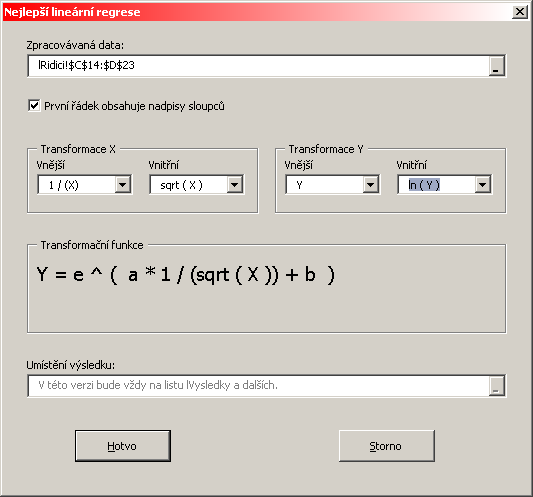
Tlačítkem Hotovo se programu oznámí dokončení vstupu uživatele. Program pak provede výpočty a generování výsledků, formulář se zavře a uživateli je zobrazena informace o ukončení výpočtů.
Vlastní výpočet a generování výsledků přeci jen jistou dobu trvá. Protože však tento interval na průměrném PC nepřesáhne cca 15 - 20 vteřin, laskavý uživatel snad nebude pociťovat absenci nějakého upozorňovadla.
Výsledky
Program během výpočtů generuje výsledky do připravených listů.
List označený lData obsahuje pro kontrolu kopii vstupních dat vybraných uživatelem, avšak již ve formátu dvou sloupců tvořících souvislou oblast (= vedle sebe).
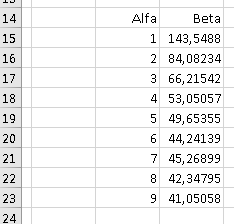
Do listu označeného lVýsledky jsou generovány detailní výsledky lineární regrese tou jedinou funkcí, kterou uživatel zvolil v parametrickém formuláři (viz shora). Formát a obsah jsou zřejmé z následujícího obrázku:
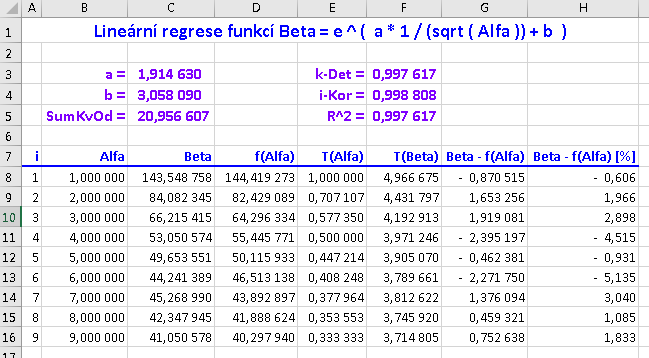
Poznámka k hořejší ukázce: Testovací data veličiny Beta jsou funkčními hodnotami funkce y = e2/√x + 3 náhodně změněné o ±5%. To zároveň alespoň částečně testuje program i metodu, protože koeficienty a resp. b by měly být blízko hodnotám 2 resp. 3.
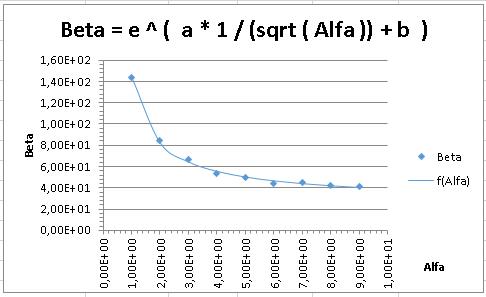
Do listu těchto je vedle numerického výstupu generován i graf:
Nejvíce informací je obsahem listu lNejlepší. Jsou zde výsledky regresí všech 1369 funkcí aplikovaných na danou množinu vstupních dat, seřazených vzestupně podle součtu kvadrátů odchylek (tedy funkce s nejmenším součtem kvadrátů odchylek je první). Vstupní data však mohou být v rozporu s některým funkčním předpisem - viz poznámka výše; tato data jsou ze zpracování takové funkce vyloučena a uživatel je o tom informován údajem nDat o skutečně zpracovaném počtu dat. Při případné interpretaci takové funkce musí být uživatel velmi obezřetný vzhledem k reálným veličinám, kterým odpovídají vstupní data.
Výstupní sestava má následující tvar:
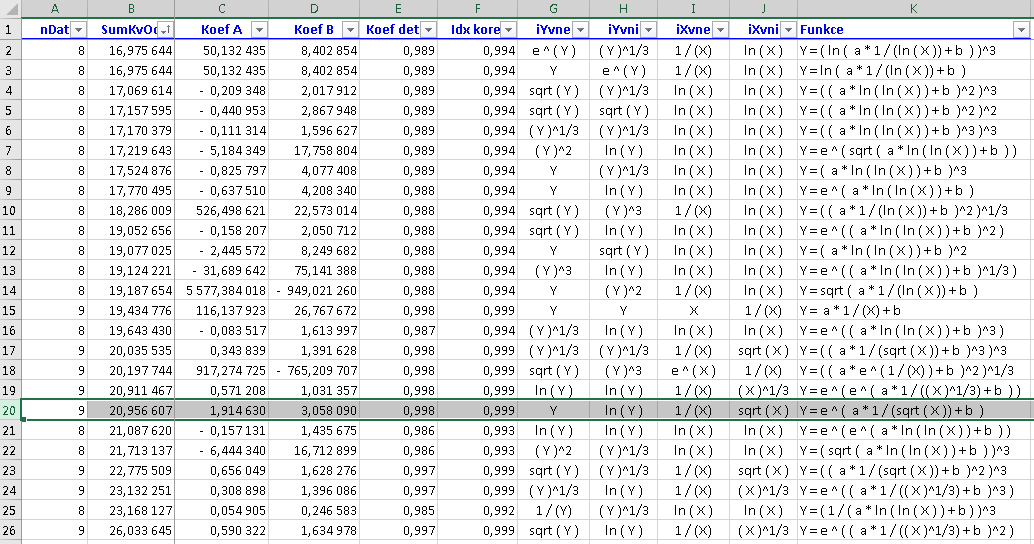
V této sestavě je zvýrazněn řádek s výsledkem té testovací funkce, pro níž (s rozptylem ±5%) byla vytvořena data. K tomu komentář:
- Z hlediska součtu kvadrátů odchylek je až na 19. místě v pořadí. Je však třeba vzít v úvahu, že z předchozích 18 funkcí byla u 14 z nich vyloučena při zpracování některá dvojice dat, proto výsledky pro ně jsou bez bližšího prozkoumání jak dat, tak funkcí samotných (ve vztahu ke zkoumaným veličinám) těžko relevantní.
- I tak zbývají 4 funkce dávající lepší součet kvadrátů odchylek. Tři z nich jsou poměrně složité (viz), ale hned první z nich má nejmenší součet kvadrátů odchylek a přitom jde o snad nejjednodušší hyperbolu.
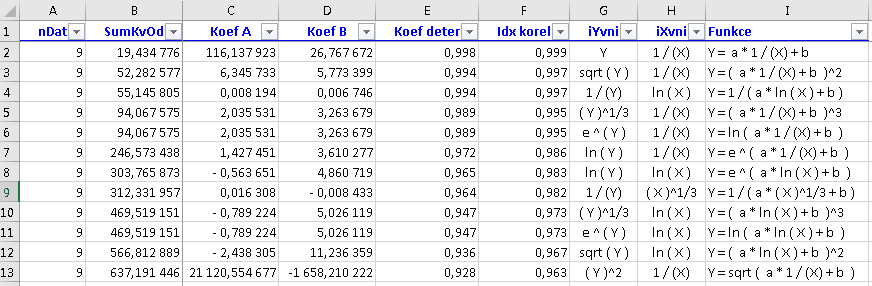
Poslední list s výstupy lJednoduché reflektuje právě uvedený komentář. V mnoha situacích totiž odborník hledající závislost mezi svými dvěma veličinami na počátku zvolí vztahy co jednodušší. Proto v posledním listu výsledků jsou uvedeny funkce ne se dvěma transformacemi každé ze dvou veličin, ale jen s jednou:
Programátorská část
Programové řešení je dostupné jako obvykle v editoru VBA spouštěného z prostředí otevřeného sešitu programem Excel. Struktura programového řešení je patrná v průzkumníku projektu:
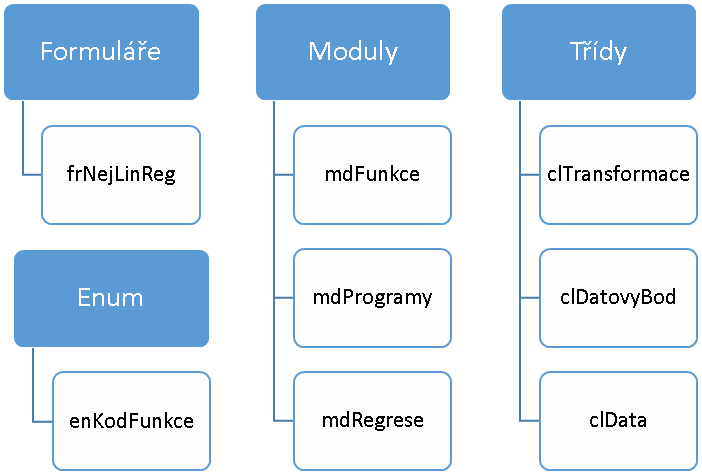
Protože vlastní kód není před zvídavým uživatelem nijak chráněn a je opatřen - podle mínění autora - celkem uspokojivými komentáři, v této části článku jen heslovitě.
Objektové třídy a Enum
Poznámka: Protože syntaxe VBA ještě neodpovídá celkem úplné implementaci objektového programování známého z Microsoft Visual Studií, je absence konstruktoru s parametry nahrazena veřejnou metodou Init. Tu tedy musí volající programové jednotky použít bezprostředně po volání New dané instance. Rovněž celá hierarchie objektových tříd by byla elegantnější a jednotlivé třídy jednodušší, kdyby VBA podporoval (ve vyšších verzích běžný) mechanismus dědění.
Enum
Pro účely programu jsou jednotlivé transformační funkce kódovány pomocí Enumerated Constants (Enum) nazvaných enKodFunkce, tedy celočíselnou čtyřbytovou hodnotou se znaménkem. Kódování je následující:

Zvoleno bylo z hlediska případného relativně jednoduchého rozšíření o další funkce. Proto je důležité číslování po jedné a zachování dvou jinak zbytečných hodnot fnull a ffinal: počet všech funkcí je totiž roven (ffinal-fnull-1) a cyklus od (fnull+1) do (ffinal-1) projde všechny funkce.
Třída clTransformace
Na nejnižší hierarchické úrovni je pak objektová třída clTransformace, jejíž veřejná datová pole uchovávají informaci o všech čtyřech transformačních funkcích.

Každá instance pak umí metodami třídy spočítat hodnotu ValueTx=tXvne(tXvni(x)) a ValueTy=tYvne(tYvni(y)), a také funkční hodnotu ValueInvTy = tYvni-1 ( tYvne-1 (A × tXvne (tXvni (x)) + B) ). Rovněž umí naplnit svá datová pole datovými poli jiné transformace (metoda CopyFrom).
Třída clDatovyBod
Každá instance reprezentuje jednu dvojici dat {x, y} spolu s transformací, která je na ni uplatněna. Pro - sice nepatrné ale přeci jen - urychlení při velkých objemech dat jsou jako veřejná datová pole přístupné již transformované hodnoty (např. TX = Transformace.ValueTx(X)).

Každá instance umí změnit přiřazenou transformaci a přitom přepočítat svá datová pole TX, TY.
Třída clData
Tato třída shromažďuje ve své privátní kolekci všechna uživatelem zadaná data jako instance výše popsané třídy clDatovyBod.

Moduly
Detailní popis jednotlivých modulů a programových jednotek v nich přesahuje rozsah této publikace. Proto jen stručný nástin obsahu modulů:
Modul mdFunkce
Modul obsahuje především programové jednotky typu Function použité při vyhodnocování jednak numerických hodnot, jednak při konstrukci textových popisů jednotlivých transformací apod. Součástí modulu je také definice konstant omezující operandy transformačních funkcí.
Skupiny funkcí slouží především pro
- numerické zpracování jednotlivých transformací a jejich inverzí,
- generování funkčních předpisů v textové podobě,
- řešení soustavy normálních rovnic,
- zpracování objektů nosné aplikace (tj. zde Excelu): listů, oblastí a dalších,
- podporu vzorců Excelu, kterou jako funkce nemá ve svých knihovnách,
- zajištění dynamického formátování a dalšího.
Modul mdProgramy
Obsahem modulu jsou programové jednotky typu Subroutine a Public konstanty a proměnné pro řízení programu a organizaci sešitu.
Skupiny podprogramů slouží především pro
- inicializaci sešitu a jeho re-inicializaci,
- zpracování informací z formulářů,
- organizaci dat označených uživatelem,
- realizaci algoritmů řazení,
- pro účely ladění různé testovací podprogramy a jiné.
Modul mdRegrese
Podprogramy tohoto modulu realizují vlastní zápis výsledků do listů sešitu, a to na základě naplněných instancí objektových tříd programovými jednotkami z předchozích modulů. Jde o
- výsledky regrese jedinou uživatelem určenou funkcí,
- výsledky regrese všemi relevantními transformačními funkcemi,
- výsledky regrese jednoduchými transformačními funkcemi.
Rev 09 / 2019