VYSOKÁ ŠKOLA BÁŇSKÁ - TECHNICKÁ UNIVERZITA OSTRAVA
Hornicko - geologická fakulta
Institut geologického inženýrství
Informatika pro Geovědní a montánní turismus
Učební texty předmětu Statistika a informatika - část Informatika

Ing. Jarmila Drozdová, Ph.D.
doc. Dr. Vladimír Homola, Ph.D.
Ostrava 2018
Recenzent: Prof. Ing. Ctirad Schejbal, CSc., dr. h. c.
Tvorba výukových materiálů „Informatika pro Geovědní a montánní turismus“ byla podpořena prostředky z grantového projektu IRP RPP2016/123 „Podpora tvorby multimediálních studijních materiálů pro bakalářské studium u předmětů vyučovaných Institutem geologického inženýrství“.
ISBN 978-80-248-4145-8
© VŠB-TU Ostrava 2018
Úvod
Geneze pojmu Informatika
Pojem Informatika je dnes naprosto běžně a suverénně používán. Přitom jen málokdo by zřejmě dovedl přesně vyjádřit, co si vlastně pod tímto pojmem představuje - a pokud ano, představy různých jedinců by byly vesměs různé. Proto nejprve ke genezi vlastního pojmu Informatika a vztahu k pojmu Počítačová věda.
Pozn.: Nejde o vlastní text autorů, ale o
volný přepis ze zdroje [3].
Prapůvod má informatika v knihovnických vědách. Ty podporují metody a postupy pro správu informací. Vztah k současnému chápání pojmu Informatika je možno sledovat od padesátých let s počátkem používání počítačů ve zdravotnictví [2 str. 4], které posilují vztah mezi vědou v knihovnictví a rozvojem informačních věd majících přínos pro rozvoj zdravotní informatiky. Dřívější praktici, kteří se o tuto oblast zajímali, brzy zjistili, že neexistují žádné formální vzdělávací programy, jejichž cílem je informovat je o vědecké informatice - a to až do pozdních šedesátých a počátku sedmdesátých let. Podle [1] je nyní zdravotnická informatika nejen aplikací výpočetní techniky na problémy ve zdravotní péči, ale pokrývá všechny aspekty generování, komunikace, ukládání, vyhledávání, správy, analýzy, objevování a syntézy datových informací a znalostí v celém rozsahu zdravotní péče. Dále uvedli, že primární cíl zdravotnické informatiky lze definovat takto:
Poskytnout řešení problémů souvisejících se zpracováním dat, informací a znalostí, a studovat obecné zásady zpracování dat a znalostí v medicíně a zdravotní péči.
Nový termín byl přijat napříč západní Evropou a - kromě angličtiny - mu byl přiřazen význam, který byl zhruba překládán anglickou "počítačovou vědou" nebo "výpočetní vědou". Михаилов (Michailov) obhajoval ruský termín Информатика (1966) a anglický Informatics (1967) jako názvy pro teorii vědeckých informací. Argumentoval širším významem včetně studie o využití informačních technologií v různých komunitách (například vědecké), a rovněž interakcí technologie a lidských organizačních struktur:
Informatika je vědní disciplínou, která zkoumá strukturu a vlastnosti (ne specifický obsah) vědeckých informací, stejně jako regulérnost vědecké informační činnosti, její teorii, historii, metodiku a organizaci.
Používání termínu Informatika od té doby změnilo tuto definici třemi způsoby. Za prvé je odstraněno omezení vědeckých informací, např. v oblasti podnikové informatiky nebo právní informatiky. Za druhé, protože většina informací je nyní digitálně uložena, je nyní centrem informatiky výpočetní zpracování dat. Za třetí, prezentování, zpracování a sdělování informací jsou přidány jako předměty studia, jelikož byly považovány za zásadní pro jakýkoli vědecký okruh informací. Získávání informací jako ústředního zaměření studia rozlišuje informatiku od počítačových věd. Informatika zahrnuje studium fyzických a sociálních mechanismů zpracování informací, zatímco počítačová věda se zaměřuje na digitální výpočet. Stejně tak ve studii o znázornění a komunikaci je informatika lhostejná k mediu, který nese informace. Zahrnuje například studii o komunikaci pomocí gesta, řeči a jazyka, jakož i digitální komunikace a vytváření sítí.
V anglicky mluvícím světě byl tedy termín informatika nejprve široce používán v komplexní medicínské informatice, zahrnující kognitivní, informační a komunikační úkoly lékařské praxe, vzdělávání a výzkumu včetně vědy o informatice a technologie podporující tyto úkoly. Mnoho takových okruhů se nyní používá - lze je považovat za různé oblasti "aplikované informatiky". Ve Spojených státech je však informatika spojena s aplikovanou výpočetní technikou nebo s výpočty v souvislosti s jinými doménami.
Informatika v tomto pojetí zahrnuje studium systémů, které reprezentují, zpracovávají a sdělují informace. Nicméně teorie výpočtů v specifické disciplíně teoretické počítačové vědy, která byla vyvinuta Alanem Turingem, studuje pojem komplexního systému bez ohledu na to, zda informace skutečně existují. Vzhledem k tomu, že obě oblasti zpracovávají informace, mezi vědci dochází k určité neshodě ohledně hierarchie pojmů. Např. Arizona State University se pokusila přijmout širší definici informatiky, která dokonce zahrnuje i kognitivní vědu při zahájení její School of Computing and Informatics v září 2006.
Širší interpretace informatiky jako "studie o struktuře, algoritmech, chování a interakcích přirozených a umělých výpočetních systémů" byla představena univerzitou v Edinburghu v roce 1994, kdy vznikla seskupení, které je nyní její School of Informatics. Tento význam je nyní (2006) ve Spojeném království stále častěji používán.
Výzkumné cíle pro rok 2008 britského UK Funding Councils zahrnují nový okruh "Počítačové vědy a informatika" (Computer Science and Informatics Unit of Assessment - UoA) pro hodnocení počítačových věd a informatiky, jehož rozsah je popsán následovně:
Tento okruh zahrnuje studium metod pro získávání, ukládání, zpracování, informování a uvažování o informacích, a rovněž studium role interaktivity v přírodních a umělých systémech prostřednictvím implementace, organizace a používání počítačového hardwaru, softwaru a dalších zdrojů. Předměty se vyznačují přísným uplatněním analýzy, experimentování a plánování.
Současné chápání dle Wikipedie
Podle [3] je informatika obor lidské činnosti, který se zabývá vznikem a zpracováním informací. Zahrnuje množství specializovaných vědních a technických oborů. Některé z nich lze charakterizovat následovně:
- Matematická informatika a ještě specializovanější teoretická informatika studují složité systémy, zpracování informací a používání počítačů s využitím technik aplikované matematiky, elektrotechniky a softwarového inženýrství.
- Informační technologie studují vše, co se týká fungování počítačů po technické stránce. Název je odvozen od slova informace, jelikož počítače nepracují s ničím jiným, než s daty, jejichž interpretací vznikají informace.
- Teorie informace je věda spojující aplikovanou matematiku a elektrotechniku za účelem kvantitativního vyjádření informace. Zabývá se bezeztrátovou kompresí (např. ZIP), ztrátovou kompresí (např. MP3), kapacitou přenosového kanálu (např. DSL).
- Informační věda, studium zpracování, správy a získávání informace.
- Bioinformatika je vědní disciplína, která se zabývá metodami pro shromažďování, analýzu a vizualizaci rozsáhlých souborů biologických dat, zejména dat molekulárně-biologických.
- Chemoinformatika spojuje vědecký výzkum v oboru chemie a výpočetní techniky.
- Geoinformatika je geoinformační (geografie + informatika) věda, zabývající se vývojem a aplikací metod pro řešení problémů geověd a příbuzných oborů, se specifickým důrazem na geografickou polohu objektů.
- Lékařská informatika (též biomedicínská informatika) je vědní obor který je na rozhraní informační vědy (dříve též jako informatiky) a medicíny.
- Neuroinformatika je vědní obor, zabývající se zpracováním a analýzou dat z oblasti neurověd za pomoci prostředků informatiky.
- Sociální informatika je transdisciplinární obor, zabývající se studiem designu, využití a důsledků informačních a komunikačních technologií v institucionálním a kulturním kontextu. Spojuje počítačovou vědu, informační vědu, informační systémy a sociální vědy.
Slovo „informatika“ je mnoha českými mluvčími považováno za zastřešující pojem, který v sobě zahrnuje jakékoli cílené zpracování informací (i bez použití počítačů), stejně jako určité oblasti používání počítačů a telekomunikací. Při tomto pojetí slovo „informatika“ odpovídá poměrně přesně německému die Informatik, v mnoha jazycích však pro něj nelze nalézt vhodný překlad. Anglické slovo informatics může být některými mluvčími považováno za synonymum computer science, čemuž v češtině odpovídá vědní obor matematická informatika.
V evropské vědecké komunitě však panuje širší shoda, že anglické slovo informatics je ekvivalentem slova computing a označuje souhrn všech disciplín zabývajících se výpočetní technikou či zpracováním informací s využitím počítačů. To znamená, že informatics není prostým synonymem ke computer science, což je pouze jedna z dílčích oblastí. Dalšími neméně důležitými oblastmi jsou např. informační systémy a informační technologie, které mají více aplikační charakter a v českém prostředí mohou být typicky vnímány jako součást tzv. "aplikované informatiky".
Cíle předmětu pro 1. ročník bakalářského studia
Jak je z předchozího textu patrno, je samotný pojem Informatika v názvu předmětu bez bližší specifikace nic neříkající. V dobách vzniku studijního oboru, kterému jsou tyto studijní materiály určeny, bylo vybavování škol výpočetní technikou v plenkách. Rýsovaly se však kontury vývoje jak hardware, tak i aplikačního software. V očekávání toho bylo zvoleno označení části předmětu právě termínem Informatika, aby jeho náplň mohla být dynamicky přizpůsobována aktuálnímu stavu.
Takové přizpůsobování mělo však v toku času své limity. V jisté době, kdy už chápání pojmu Informatika (viz shora) nabývalo hrozivých rozměrů, bylo nutno se omezit na několik málo přesně definovaných a velmi úzkých oblastí. Z hlediska studijního oboru to rozhodně nemohly být oblasti teoretické. Z hlediska kvality praktických návyků a znalostí, které si studenti prvního ročníku přinášejí ze středních škol (tedy od téměř nulových), byla zvolena tři témata. V následujícím studiu i budoucí praxi se jejich aplikace dnes automaticky předpokládá.
- Způsob uložení dat, týkajících se veličin reálného světa, v digitálním prostředí. Právě z toho vyplývá řada omezení např. na přesnost nejen následných výpočtů, ale i samotných ukládaných hodnot. To má zpětně vliv už na metodiku sběru dat a následně na interpretaci výsledků.
- Základní zásady publikační činnosti. Často lze pozorovat u nastupujících vysokoškolských studentů neschopnost vytvořit i jednoduchý dokument typu semestrální práce na jiné úrovni než nedostatečné. Mnoho bakalářských prací je pak hodno nedoporučení k obhajobě nikoliv pro závady obsahové, ale naprosto nepřijatelné závady formální.
- Základní zásady přípravy a zpracování textových, ale hlavně numerických dat. Jde o principy aplikačního software typu tabulkových procesorů. Je zarážející, když studenti 4. semestru příbuzného oboru zpracovávají u zkoušky data zadaná právě jako dokument tabulkového procesoru - na kalkulačce!
Tyto učební texty svou strukturou sledují uvedené tři oblasti.
Uspořádání učebních textů
Tyto učební texty jsou k disposici ve dvou základních formách:
- Jako "webovské" stránky dostupné na adrese geologie.vsb.cz v části Výukové texty.
- Jako soubor PDF respektující uspořádání tištěné podoby.
V prvním případě jsou jednotlivé kapitoly a odstavce přímo dostupné pomocí navigačního panelu vlevo.
Ve druhém případě mají texty strukturu obvyklou u běžných tištěných materiálů. Díky specifickému zaměření a díky zdroji (kterými jsou zmíněné "webovské" stránky) jsou však opomenuty některé typografické a nakladatelské zvyklosti. Markantním důsledkem je absence číslování obrázků, schémat a tabulek. Všechny tyto objekty mají odkaz na ně v bezprostředně předcházejícím nebo následujícím textu, bez přečtení a pochopení (!) tohoto textu jsou jak obrázky tak tabulky irelevantní. Proto chybí i obvyklý Seznam obrázků a Seznam tabulek.
Učební texty v každé své části respektují svým logickým uspořádáním propagovaný postup: Nejdříve teorie, pak praxe.
Díl I: Data v digitálním prostředí
Bit a byte
Základní pojmy níže uvedené jsou částečně vybrány a volně citovány z normy ISO 2382 (poměrně dobře jí odpovídá dřívější ČSN 36 9001).
Bit (z anglického binary digit - dvojková cifra, zkratka b): cokoliv, co nabývá pouze dvou hodnot a "počítač" je schopen rozeznat, kterých. Příklad: zrnko materiálu je nebo není zmagnetované; tranzistor proud vede nebo nevede; žárovka svítí nebo nesvítí. Protože tyto dvě hodnoty jsou protikladné, bez ohledu na fyzikální podstatu se chápou jako NEPRAVDA a PRAVDA, NE a ANO apod. V těchto učebních textech však budou používány ve svém původním významu, tj. jako cifry 0 a 1 dvojkové soustavy. Aby nedošlo k záměně s běžně používanou soustavou desítkovou, používá se někdy i symbolů O a I.
Byte (kdysi překládáno jako slabika, dnes se "bajt" většinou vůbec nepřekládá, zkratka B): posloupnost osmi bitů = dvojkových cifer. Jsou-li bity vyjádřeny jako 0 a 1, pak je jeden byte uspořádanou osmicí nul a jedniček a tvoří tedy poziční zápis osmiciferného čísla ve dvojkové soustavě. Těchto (různých) osmic je 256, počínaje např. 00000000, pak 00000001, ..., až po 11111110 a 11111111. Dvojková čísla zde uvedená (ve dvojkové soustavě) odpovídají následujícím číslům (v desítkové soustavě): 0, 1, ..., 254, 255. Graficky je možno jeden byte znázornit např. takto:
| Byte: | ||||||||
| Obsah | O | O | O | I | O | O | I | O |
| bitu č. | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Bity v rámci bytu mají svoji adresu (jsou "očíslované"), která odpovídá příslušné mocnině základu soustavy, zde tedy mocnině 2.
Paměť: Uspořádaná množina bytů přístupná výpočetnímu systému. Fyzická realizace je různá: uspořádání ve formě diskety, pevného disku, magnetické pásky, integrovaného obvodu apod. Bez ohledu na fyzickou realizaci jsou paměti nazírány jako linearizovaná (a tedy "očíslovatelná") posloupnost bytů. Očíslování bývá provedeno počínaje nulou, tato "pořadová" čísla se nazývají adresy jednotlivých bytů. Na paměť je tedy možno pohlížet např. takto:
| Paměť: | ||||||||
| Obsah | OIIOIOIOO | OIIOIOIOI | OOIIIIIO | OIIOIOII | OIIIIOOIO | OIIIOOIO | IIIOOOOOI | ... |
| bytu s adresou: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ... |
Kilobyte, Megabyte, Gigabyte, Terabyte a další: jednotky pro udávání velikosti paměti (tisíc, milion, miliarda, bilion bytů).
Poznámka 1: V občanském životě je např. předpona kilo- spojena s hodnotou přesně 1000. Ve dvojkovém počítačovém prostředí se však lépe pracuje s hodnotou 1024, protože ta je rovna 210, tedy dvojkově 1 a deset nul. Pro rozlišení se "občanské" předpony zapisují malými písmeny, kdežto "počítačové" velkými. "Občanským" se říká "malé kilo" atd, kdežto "počítačovým" se říká "velké kilo"; analogicky ostatní jednotky. Je tedy kB, mB, gB a tB přesně tisíc, milion, miliarda a bilion bytů, kdežto KB, MB, GB a TB je 1 024, 1 048 576, 1 073 741 824 a 1 099 511 627 776 bytů, což je 210, 220, 230 a 240 bytů.
Poznámka 2: Autoři si jsou vědomi toho, že někdy kolem roku 2004 byla převzata norma u nás označovaná jako ČSN-IEC-60027-2, která ponechává "malým" jednotkám jejich původní název a označení (tedy např. kilobyte = kB), kdežto pro "velké" jednotky zavádí názvy "kibibyte", mebibyte", "gibibyte" atd. a označení KiB, MiB, GiB atd. - viz také [5]. Autoři však poznamenávají, že s tímto označováním se kromě Wikipedie a zmíněné normy v praktickém životě nesetkali.
Datový typ: způsob chápání obsahu jednoho, dvou nebo více po sobě následujících bytů v paměti.
Semilogaritmický zápis čísla je zápis číselné hodnoty ve tvaru součinu celého nebo necelého čísla a mocniny základu (např. 10) - známý např. z kalkulaček, tj. ve tvaru M x zE, např. 1,2 x 103 (=1200). Část M je nazývána mantisa, část E je nazývána exponent.
Normovaný semilogaritmický zápis čísla: Každou nenulovou hodnotu lze zapsat pomocí semilogaritmického zápisu tak, že celá část mantisy má jedinou, a to nenulovou cifru (stačí příslušně upravit exponent) - např. 123.456 x 1020 = 1.23456 x 1022. Takovému zápisu se říká normovaný a jeho analogie ve dvojkové soustavě se využívá při ukládání neceločíselných hodnot v paměti.
Binární minimum
Binární (= dvojková) soustava definuje takový poziční zápis číselných hodnot, při kterém je jako základ soustavy použita hodnota 2. Hexadecimální (= šestnáctková) soustava definuje takový poziční zápis číselných hodnot, při kterém je jako základ soustavy použita hodnota 16. Minimální informace o těchto soustavách podejme na základě analogie s běžně používanou soustavou dekadickou (= desítkovou). Připomeňme jen trochu pozapomínanou skutečnost, že zápis čísla (v jakékoliv soustavě) slouží k vyjádření počtu nějakých jednotek resp. jejich částí.
Desítková soustava
Dekadická (= desítková) soustava používá takový poziční zápis číselných hodnot, při kterém je jako základ použita hodnota 10. Zopakujme, proč je 348 rovno právě 348: je to proto, že tato hodnota obsahuje 3 stovky (stovka = 102), 4 desítky (desítka = 101) a 8 jednotek (jednotka = 100). Zapsáno jinak:
| 102 (= 100) | 101 (= 10) | 100 (= 1) | celkem | |||
| x 3 | + | x 4 | + | x 8 | = | 348 |
Nyní rozšiřme opakování o to, proč je 348,65 rovno právě 348,65:
| 102 (= 100) | 101 (= 10) | 100 (= 1) | 10-1 (= 0,1) | 10-2 (= 0,01) | celkem | |||||
| x 3 | + | x 4 | + | x 8 | + | x 6 | + | x 5 | = | 348.65 |
Podotkněme jen, že správně by všechna čísla v tomto odstavci zapisovaná měla být důsledně označena základem své soustavy; místo 348 by tedy mělo být lépe zapsáno 34810. Zatím však byla použita jen desítková soustava a tedy se "to nepletlo".
Poslední připomenutí: v zápise čísel může být právě tolik různých hodnot daného řádu, kolik je základ soustavy. To znamená např. žádnou stovku, jednu stovku, dvě stovky, ..., osm stovek nebo devět stovek. Deset stovek už ne, protože to by byla jedna tisícovka ("přechod přes řád"). Pro znázornění těchto deseti různých hodnot je zapotřebí deseti jakýchkoliv, ale různých symbolů. V našich končinách a našem věku bývá zvykem používat symboly 0, 1, 2, ..., 8 a 9.
Dvojková soustava
Jde o poziční číselnou soustavu se základem 2. Analogii s desítkovou soustavou začněme "od konce": v zápise čísel může být právě tolik různých hodnot daného řádu, kolik je základ soustavy (tj. dvě). To znamená např. žádnou dvojku nebo jednu dvojku; dvě dvojky už ne, protože to by byl "přechod přes řád". Pro vyjádření těchto dvou různých hodnot je zapotřebí dvou různých symbolů. Bývá zvykem používat symboly 0 nebo O (pro počet žádný) a 1 nebo I (pro počet jeden).
Každý zápis číselné hodnoty ve dvojkové soustavě proto může obsahovat pouze symboly 0 a 1. Je tedy např. 1001 jistě zápis číselné hodnoty ve dvojkové soustavě. Aby bylo zcela jasné, že jde o zápis právě ve dvojkové soustavě, zapisuje se v nejednoznačných případech hodnota jako 10012 nebo IOOI2 na rozdíl např. od 100110.
Protože většina z nás je zvyklá chápat počty vyjádřené zápisem čísla jen v desítkové soustavě, vysvětlíme způsob převodu zápisu nějaké (např. uvedené 1001) číselné hodnoty ze dvojkové do desítkové soustavy. Je analogicky jako shora
| 23 = 810 | 22 = 410 | 21 = 210 | 20 = 110 | celkem | ||||
| x 1 | + | x 0 | + | x 0 | + | x 1 | = | 910 |
Obdobně zápis necelého čísla - nejde dost dobře říci ani "desetinného" čísla ani čísla s "desetinnou částí" - např. 1001,0112:
| Celá část |
, |
"Necelá" část | celkem | |||||||||||
| 23 = 810 | 22 = 410 | 21 = 210 | 20 = 110 | 2-1 = 1/210 = 0,510 | 2-2 = 1/410 = 0,2510 | 2-3 = 1/810 = 0,12510 | ||||||||
| x 1 | + | x 0 | + | x 0 | + | x 1 | + | x 0 | + | x 1 | + | x 1 | ||
| 8 | + | 0 | + | 0 | + | 1 | + | 0 | + | 0,25 | + | 0,125 | = | 9,37510 |
Opačný převod - tj. převod zápisu nějaké číselné hodnoty ze soustavy desítkové do soustavy dvojkové - spočívá v postupném zkoumání, kolikrát se v čísle vyskytují jednotlivé mocniny dvou. Ukažme tento postup např. pro číselnou hodnotu 1910:
-
Nejnižší mocnina dvou, která se v 1910 už nevyskytuje, je pátá: 25 = 3210. Začneme tedy čtvrtou mocninou:
-
Čtvrtá mocnina 2 (24 = 16) se v 19 vyskytuje 1krát a zbude 310.
-
Třetí mocnina 2 (23 = 8) se v 3 vyskytuje 0krát a zbude 310.
-
Druhá mocnina 2 (22 = 4) se v 3 vyskytuje 0krát a zbude 310.
-
První mocnina 2 (21 = 2) se v 3 vyskytuje 1krát a zbude 110.
-
Nultá mocnina 2 (20 = 1) se v 1 vyskytuje 1krát a zbude 0.
Hodnota 1910 je tedy rovna 100112.
S ohledem na probíranou problematiku ještě jedna poznámka: obsah jednoho bytu může být interpretován jako zápis právě osmiciferného dvojkového čísla. Nejmenší číselná hodnota je osm nul, tedy nula. Největší číselná hodnota je osm jedniček. Postup uvedený shora dává pro hodnotu 111111112 desítkový ekvivalent
111111112 = 27 + 26 + 25 + 24 + 23 + 22 + 21 + 20 = 128 + 64 + 32 + 16 + 8 + 4 + 2 + 1 = 25510
Všech různých obsahů jednoho bytu je tedy 256.
Šestnáctková soustava
Jde o poziční číselnou soustavu se základem 16. Pro zápis číselné hodnoty v této soustavě musí tedy být k disposici 16 různých symbolů, označujících počty nula, jedna ... až patnáct. Ve shodě s teorií čísel se tyto symboly nazývají cifry a celá současná počítačová civilizace používá následující:
| Cifry šestnáctkové soustavy | ||||||||||||||||
| Symbol | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| Počet | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
Způsob převodu zápisu hodnoty v šestnáctkové soustavě do soustavy desítkové je zcela analogický předchozímu odstavci - jediný rozdíl je v základu, který je nyní 16. Ukažme to na příkladu hodnoty 2AF316 (značí A počet 10 a F počet 15 - viz předchozí tabulka):
| 163 = 409610 | 162 = 25610 | 161 = 1610 | 160 = 110 | celkem | ||||
| x 2 | + | x 10 | + | x 15 | + | x 3 | = | 10 99510 |
Šestnáctková soustava je nejčastěji používanou soustavou v počítačovém a vůbec digitálním světě. Velmi usnadňuje a zpřehledňuje zápis stavů paměťových elementů, které jsou fyzikálně tvořeny dvoustavovými konstrukčními prvky (generalizovanými jako bity). Platí totiž toto: cifry šestnáctkové soustavy označují počty 0 až 15 podle definice. Ovšem počty 0 až 15 jsou rovněž všemi hodnotami, které tvoří kombinace různých hodnot v zápisu 4-bitového čísla: od 00002 = 010 do 11112 = 8 + 4 + 2 + 1 = 1510. Je-li tedy např. obsah jednoho bytu chápaný jako osmiciferné dvojkové číslo, pak hodnota v něm uložená lze zapsat právě 2 ciframi šestnáctkové soustavy:
| Byte: | |||||||||
| Obsah | I | O | I | O | O | I | I | O | |
| šestnáctkově. | A | 6 | |||||||
Zápis hodnot jednotlivých bytů je nejčastějším použitím šestnáctkové soustavy. Zatímco ve dvojkové je zapotřebí 8 cifer, v šestnáctkové jen 2 - a to je daleko přehlednější. Místo intervalu hodnot uchovatelných v jednom bytu zapsaných ve dvojkové soustavě <00000000; 11111111> je jistě zápis v šestnáctkové soustavě <00; FF> příjemnější. Z tohoto příkladu jeden důležitý závěr: protože F je nejvyšší cifrou šestnáctkové soustavy, je FF největší dvoucifernou hodnotou zapsanou v šestnáctkové soustavě. Je přitom FF16 = 15 x 16 + 15 x 1 = 15 x 17 = 25510.
Známým příkladem použití zápisu hodnoty v šestnáctkové soustavě je kódování barev v HTML souborech: parametr color = #RRGGBB určuje barvu jako trojici intenzit základních barev (po řadě R = red = červená, G = green = zelená, B = blue = modrá), každá ve stupních intenzit od 0 do 255, zapsaných jako šestnáctkové číslo. Tedy kód #FF00FF znamená: červená složka naplno, zelená není, modrá naplno - dohromady tedy barva fialová (magenta).
Datové typy
Jednou z nejdůležitějších charakteristik výpočetních systémů je to, s jakými datovými typy dovedou pracovat - jak dovedou pohlížet na obsah jednoho nebo více po sobě jdoucích bytů a tento obsah příslušným způsobem interpretovat. V tomto článku jsou diskutovány pouze numerické datové typy. Názvy datových typů uváděných v tomto článku nejsou univerzální a liší se podle kontextu použití; v textu tohoto článku jsou jako názvy typů použity identifikátory z programovacích jazyků C, Basic event. Java, konkrétně C++, Visual Basic (VB) a J# z edice Microsoft Visual Studio 2010 a novějších.
Celočíselné datové typy
Byte bez znaménka
Datový typ označovaný v C++ jako unsigned char a ve VB jako Byte je takové chápání obsahu jednoho bytu, při kterém je nazírán jako osmice dvojkových cifer (osmiciferný zápis dvojkové hodnoty) a tedy jako nezáporné celé číslo. Takových různých hodnot je 256, hodnotami datového typu byte jsou všechna čísla od 0 do (desítkově) 255 - viz závěr odstavce Dvojková soustava.
| Byte bez znaménka: | ||||||||
| Obsah | I | O | O | O | O | I | O | I |
| bitu č. | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Pozn.: Desítková hodnota čísla z tohoto příkladu je 1 x 27 + 1 x 22 + 1 x 20= 133.
Byte se znaménkem
Datový typ označovaný v C++ jako signed char nebo také jen char a ve VB jako SByte (signed byte) je takové chápání obsahu jednoho bytu, při kterém je první bit zleva (bit č. 7) považován za znaménko a ostatní bity v počtu 7 (v prvním přiblížení) jako absolutní hodnota. Příklad:
| Byte se znaménkem: | ||||||||
| Obsah | I | O | O | O | O | I | O | I |
| bitu č. | 7 = znam. |
6 | 5 | 4 | 3 | 2 | 1 | 0 |
Pozn.: Desítková hodnota čísla z tohoto příkladu je podle striktní interpretace shora uvedené definice následující: absolutní hodnota je 1 x 22 + 1 x 20= 5, ale protože 7. bit není nulový, měla by být hodnota rovna -5. Tvůrci procesorů však uvažovali dál: pokud by to bylo skutečně takto, pak nuly budou dvě: jedna kladná a jedna záporná, což je totéž. Jde tedy jedna kombinace bitů v bytu využít pro další hodnotu. To lze udělat dvěma způsoby - viz níže odstavec Záporná celá čísla. Byte se znaménkem se ukládá ve dvojkovém doplňkovém kódu, proto zahrnuje interval hodnot <-128, +127>,
2 byty bez znaménka
Datový typ označovaný v C++ jako unsigned short a ve VB jako UShort (unsigned short integer) je takové chápání obsahu dvou po sobě jdoucích bytů, při kterém jsou jejich bity nazírány jako šestnáctice dvojkových cifer (šestnácticiferný zápis dvojkové hodnoty) a tedy jako nezáporné celé číslo. Takových různých hodnot je 65 536, proto hodnotami tohoto datového typu jsou všechna čísla od 0 do (desítkově) 65 535. Graficky lze jednu hodnotu tohoto typu znázornit např. takto:
| 2 byty bez znaménka: | ||||||||||||||||
| Obsah | I | O | O | O | O | I | O | O | O | O | O | I | O | O | O | I |
| bitu č. | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | O |
Pozn.: Desítková hodnota čísla z tohoto příkladu je 1 x 215 + 1 x 210 + 1 x 24 + 1 x 20 = 33 809.
2 byty se znaménkem
Datový typ označovaný v C++ jako signed short nebo také jen short a ve VB jako Short (short integer) je takové chápání obsahu dvou po sobě jdoucích bytů, při kterém je první bit zleva (bit č. 15) považován za znaménko a ostatní bity v počtu 15 (v prvním přiblížení) jako absolutní hodnota. Příklad:
| 2 byty se znaménkem: | ||||||||||||||||
| Obsah | I | O | O | O | O | I | O | O | O | O | O | I | O | O | O | I |
| bitu č. | 15 = znam. |
14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | O |
Pozn.: Desítková hodnota čísla z tohoto příkladu je podle striktní interpretace shora uvedené definice následující::absolutní hodnota je 1 x 210 + 1 x 24 + 1 x 20 = 1 041, ale protože první bit zleva (bit č. 15) není nulový, měla by být hodnota rovna -1 041. Platí tady však stejná poznámka jako u typu Byte se znaménkem (viz) a stejný odkaz na odstavec Záporná celá čísla. Dva byty se znaménkem se ukládají ve dvojkovém doplňkovém kódu, proto zahrnuje interval hodnot <-32768, +32767>,
4 byty bez znaménka
Datový typ označovaný v C++ jako unsigned long a ve VB jako UInteger je takové chápání obsahu čtyř po sobě jdoucích bytů, při kterém jsou nazírány jako dvaatřiceticiferné dvojkové číslo (analogie typu 2 byty bez znaménka - viz). Hodnoty tohoto datového typu se pohybují od nuly až po trochu více než +4 miliardy. Přesně to je interval <0 ; +4,294,967,295>.
Logika uložení je zcela ekvivalentní uložení typů Byte a UShort (viz), ovšem v paměťovém prostoru 4 bytů.
4 byty se znaménkem
Datový typ označovaný v C++ jako signed long nebo také jen long a ve VB jako Integer je takové chápání obsahu čtyř po sobě jdoucích bytů, při kterém je první bit zleva (bit č. 31) považován za znaménko a ostatní bity v počtu 31 (v prvním přiblížení) jako absolutní hodnota (analogie typu 2 byty se znaménkem - viz). Platí tady však stejná poznámka jako u typu 2 byty se znaménkem a stejný odkaz na odstavec Záporná celá čísla. Čtyři byty se znaménkem se ukládají ve dvojkovém doplňkovém kódu, hodnoty tohoto datového typu se pohybují od trochu méně než -2 miliardy až po trochu více než +2 miliardy. Přesně to je interval <-2,147,483,648 ; +2,147,483,647>.
Logika uložení je zcela ekvivalentní uložení typů SByte a Short (viz), ovšem v paměťovém prostoru 4 bytů.
8 bytů bez znaménka
Datový typ označovaný v C++ jako unsigned long long a ve VB jako ULong je takové chápání obsahu osmi po sobě jdoucích bytů, při kterém jsou nazírány jako šedesátičřtyřciferné dvojkové číslo (analogie typu 2 byty bez znaménka - viz). Hodnoty tohoto datového typu se pohybují od nuly až po trochu více než 1,8 x 1019 nebo také 16 milionů Terra. Přesně to je interval <0 ; +18,446,744,073,709,551,616>. Takto velká paměť by měla 16 777 216 TB.
Logika uložení je zcela ekvivalentní uložení typů Byte a UShort (viz), ovšem v paměťovém prostoru 8 bytů.
8 bytů se znaménkem
Datový typ označovaný v C++ jako signed long long nebo také jen long long a ve VB jako Long je takové chápání obsahu osmi po sobě jdoucích bytů, při kterém je první bit zleva (bit č. 63) považován za znaménko a ostatní bity v počtu 63 (v prvním přiblížení) jako absolutní hodnota (analogie typu 2 byty se znaménkem - viz). Platí tady však stejná poznámka jako u typu 2 byty se znaménkem a stejný odkaz na odstavec Záporná celá čísla. Osm bytů se znaménkem se ukládá ve dvojkovém doplňkovém kódu, hodnoty tohoto datového typu se pohybují od trochu méně než -9 x 1018 až po trochu více než +9 x 1018. Přesně to je interval <-9 223 372 036 854 775 808 ; +9 223 372 036 854 775 807>.
Logika uložení je zcela ekvivalentní uložení typů SByte a Short (viz), ovšem v paměťovém prostoru 8 bytů.
Záporná celá čísla
Pro úsporu jedné kombinace bitů při uchování celého čísla v paměti (nula je nulou ať kladná nebo záporná) se využívají dvě techniky: dvojkový doplňkový kód a kód posunuté nuly.
Dvojkový doplňkový kód
V tomto režimu je první bit zleva považován za znaménkový. Je-li roven nule, je číslo kladné a zbývající bity vyjadřují přímo jeho hodnotu. Má-li se zaznamenat číslo záporné, pak se nejprve provede operace binární negace (záměna nul a jedniček) absolutní hodnoty, načež se výsledek zvětší o 1.
Příklad pro hodnotu N = -910 na jednom bytu: abs (N) = 910 = 000010012, jehož dvojková negace je 111101102 a hodnota o 1 větší je 111101112. To je tedy zobrazení hodnoty -9 na jednom bytu ve dvojkovém doplňkovém kódu.
Procesory Intel a další používají tento způsob např. pro zpracovávaná, přímo adresovatelná data.
Kód posunuté nuly
V tomto režimu není uložena přímo číselná hodnota N, ale tato hodnota zvětšená o vhodnou konstantu K Uložena je tedy hodnota T = N + K. Konstanta je volena tak, aby výsledek byl už vždy nezáporné číslo. Pro získání skutečné hodnoty N je tedy naopak třeba provést operaci N = T - K.
Volba konstanty se řídí velikostí paměťového prostoru určenému pro uložení celého čísla. Typicky se za konstantu volí hodnota získaná vyplněním určeného paměťového prostoru samými 1 kromě prvního bitu zleva, který se nastavuje na 0.
Příklad pro hodnotu N = -910 na jednom bytu: konstanta K pro 8 bitů je rovna 011111112 = 12710. Uložena je tedy hodnota T = -9 + 127 = 11810 = 011101102. To je tedy zobrazení hodnoty -9 na jednom bytu v kódu posunuté nuly
Procesory Intel a další používají tento způsob např. pro exponentovou část při uchování čísla v pohyblivé řádové čárce.
Neceločíselné datové typy
Obecně o formátu uložení
Složitější je takový datový typ, který má vyjadřovat také ne-celé číslo (záměrně se vyhýbáme terminu desetinné číslo). V počítačovém prostředí nejrozšířenější je způsob definovaný standardem IEEE 754 (Institute of Electrical and Electronics Engineers) pro binární aritmetiku v pohyblivé řádové čárce. Je to takové chápání obsahu několika po sobě jdoucích bytů, při kterém jsou byty nazírány jako tři skupiny bitů. První skupinou je první bit zleva chápaný jako znaménko celého čísla. Druhou skupinou je několik bitů chápaných jako celé číslo a označovaných jako exponent. Třetí skupinou je několik bitů chápaných (a označovaných) jako mantisa. Ve finální interpretaci jde o zápis dvojkového čísla v normovaném semilogaritmickém tvaru (viz nahoře a také [6]). Graficky lze logiku uložení jedné hodnoty tímto způsobem znázornit na příkladu dvoubytového uložení čísla např. takto:
| Binary 16 dle IEEE-754-2008 | ||||||||||||||||||||
| I | I | O | O | I | O | I | . | O | I | O | O | O | O | O | O | O | O | |||
| znaménko | exponent | myšlená cifra I | mantisa | |||||||||||||||||
První bit zleva je chápán jako znaménko Z celého čísla: O znamená kladné, I záporné číslo. V příkladu na obrázku shora tedy jde o číslo záporné.
Další skupina bitů slouží k uchování exponentu E. Jako formát uložení je použit způsob s kódem posunuté nuly (viz předchozí kapitola). Konstanta K posunu je rovna kladné celočíselné hodnotě získané vyplněním všech bitů exponentové části jedničkami kromě prvního bitu zleva, který je vyplněn nulou. Na obrázku shora je tedy konstanta K rovna 011112 = 1510. Protože hodnota uložená v exponentové části je rovna 100102 = 1810, je exponent E = 18 - 15 = 3.
Nyní k části M pro mantisu: jak bylo uvedeno shora v kapitole Bit a byte, lze každou hodnotu v jakékoliv soustavě zapsat v normovaném semilogaritmickém tvaru - tedy takovém, kdy celá část mantisy má jedinou, a to nenulovou cifru. Ve dvojkové soustavě tedy touto cifrou musí být jednička. Jestliže má popisovaný způsob vést k normovanému semilogaritmickému tvaru, pak každá uchovaná hodnota (kromě nuly) musí mít jako celou část mantisy jedničku - ale v tom případě je zbytečné ji explicitně v datech uchovávat. Proto tato jednička je pouze "myšlená", uvažuje se s ní při převodech, ale sama se nezaznamenává. Na obrázku shora je tedy mantisa M rovna 1.012 = 1 + 1/2-2 = 1,2510.
Samotná uložená hodnota je pak rovna H = ± M x 2E. Na obrázku shora tedy je uložena hodnota -1.25 x 23 = -1,25 x 8 = -1010.
Formáty FPU procesorů Intel a jejich klonů
Následující tabulka upřesňuje shora uvedený obecný model uložení pro konkrétní typ procesoru. Datové typy Single (z angl. Single Precision Floating Point) a Double používá většina programovacích jazyků, typ Extended je použit také např. jako interní pracovní datový typ FPU procesorů Pentium a dalších.
| Název v C++ / VB | Délka [bytů] | Část exponentu [bity] | Konstanta K posunu | Část mantisy [bity] | Maximální hodnota | Minimální nenulová hodnota | Max. počet platných cifer |
|---|---|---|---|---|---|---|---|
| float / Single | 4 | 30 až 23 | 127 | 22 až 0 | 3.40E+38 | 1.4E-45 | 7 |
| double / Double | 8 | 62 až 52 | 1023 | 51 až 0 | 1.79E+308 | 4.9E-324 | 17 |
| nemá / nemá | 10 | 78 až 64 | 16383 | 63 až 0 | 1.18E+4932 | 3.6E-4951 | 20 |
Typ Decimal
Tento datový typ se používá pro přesné uložení speciální podmnožiny racionálních čísel. Vychází vstříc finančníkům, pro které je nemožnost přesného uložení např. jednoho haléře jako 0.01[Kč] zcela nepředstavitelná. Je bázováno desítkovou soustavou, ovšem v binárním uložení. Typ Decimal je často realizovaný softwarově a tedy zpracovávaný neskonale déle než předchozí hardwarové typy.
Mějme celočíselnou hodnotu C, mějme nezápornou celočíselnou hodnotu D. Vytvořme racionální číslo X takto: X = C / 10D. Je-li D=0, je tedy X=C, jinak je X rovno hodnotě C s desetinnou tečkou (čárkou) v jeho desítkovém zápisu "posunutou doleva" o D míst.
Hardwarové uložení hodnot čísla X tohoto typu využívá 128 bitů = 16 bytů paměti. Těchto 16 bytů je logicky rozděleno na 2 části:
- 12 bytů (= 96 bitů) celočíselná hodnota N bez znaménka jako absolutní hodnota C,
- 4 byty (=32 bitů) obsahující mj. desítkový faktor D a znaménko čísla C.
Část N celočíselné hodnoty má 96 bitů (12 bytů) a je absolutní hodnotou čísla C. Hodnota N je tedy větší nebo rovna nule a menší nebo rovna 296-1.
Část F obsahující desítkový faktor a znaménko má 32 bitů (4 byty, bity číslovány zleva) je rozdělena takto:
- 31. bit je znaménkový; 0 pro kladná C a nulu, 1 pro záporná C a nulu.
- Bity 30 až 24 jsou nevyužité.
- Bity 23 - 16 (tj. druhý byte zleva) obsahuje hodnoty desítkového faktoru D z intervalu <0;28> (tj. 0016 - 1C16).
- Bity 15 - 0 (poslední 2 byty zprava) jsou nevyužité.
Interval nenulových absolutních hodnot Decimal je tedy od (296-1) x 10-28 (pro D=28) do 296-1 (pro D=0).
Část N lze logicky rozdělit na 2 skupiny celočíselných hodnot bez znaménka: 32 nejvyšších bitů (4-bytové číslo bez znaménka) a 64 nejnižších bitů (8-bytové číslo bez znaménka). Označme je Nhigh a Nlow. Při práci s hodnotami typu Decimal používá Microsoft tento způsob uložení:
- Část F,
- část Nhigh,
- část Nlow.
Všechny tři části jsou uloženy jako little endian (viz dále).
Endians
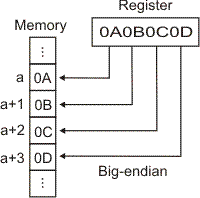
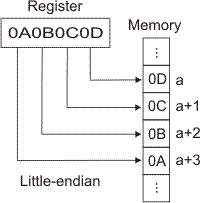
Tento etymologicky zajímavý pojem použitý již Johnatanem Swiftem je mezi počítačovou veřejností znám spíše ve spojení Little-endian a Big-endian.
Jde o následující problém: Celý tento článek mluví o několika bytech umístěných v paměti "vedle sebe". Ony byty však mají konkrétní adresy. Mluvíme-li např. o 2-bytové hodnotě 910 = 10012 typu Unsigned Short Integer = 0000 0000 0000 10012, jak je tato hodnota umístěna v paměti třeba od adresy 13? Takto
| Big-Endian | ||||
| Obsah bytu | . . . | 0 0 0 0 0 0 0 0 | 0 0 0 0 I 0 0 I | . . . |
| na adrese | 12 | 13 | 14 | 15 |
nebo takto:
| Little-Endian | ||||
| Obsah bytu | . . . | 0 0 0 0 I 0 0 I | 0 0 0 0 0 0 0 0 | . . . |
| na adrese | 12 | 13 | 14 | 15 |
jinak řečeno, je první umístěný byte ten nejvíce či nejméně významný? Je dobré si v tomto případě uvědomit, že druhý uvedený případ je ekvivalentní tomuto:
| Little-Endian | ||||
| Obsah bytu | . . . | 0 0 0 0 0 0 0 0 | 0 0 0 0 I 0 0 I | . . . |
| na adrese | 15 | 14 | 13 | 12 |
tj. jenom "kreslíme" adresaci paměti opačně než v prvním případě. Ve všech třech případech už jsou nad schématy uvedena označení pomocí "endian". Toto není jen otázka umístění vícebytových dat v paměti. Například při přenosu dat USB (= sériovým) portem je nejdříve z každého bytu vysílán bit 7 nebo bit 0? Uvědomme si dále, že i v hovorové řeči používáme např. dvacátý první (=Big-endian) nebo jedenadvacátý (=Little-endian).
Registry procesorů Intel jsou tvořeny řadou bitů s nejvyšším bitem vlevo. Při přenosu z a do paměti pak rozdíl mezi Little-endian a Big-endian pěkně znázorňují schémata uvedená v [4]:
 |
 |
Procesory Intel a programovací jazyky a systémy minimálně Microsoftu používají Little-endian. Celá řada operačních systémů pracujících na procesorech x86 a x86-64 používá Little-endian, stejně tak řada jiných systémů pracujících např. na procesorech SPARC, Motorola a dalších používá Big-endian.
Přesnost uložení hodnot
Obecné úvahy
Malé opakování učiva z mateřské a základní školy: čísla máme přirozená, celá, racionální a reálná. Uložit v počítačovém prostředí např. přirozenou trojku žádný problém nečiní - viz výše. Uložit tam však racionální 1/3 = 0.33333..... je problém primárně filozofický. Už Alexandre Dumas vložil do úst svého d'Artagnana kouzelný výrok:
Jedním ze základních pravidel mathematických je, milý Porthe, že nádoba musí býti větší obsahu!
Aplikováno na nádobu (=konečné digitální prostředí) a obsah (=nekonečné číslo) vidíme zřetelný spor. Vyplývá z toho, že žádné číslo s nekonečným rozvojem v konečném digitálním prostředí přímo neuložíme. Uložíme sice číslo hodně blízké, ale to už není to nekonečné. Z toho vyplývá nutnost zkoumat, hodnoty kterých číselných kategorií uložíme a kterých ne. Znovu zdůrazněme, že jde o přímé uložení hodnoty některým ze shora popsaných způsobů, nikoliv o obcházení přes nějaké datové struktury apod.
Jak je zřejmé z popisu uložení celočíselných hodnot, zde problémy s přesností nenastávají. Každá celočíselná hodnota z intervalu přípustného pro daný typ a daný paměťový prostor se v něm uloží bez ztráty přesnosti. Chápeme-li čísla přirozená jako podmnožinu čísel celých, vyplývá z toho závěr: každé přirozené a celé číslo - až do jisté maximální velikosti - v digitálním prostředí uložíme.
Jiná je však situace u ne-celočíselných hodnot.
Těmi jsou především čísla racionální. Některá jistě uložíme - viz shora v příkladu hodnotu 1,25. Některá ovšem ne - viz zmíněné hodnoty s nekonečným rozvojem. Jak je z popisu způsobů uložení zřejmé, množina uložitelných racionálních čísel je konečná - sice relativně velká, ale proti nekonečnému počtu racionálních čísel je trapně malá. Proto je důležitá informace o zaokrouhlovací chybě vzniklé při pokusu uložit nekonečné racionální číslo. Tuto chybu nelze obecně vyjádřit v absolutní hodnotě, protože uložená čísla se liší řádově. Lze však jednoznačně udat, na kolik platných cifer se lze spolehnout - kolik platných cifer určitě tvoří počátek zápisu jakékoliv racionální hodnoty.
U shora popsaných datových typů Single, Double a Extended je to zřejmé: je to počet bitů části pro mantisu + 1 (myšlená 1.) - 1 (poslední cifra už může být zaokrouhlená). Tedy např. u typu Single to je 23 cifer - ovšem dvojkových. Pro běžný život je to nic neříkající hodnota. Uvažme proto, že maximální číslo mající ve dvojkovém zápisu 23 cifer je 111,1111,1111,1111,1111,11112 = 223 - 1 = 8 388 60710 a to má 7 cifer desítkových. Ale ne všechna 7-ciferná desítková čísla uložíme - už ne např. číslo o 1 větší. Proto závěr: datový model Single ukládá hodnoty s přesností max. 7 platných (desítkových) cifer. Obdobným způsobem se dojde i k maximálnímu počtu platných cifer u dalších modelů - viz tabulka v odstavci Formáty FPU shora.
Protože čísla reálná mají obecně nekonečný rozvoj, platí o nich - zvláště o přesnosti uložení - to samé jako pro čísla racionální.
Hodnoty 10-n
Jednou z velmi nepříjemných skutečností binárního počítačového světa je pro nás, kteří uvažujeme zásadně v desítkové soustavě, toto: žádná z hodnot tvaru 10-n (n=1, 2, 3, ...) nemá konečný dvojkový rozvoj. Uvědomíme-li si, že jde o tak běžně používané hodnoty (desítkově) 0,1; 0,01; 0,001 atd. - pak skutečnost, že žádnou z těchto hodnot nelze popsanými modely uložit, je pro mnohé velkým překvapením.
Např. jedna desetina (0,1 desítkově) má dvojkový rozvoj 0.0001 1001 1001 1001 1001 1001 1001 1 ... Při ukládání této hodnoty se musí vzít jen takový počet platných cifer (počínaje první jedničkou), kolik bitů + 1 má část pro mantisu. Jestliže první dvojková cifra, která se už neuloží, je nula, pak je vše zřejmé, uložená hodnota je o trochu menší než jedna desetina. Jestliže je to však jednička, pak to zřejmé není: vznikne uložený zbytek zaokrouhlením nebo uříznutím? V prvním případě je uložená hodnota o trochu větší než desetina, ve druhém případě trochu menší než desetina.
Rozdíl, o který se uložená hodnota liší od jedné desetiny, je např. v modelu Double okolo 6.6 x 10-16. Zdálo by se, že je to tak málo, že hořejší úvahy jsou čistě akademické. Zdaleka tomu tak není. Jednak z toho plyne, že aplikační programy si nemohou dovolit testovat dvě ne-celočíselné hodnoty na rovnost. Pokud by se lišily byť jen na posledním bitu, procesor je vyhodnotí jako různé. Konstrukce typu If P=S ... jsou v programech vlastně nepřípustné. Vždy by se měla testovat absolutní hodnota jejich rozdílu; teprve když je menší než nějaká elementární hodnota určená programátorem podle povahy aplikace, teprve pak by se měly dvě hodnoty považovat za stejné.
Další nepříjemnou praktickou situací jsou cyklické výpočty s ne-celočíselnými hodnotami. Jestliže se totiž tisíckrát nakumuluje do původně nulové proměnné nepřesná tisícina, výsledek určitě nebude roven přesně jedné. Buď bude o trochu menší, nebo o trochu větší - podle toho, zda je ona tisícina zaokrouhlena nebo uříznuta. Proto nejde takový cyklus řídit podmínkou na dosažení hodnoty 1. I podmínky typu "... dokud je menší než 1" nebo "... dokud není větší než 1" jsou zavádějící, protože pak by se mohl cyklus provést třeba jen 999x.
Stačí si např. v Excelu spustit toto makro:
Sub TestTisiciny()
Dim S As Double
Dim i As Long
S = 0
For i = 1 To 1000
S = S + 0.001
Next
MsgBox Format(S - 1, "0.00000000E+00")
End Sub
Výsledkem bude, o kolik se S liší od jedné - a nebude to nula!
Zaokrouhlování
Při přípravě dat jednorozměrného datového souboru je začasté kladena podmínka na nějakou formalizaci zápisu datových hodnot, např. na počet desetinných míst, na rovnost násobku nějakého čísla, na náhradu zlomku desetinným zápisem apod. I shora uvedené odstavce pracují s pojmem "zaokrouhlení". Přitom osoby data připravující používají zcela automaticky jejich úpravu - de facto aproximují číslem "velmi podobným". Tento odstavec velmi stručně popisuje věc zdánlivě zcela jasnou; při pečlivějším studiu však lze ukázat, že je většinou populace nazírána velmi zjednodušeně. Nejčastější a stěžejní úlohou je zaokrouhlení na celé číslo (tj. aproximace celým číslem). Není to však jediná úloha - viz dále a také [7].
Pokud nebude výslovně řečeno jinak, bude v této kapitole X značit zaokrouhlované číslo, A pak zaokrouhlení čísla X.
Zaokrouhlení na celé číslo
Zaokrouhlení na nejbližší celé číslo
Jde zřejmě o nejznámější a nejčastější úlohu zaokrouhlování. Právě tak nám byla problematika zaokrouhlování prezentována počínaje základní školou. Zní: Nahraďte hodnotu reálného čísla X celočíselnou hodnotou. Obvykle je řešena následovně:
- Pro každé reálné číslo X existuje jediné celé číslo A, pro které platí: X Î <A-0.5; A+0.5).
- Toto číslo A nazvěme zaokrouhlením čísla X.
Pro potřeby kapitoly o zaokrouhlování budeme značit A = [X].
Postup je často označován jako "zaokrouhlení na nejbližší" (round to nearest). Většina programovacích jazyků a statistických programů obsahují funkci typu Round(X), jejímž parametrem je obecně reálné číslo a výsledkem celočíselná hodnota (nebo reálná hodnota s nulovou desetinnou částí) rovna zaokrouhlené hodnotě podle popisu výše. Např. [2.4] = Round(2.4) = 2; [3.9] = Round(3.9) = 4; [7.5] = Round(7.5) = 8.
Při nezaujatém pohledu (a zvláště při pohledu zaujatém naší peněženkou po zrušení desetníků, dvacetníků a padesátníků) se však musíme ptát: hodnoty rovny celočíselné hodnotě plus 0.5 jsou evidentně ve výjimečném postavení - vždy se popisovanou definicí (k naší škodě) zaokrouhlují "nahoru". Touto problematikou se zabývá samostatný odstavec níže.
Zaokrouhlení nahoru
V anglosaské literatuře se používá také termín "zaokrouhlení ke kladnému nekonečnu" (round to positive infinity). Zaokrouhlení A čísla X je nejmenší celé číslo, které není menší než X. Je-li číslo A rovno takovému zaokrouhlení čísla X, značí se A = é X ů.
V programovacích jazycích a statistickém software je pro toto zaokrouhlení používána funkce pojmenovaná Ceiling: A = Ceiling (X) nebo také RoundUp: A = RoundUp(X). Platí:
é X ů = - ë -X ű
Zaokrouhlení dolů
V anglosaské literatuře se používá také termín "zaokrouhlení k zápornému nekonečnu" (round to negative infinity). Zaokrouhlení A čísla X je největší celé číslo, které hodnotou nepřesáhne X. Je-li číslo A rovno takovému zaokrouhlení čísla X, značí se A = ë X ű.
V programovacích jazycích a statistickém software je pro toto zaokrouhlení používána funkce pojmenovaná Floor: A = Floor (X) nebo také RoundDown: A = RoundDown(X). Platí:
ë X ű = - é -X ů
Zaokrouhlení k nule
V anglosaské literatuře se používá také termín "zaokrouhlení od nekonečna" (round from infinity). Zaokrouhlení A čísla X je to celé číslo, které vznikne odstraněním zlomková části X.
V programovacích jazycích a statistickém software je pro toto zaokrouhlení používána funkce pojmenovaná Truncate: A = Truncate (X), nebo také Fix: A = Fix (X). Platí:
Truncate (X) = Sgn(X) . ë |X| ű = -Sgn (X) . é -|X| ů
kde funkce Sgn je funkce "znaménka" (signum): vrací +1 pro kladná, -1 pro záporná čísla, a 0 pro nulu.
Zaokrouhlení od nuly
V anglosaské literatuře se používá také termín "zaokrouhlení k nekonečnu" (round to infinity). Zaokrouhlení A čísla X je číslo X, je-li X celé. Není-li X celé, pak je to největší celé číslo A, pro něž je A < X (pro kladná X) nebo nejmenší celé číslo A, pro něž je X < A (pro záporná X).
Platí:
A = Sgn(X) . é |X| ů = -Sgn (X) . ë -|X| ű
kde funkce Sgn je funkce "znaménka" (signum): vrací +1 pro kladná, -1 pro záporná čísla, a 0 pro nulu.
Zaokrouhlení poloviny
Odstavec popisuje možné postupy zaokrouhlení reálného čísla X na celé číslo A, je-li zlomková část X rovna přesně 1/2.
Zaokrouhlení poloviny nahoru
(také "ke kladnému nekonečnu"). Je-li zlomková část čísla X rovna přesně 1/2, je zaokrouhlení A = X + 0.5. Je tedy zaokrouhlení čísla 17.5 rovno 18 a zaokrouhlení -17.5 rovno -17. Platí:
A = ë X + 0.5 ű = - é -X - 0.5 ů
Tento typ zaokrouhlení není symetrický, přesněji: způsobuje kladné zešikmení zaokrouhlovací chyby.
Zaokrouhlení poloviny dolů
(také "k zápornému nekonečnu"). Je-li zlomková část čísla X rovna přesně 1/2, je zaokrouhlení A = X - 0.5. Je tedy zaokrouhlení čísla 17.5 rovno 17 a zaokrouhlení -17.5 rovno -18. Platí:
A = é X - 0.5 ů = - ë -X + 0.5 ű
Tento typ zaokrouhlení podobně jako předchozí není symetrický, přesněji: způsobuje záporné zešikmení zaokrouhlovací chyby.
Zaokrouhlení poloviny od nuly
V anglosaské literatuře se používá také termín "zaokrouhlení k nekonečnu". Je-li zlomková část čísla X rovna přesně 1/2, je zaokrouhlení A = X + 0.5 (pro kladná X) resp. A = X - 0.5 (pro záporná X). Je tedy zaokrouhlení čísla 17.5 rovno 18 a zaokrouhlení -17.5 rovno -18. Platí:
A = Sgn(X) . ë |X| + 0.5 ű = - Sgn(X) . é -|X| - 0.5 ů
Tento typ zaokrouhlení zohledňuje kladné a záporné hodnoty symetricky a je bez celkového vychýlení, pokud jsou původní čísla kladná nebo záporná se stejnou pravděpodobností.
Zaokrouhlení poloviny k nule
V anglosaské literatuře se používá také termín "zaokrouhlení od nekonečna". Je-li zlomková část čísla X rovna přesně 1/2, je zaokrouhlení A = X - 0.5 (pro kladná X) resp. A = X + 0.5 (pro záporná X). Je tedy zaokrouhlení čísla 17.5 rovno 17 a zaokrouhlení -17.5 rovno -17. Platí:
A = Sgn(X) . é |X| - 0.5 ů = - Sgn(X) . ë -|X| + 0.5 ű
Tento typ zaokrouhlení stejně jako předchozí zohledňuje kladné a záporné hodnoty symetricky.
Zaokrouhlení poloviny k sudé
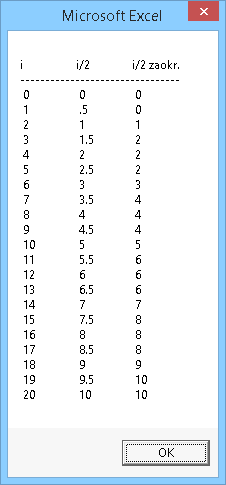
Je-li zlomková část čísla X rovna přesně 1/2, je zaokrouhlení A rovno nejbližšímu sudému celému číslu. Je tedy zaokrouhlení čísla 17.5 rovno 18 (stejně jako zaokrouhlení 18.5), a zaokrouhlení -17.5 rovno -18 (stejně jako zaokrouhlení -18.5).
Tento typ zaokrouhlení stejně jako předchozí zohledňuje kladné a záporné hodnoty symetricky. Navíc pro rozumnou distribuci hodnot veličiny X je průměrná hodnota zaokrouhlených čísel stejná jako čísel původních. Tento typ zaokrouhlení je označován také jako nestranné, konvergentní, statistické, Holandské (Dutch), Gaussovo, licho-sudé, bankéřské nebo přerušované (broken). Toto zaokrouhlení je také výchozím typem zaokrouhlení v "Normách pro aritmetiku pohyblivé řádové čárky" - IEEE-754.
Názorně to dokumentuje tento příklad: Zobrazte z čísel 0 až 20 jejich poloviny. Malý prográmek (např. tzv. makro třeba v Excelu) a jeho výsledek:
Sub ZaokrouhleniPoloviny()
Dim i As Long, j As Long
Dim r As Double, T As String
T = "i" + vbTab + "i/2" + vbTab + "i/2 zaokr." + vbCrLf
T = T + "--------------------------------" + vbCrLf
For i = 0 To 20
j = i / 2
r = i / 2
T = T + Str(i) + vbTab + Str(r) + vbTab + Str(j) + vbCrLf
Next
MsgBox T
End Sub
|
 |
Zaokrouhlení poloviny k liché
Je-li zlomková část čísla X rovna přesně 1/2, je zaokrouhlení A rovno nejbližšímu lichému celému číslu. Je tedy zaokrouhlení čísla 17.5 rovno 17 (stejně jako zaokrouhlení 16.5), a zaokrouhlení -17.5 rovno -17 (stejně jako zaokrouhlení -16.5).
Tento typ zaokrouhlení má stejné vlastnosti jako předchozí.
Stochastické zaokrouhlení poloviny
Je-li zlomková část čísla X rovna přesně 1/2, je zaokrouhlení A rovno náhodně stanovené hodnotě X+0.5 a X-0.5, a to se stejnou pravděpodobností.
Tento typ zaokrouhlení je v podstatě rovněž bez celkového zkreslení, navíc je "spravedlivé" k lichým i sudým hodnotám A. Na druhé straně do výsledku vnáší náhodnou komponentu: Opakovaný výpočet na stejných datech může mít jiné výsledky.
Alternativní zaokrouhlení poloviny
Jsou-li zlomkové části čísel X rovny přesně 1/2, použije se pro první takovou hodnotu zaokrouhlení nahoru, pro druhou zaokrouhlení dolů, pro třetí opět nahoru atd. Tato metoda sice odstraňuje náhodnou komponentu, při opakovaných výpočtech na datech sice stejných, ale v jiném pořadí může dávat odlišné výsledky.
Zaokrouhlení na daný krok
Obecnější úlohou je zaokrouhlování na daný krok - např. na jednu setinu, na celé stovky, ale i na čtvrtminuty (= násobky 15 sec). Jedna z možností je využití výše popsané definice zaokrouhlení na celé číslo potažmo funkce Round:
Označme q daný krok (např. 100 pro zaokrouhlení na celé stovky, 0.001 pro zaokrouhlení na tisíciny). Zaokrouhlení reálného čísla X na krok q je pak hodnota
B = [X/q] . q
Zaokrouhlení hodnoty 123 456.789 na celé stovky je pak rovno součinu hodnoty [1 234.56789]=1235 a hodnoty 100, tj.ve výsledku 123 500.
Funkci Round z předchozího odstavce lze pak rozšířit přidáním druhého nepovinného parametru (není-li zadán, je roven 1):
- Round (X, 1) = Round (X)
- Round (X, q) = Round (X/q, 1) . q
Zaokrouhlení na definovaný počet m (desetinných) míst je pak rovno hodnotě funkce Round s druhým parametrem rovným 10-m (tedy pro zaokrouhlení na tisíciny je m=-3, na celé stovky rovno 2).
Díl II: Základy DTP
Cílem je příprava studentů na tvorbu kvalitního dokumentu (např. ročníkové, diplomové a jiné práce) postupem obvyklým v DTP systémech. Výsledný dokument bude obsahovat řadu konstrukcí - zvláště těch, které jsou automaticky aktualizovány. Jde zejména o různé seznamy, odkazy, poznámky pod čarou apod. Rovněž je předvedena práce s rámy, s vícesloupcovou sazbou a další funkčností DTP systémů. U mnoha vlastností je komentována analogie s DTP systémy přeci jen o třídu kvalitnějších, než je program Word.
U studentů se předpokládá středoškolská znalost pouze základních pracovních postupů, jako je zápis textu a jeho oprava, označování částí textu, změna základních atributů písma a odstavců, vkládání prázdných tabulek daného rozměru, obrázku z daného souboru apod.
V této části učebních textů je hojně používána původní anglická terminologie a je snahou autorů ji poměrně důsledně uvádět. Milovníci jiných jazyků za to jistě poděkují, protože konečně budou vědět, o co jde. Nepřátelé čehokoliv jiného než je čeština nechť za to poděkují naprosté nekvalifikovanosti (nebo korupci?) při výběru překladatelů. Vždyť přeložit naprosto zřejmý termín PORT při připojení zařízení (viz např. český manuál výborného navigačního programu iGo) jako PŘÍSTAV - no to může snad jen gynekolog.
DTP I: Přípravné činnosti, obecné informace
Organizační
Cvičné soubory
Pro výuku jsou připraveny soubory a) typu dokument a b) typu obrázky. Studenti si je před vlastním obsahem výuky stáhnou - např. do DOKUMENT-ů, na plochu ap. podle výukového prostředí. V případě učebny J-409, areál VŠB-TU Ostrava, mohou mít soubory k disposici ihned po přihlášení ve svém profilu uživatele Student (viz níže). Jde o následující soubory resp. adresy:
Dokument
Především se cvičí na "holém" textu nějakého článku, rešerše apod. Ten je připraven jako soubor RADYNE.DOCX zde ke stažení. Výsledkem úpravy tohoto cvičného dokumentu postupy dle následujícího textu je kompletně naformátovaný dokument RADYNET.DOCX zde ke stažení. Pro procvičování práce s dokumentem většího rozsahu - charakteru diplomové práce a podobně - je připraven soubor CVICOBS.DOCX zde ke stažení.
Pokud se studenti hlásí jako uživatelé Student na učebně VŠB TU Ostrava, J-409, pak po přihlášení mají cvičné dokumenty v dokumentech uživatele Student (t.j. ve "svých" dokumentech) v adresáři WORD.
Obrázky
Předem připravené dva obrázky budou vkládány do dokumentu standardními nástroji. Jsou připraveny jako soubory RADYNE1M.JPG a RADYNE3M.JPG.
{kind=link}
{kind=link}
Pokud se studenti hlásí jako uživatelé Student na učebně VŠB TU Ostrava, J-409, pak po přihlášení mají uvedené obrázky v dokumentech uživatele Student (t.j. ve "svých" dokumentech) v adresáři WORD.
Konvence
V této části je popisován postup v prostředí programu Word, edice Microsoft Office 2010. Tomu odpovídá i terminologie:
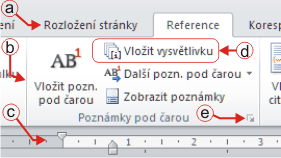 Dokument otevřený v prostředí programu Word |
|
Ovládací prvek z bodu e. předchozího seznamu bude v textu
zobrazováno symbolem  . Pro další
ovládací prvky je použita standardní terminologie resp. zobrazení (tlačítko,
zaškrtávací pole
. Pro další
ovládací prvky je použita standardní terminologie resp. zobrazení (tlačítko,
zaškrtávací pole  resp.
resp.
 , rozvíjecí seznam aj).
, rozvíjecí seznam aj).
Pro vyznačení posloupnosti aktivací návazných ovládacích prvků je použit zápis
Hlavní karta / Skupina příkazů / Příkaz
Značí tedy zápis
Reference / Poznámky pod čarou / Vložit vysvětlivku
(viz situaci na předchozím obrázku) požadavek na aktivaci hlavní karty Reference, tam vyhledání skupiny Poznámky pod čarou, a v ní použít příkaz Vložit vysvětlivku.
Výjimkou je položka Soubor hlavního menu, kde na druhém místě je uvedena položka levého panelu a na třetím místě skupina parametrů.
Některé příkazy ve skupině mají pod ikonou nebo vedle textu
ještě tlačítko  . Pokud to nevyplyne
z kontextu, bude výslovně řečeno, zda se má stisknout ikona nebo toto tlačítko
pod (vedle) ní.
. Pokud to nevyplyne
z kontextu, bude výslovně řečeno, zda se má stisknout ikona nebo toto tlačítko
pod (vedle) ní.
Tento styl textu je ve článku použit pro pokyny čtenáři při práci se cvičným dokumentem, případně pro popis objektů a činností týkající se výhradně cvičného dokumentu.
Nastavení prostředí
Pokud nebude řečeno jinak, předpokládá se od tohoto okamžiku práce v prostředí programu Word s otevřeným dokumentem RADYNE.DOCX.
Zobrazení informačních značek
Při práci na dokumentu je zapotřebí vidět co nejvíce informací o jeho struktuře, obsahu, rozložení atd. Jde o takové vizuální informace, které nebudou tisknuty, ale pomáhají autorovi v sestavení dokumentu, nastavení vlastností a ve zefektivnění činností obecně.
Soubor / Možnosti / Zobrazení / Vždy zobrazit tyto značky formátování
V této skupině se zaškrtne jen
Zobrazit
všechny značky formátování.
Soubor / Možnosti / Upřesnit / Zobrazit obsah dokumentu
V této skupině se navíc zaškrtne
Zobrazit
záložky a dále
Zobrazit hranice textu.
Zobrazení posuvníků a pravítek
Soubor / Možnosti / Upřesnit / Zobrazení
V této skupině se navíc zaškrtne
Zobrazit
vodorovný posuvník,
Zobrazit
svislý posuvník, a dále
Zobrazit
svislé pravítko v zobrazení Rozložení při tisku.
Zobrazení / Zobrazit
V této skupině se zaškrtne
Pravítko.
Zobrazení panelu stylů
Domů / Styly
V této skupině se stiskne tlačítko nástrojů skupiny v pravém
dolním rohu , čímž se zobrazí panel
stylů. Tento panel je vhodné - pokud už není - ukotvit na pravý okraj okna
aplikace Word.
Dále se stiskne odkaz Možnosti ... v pravém dolním rohu panelu. V následně zobrazeném formuláři se z rozvíjecího seznamu Vyberte styly, které chcete zobrazit vybere položka Všechny styly. Z dalšího rozvíjecího seznamu Vyberte způsob řazení seznamu se vybere položka Abecední.
Zobrazení dalších příkazů
S otevřeným dokumentem je možno provádět řadu činností. Těch je však tolik, že program Word (zvláště po zavedení zmatených, nepřehledných a nelogicky uspořádaných tzv. karet) nemá absolutně šanci je ve svém prostředí všechny nabídnout. Autoři programu Word měli alespoň tolik slušnosti, že ponechali uživatelům možnost si doplnit karty a panely nástrojů o příkazy pro vyvolání těch činností, které nutně potřebují a v kartách nejsou (je jich 703).
To se týká zvláště příkazu pro vložení jednoho z nejdůležitějších typografických nástrojů pro rozmísťování částí dokumentu - rámu (angl. frame), v terminologii počeštěného Wordu nazývaného zdrobněle rámeček. Zde pozor! Např. v nápovědě k Wordu se pod pojmem rámeček rozumí to, co je v prostředí Wordu označováno jako ohraničení, zatímco pojem rám (nebo alespoň rámeček ve smyslu typografického rámu) v nápovědě vůbec není.
Vložení příkazového tlačítka pro vytvoření nového rámu do Panelu nástrojů Rychlý přístup se provede takto:
Soubor / Možnosti / Panel nástrojů Rychlý přístup
Tam se nejprve z rozvíjecího seznamu
Zvolit příkazy z zvolí
Všechny příkazy. Pak se v (abecedně seřazeném)
levém seznamu vyhledá a označí položka Vložit vodorovný
rámeček a tlačítkem
 se přidá do pravého seznamu.
se přidá do pravého seznamu.
Použití základních stylů
Styly obecně
Základním elementem textu je v DTP systémech odstavec. Styl je pak pojmenovaná množina atributů odstavce (tj. např. font, velikost, zarovnání, odsazení apod.). Primární úlohou autora dokumentu při jeho grafické úpravě je tedy přidělovat jednotlivým odstavcům dokumentu konkrétní styly.
Autoři programu Word zvolili koncepci předdefinované množiny stylů s jedním implicitním stylem, který pojmenovali Normální. Ten se použije např. při založení nového dokumentu jako aktivní styl (tedy pokud uživatel začne ihned po vytvoření nového dokumentu do něj psát text prvního svého odstavce, bude formátovaný stylem Normální). Dále autoři programu Word mají ve své koncepci možnost vytvářet hierarchický strom stylů. Změní-li se nějaký atribut stylu X, změní se i ve všech stylech ve větvi ze stylu X vycházející. K označení používají formulace "Styl Y je založený na stylu X". Připouští ovšem, aby nějaký styl nebyl založený na žádném stylu.
Jednou z definovaných vlastností stylu je Styl následujícího odstavce. Nechť má styl Y jako styl následujícího odstavce uveden Z. Pak ukončí-li autor dokumentu zápis textu odstavce stylu Y stisknutím Enter (= vloží další nový prázdný odstavec), pak tomuto novému odstavci bude přidělen styl Z. Tento styl může samozřejmě posléze autor dokumentu tomuto odstavci podle své úvahy změnit.
Autoři programu Word připravili přes 260 předdefinovaných stylů. Kromě stylů předvyplnili pro každou činnost zajišťovanou programem (a vyžádanou autorem dokumentu) většinu volitelných parametrů. Příkladem může být vložení obsahu. Při vyžádání takové činnosti je autorovi dokumentu předložen formulář, kde jsou nabízena předvyplněná parametrická pole. Mnohými takovými parametry jsou právě názvy stylů. Řečeno opačně: některé styly autoři programu Word použili jako implicitní styly pro konkrétní činnosti v konkrétním významu. Proto se autorovi dokumentu, který není detailně obeznámený s mechanismem stylů, nedoporučuje tato implicitní nastavení měnit.
Úprava stylu
Atributy, které styl přiděluje odstavcům, lze kdykoliv změnit.
V panelu stylů (jeho zobrazení viz výše) se nalezne styl, který se má upravit.
Po umístění kurzoru myši na něj se položka změní na rozvíjecí seznam. Z rozvinutého
seznamu se volí Změnit ... a tím se zobrazí
formulář Úprava stylu. V něm jsou nejčastěji měněné atributy uvedeny
přímo, úplně všechny jsou pak dostupné použitím tlačítka
 vlevo dole.
vlevo dole.
Styly Nadpis i
Připravené styly s názvy Nadpis 1, Nadpis 2 ... Nadpis 9 jsou předvyplněné ve formuláři pro vložení obsahu. Protože v automaticky generovaném obsahu jsou zobrazeny texty odstavců formátovaných právě těmito styly, předpokládá se jejich použití autorem dokumentu pro označení nadpisů kapitol první úrovně, nadpisů kapitol druhé úrovně (pod-kapitol), nadpisů kapitol třetí úrovně (pod-pod-kapitol) atd. Atributy těchto stylů může autor dokumentu libovolně měnit, nedoporučuje se však měnit jejich název.
Styly Obsah i
Připravené styly s názvy Obsah 1, Obsah 2 ... Obsah 9 jsou předvyplněné ve formuláři pro styly obsahu. Těmito styly jsou formátovány v obsahu (!) kapitoly první, druhé až deváté úrovně. Pokud tedy autor dokumentu potřebuje měnit vzhled obsahu, mění atributy právě těchto stylů.
DTP II: Publikace krok po kroku
V této části je podána geneze publikace typu článek v odborném či populárním časopise, diplomová práce apod. Jsou použity soubory vyjmenované shora v Části I - zejména (pokud není řečeno jinak) dokument RADYNE.DOCX obsahující čistý neformátovaný text; do něj budou vkládány doprovodné obrázky RADYNE1M.JPG a RADYNE3M.JPG. U každého pojmu resp. činnosti je většinou podán i stručný výklad.
Je přitom kopírována situace z běžného života. Autor nejprve shromáždí všechny podklady: textové poznámky, tabulky, obrázky. Ujasní si chronologii, v jaké bude myšlenky vyjádřené textem předkládat čtenářům, ve kterých místech textu budou (přibližně) tabulky, obrázky a další objekty. Součástí této fáze je i primární představa rozdělení do kapitol, ovšem bez jejich konkrétního číslování. Poté autor sedne a píše a píše (dokud má myšlenku - vzácný to okamžik); nezdržuje se úpravou, formátováním ani ničím jiným - políbení múzou nemá dlouhodobé účinky.
Jakmile autor dopíše holý, neformátovaný, ale více méně kompletní text (avšak bez čísel kapitol, čísel tabulek, čísel obrázků), teprve tehdy začne vytvářet dokument v cílové podobě. A to je přesně ten okamžik, kterým začíná Část II.
Základní vzhled dokumentu, úprava stylu Normální
Nejpodstatněji ovlivňuje vzhled dokumentu styl Normální. Jím je na začátku formátován celý dokument. Doporučuje se jako jedna z prvních činností nastavit atributy stylu Normální dle představ autora - případě podle pokynů platných např. pro diplomové a podobné práce.
Po označení kteréhokoliv odstavce stylu Normální se ve
vpravo ukotveném panelu stylů rozvine nabídka u stylu Normální a zvolí se
Změnit. Tím se zobrazí formulář
Úprava stylu, ve kterém se provede
detailní nastavení atributů stylu. Kromě názvu stylu lze měnit cokoliv.
Často měněné atributy jsou dostupné přímo na ploše formuláře, úplně
všechny jsou pak dostupné pomocí tlačítka
v levém dolním rohu
formuláře.
V tomto okamžiku nastavujeme ve cvičném dokumentu minimálně Zarovnání do bloku
Dále je možno (nikoliv nutno) nastavit požadavek na dělení slov:
Rozložení stránky / Vzhled stránky / Dělení slov
a vybere se Možnosti dělení slov. V následném formuláři Dělení slov se nastaví:
- Automatické dělení slov
- Nedělit slova psaná VELKÝMI PÍSMENY
- Šířka oblasti pro dělení slov: 0,25 cm
- Max. dělených řádků za sebou: 1
Členění dokumentu, číslování stránek
Zde je popsáno rozdělení cvičného dokumentu RADYNE.DOCX v primární podobě (tj. po uložení ze shora popsaných adres) do kapitol, pod-kapitol, a na to navazující číslování kapitol a stránek.
Kapitoly
Cíl: Rozdělení do kapitol, pod-kapitol atd.
Rozdělení spočívá v přidělení stylů Nadpis 1 a Nadpis 2 těm odstavcům, které jsou uvažovány jako nadpisy kapitol (Radyně a Starý Plzenec) a pod-kapitol (v kapitole Radyně to jsou Z Wikipedie a Z oficiálních stránek, v kapitole Starý Plzenec to jsou O městě samotném, Pamětihodnosti Starého Plzence, Bohemia Sekt a Chateau Radyně - nevšední sekt).
Nejprve se vybere (označí, angl. select) ten celý odstavec, kterému je zamýšleno přidělit konkrétní styl. Jako první se vybere hned první odstavec tvořený jediným slovem Radyně zamýšlený jako nadpis první kapitoly. Pak:
Domů / Styly / Nadpis 1
Pokud není příkaz Nadpis 1 v galerii stylů ve skupině příkazů Styly přítomen, zvolí se styl Nadpis 1 ze seznamu v Panelu stylů (viz shora Zobrazení panelu stylů).
Postup se opakuje pro všechny odstavce zamýšlené jako nadpisy kapitol (styl Nadpis 1) a pod-kapitol (styl Nadpis 2) vyjmenované v předchozím textu. Pořadí přidělování stylů v této fázi není podstatné.
Poznámka: Při prvním použití programu Word po instalaci většinou není styl Nadpis 2 v galerii stylů uveden, musí se proto volit z panelu stylů. Jakmile se však použije, program Word ho nadále už v galerii stylů bude nabízet. Toto se může týkat i prvního použití programu Word v učebnách, kde se studenti přihlašují nějakým globálním uživatelským jménem (většinou Student) s mandatorním profilem z doménového řadiče.
Číslování kapitol
Cíl: Zajištění automatického číslování kapitol a podkapitol, úprava číslování
Nejprve se vybere (označí) celý první odstavec formátovaný stylem Nadpis 1 - zde tedy Radyně. Pak:
Domů / Odstavec / Víceúrovňový seznam
Z knihovny seznamů se vybere požadovaný způsob číslování. Pro účely bakalářských, diplomových a obdobných prací je to způsob 1, 1.1, 1.1.1 atd. Upozorňujeme však, že v mnoha případech (zejména právě závěrečných prací) je způsob číslování stejně jako další náležitosti závazně určen interními předpisy fakulty resp. školy.
Způsob resp. úprava číslování lze změnit:
Znovu se vybere (označí) celý první odstavec formátovaný stylem Nadpis 1 - zde tedy Radyně. Pak:
Domů / Odstavec / Víceúrovňový seznam
Z nabídek pod knihovnou seznamů se vybere Definovat nový víceúrovňový seznam. Ve zobrazeném formuláři lze nastavit řadu vlastností, které jsou však mimo rámec tohoto článku. Snad jediná změna: standardně - anglosaská zvyklost - není za číslem poslední úrovně tečka. V právě zobrazeném formuláři ji do textového pole Zadejte formát čísel lze pro zvolené úrovně dopsat.
Přemístěním číslované kapitoly (pod-kapitoly, pod-pod-kapitoly) dojde automaticky k jejich přečíslování, nikoliv však např. k automatické změně obsahu (viz dále).
Číslování stránek
Cíl: Očíslování stránek vlastním způsobem ve zvoleném umístění
Každá stránka dokumentu sestává z vlastního textu a dalších objektů vložených na stránku, a dále z částí nazývaných v programu Word Záhlaví a Zápatí. Tyto části se opakují v horní a dolní části každé stránky. Mohou obsahovat jeden nebo více řádků a v nich objekty neměnné i pole, které se mohou stránku od stránky měnit. Číslo stránky je právě jedním takovým polem. Bude popsáno umístění čísla stránky do dolní části (= zápatí), a to na střed prvního řádku zápatí.
Textový kurzor se umístí kamkoliv na první stránku dokumentu. Pak:
Vložení / Záhlaví a zápatí / Zápatí
kde se vybere dole položka Upravit zápatí.
Po této volbě se znepřístupní obsahová část stránky a naopak se zpřístupní Záhlaví a Zápatí, přičemž textový kurzor bude v tomto případě aktivní v části Zápatí, a to na první pozici jeho prvního řádku. Zároveň bude v pásu karet zobrazena karta Nástroje záhlaví a zápatí - Návrh.
Řádkům zápatí je standardně přiřazen styl Zápatí. V tomto stylu jsou definovány dva tabelátory: první středový uprostřed svislých hranic textu, druhý pravý na pravé svislé hranici textu. Stačí tedy stisknout klávesu Tab (tím se textový kurzor nastaví na pozici prvního = středového tabelátoru) a pak:
Návrh / Záhlaví a zápatí / Číslo stránky / Aktuální umístění
a tam hned první položka - Číslo ve formátu prostého textu.
Způsobů a formátů čísel stránek je celá řada. Byl popsán způsob relativně obecný. Místo posledního kroku je možno užít také tohoto postupu:
Návrh / Vložit / Rychlé části / Pole
a tam v seznamu Názvy polí zvolit Page. Výhodou je možnost zvolit z následně nabídnutého seznamu Formát z více možností.
Za pozornost stojí také další možnosti záhlaví resp. zápatí, viz např.
Návrh / Možnosti / Jiné na první stránce
Popis těchto funkčností však přesahuje zamýšlený rozsah tohoto článku.
Po vložení čísla stránky (nebo i komplexnější úpravě Zápatí event Záhlaví) se zvolí
Návrh / Zavřít / Zavřít záhlaví a zápatí
Číslování stránek od určité stránky
Cíl: Očíslování stránek počínaje určitou stránkou vlastním způsobem ve zvoleném umístění
Poznámka: Obsah této části nebude předveden ve cvičném dokumentu.
Zejména rozsáhlejší publikace sestávají z několika logických částí, přičemž stránky každé z nich jsou číslovány jiným způsobem (popř. nejsou číslovány vůbec). Příkladem může být právě diplomová práce, kde několik prvních listů není číslováno, následující největší část je číslována od 1, stránky rozsáhlých příloh na konci publikace mohou být číslovány samostatně. Bude popsáno - stejně jako v předchozím odstavci - umístění čísla stránky do dolní části (= zápatí), a to na střed prvního řádku zápatí.
Princip spočívá v rozdělení dokumentu na jednotlivé oddíly. Stránky každého oddílu totiž mohou být číslovány samostatně, každý oddíl jiným způsobem. Do místa, kde má jeden oddíl končit a další začínat (tzv. zalomení oddílu) se vloží označení konce oddílu s tím, že následující oddíl bude začínat na nové stránce.
Textový kurzor se tedy umístí do místa, kde má jeden oddíl končit a druhý začínat. Pak:
Rozložení stránky / Vzhled stránky / Konce
a ze zobrazené nabídky se v části Konce oddílů vybere Další stránka.
Poznámka: Má-li se jiné číslování stránek týkat jen "vnořené" části dokumentu, vloží se analogicky další zalomení oddílu tam, kde má právě vytvořený oddíl končit.
Textový kurzor se poté umístí kamkoliv na první stránku nově vzniklého oddílu. Pak stejně jako v předchozím odstavci:
Vložení / Záhlaví a zápatí / Zápatí
kde se vybere dole položka Upravit zápatí.
Po této volbě se znepřístupní obsahová část stránky a naopak se zpřístupní Záhlaví a Zápatí, přičemž textový kurzor bude v tomto případě aktivní v části Zápatí, a to na první pozici jeho prvního řádku. Zároveň bude v pásu karet zobrazena karta Nástroje záhlaví a zápatí - Návrh. Pokud bylo dříve přiděleno dokumentu číslování stránek, je v části zápatí zobrazeno průběžné číslo stránky ve formátu převzatém z předchozího oddílu.
Pro autora dokumentu podstatná informace spočívá ve zobrazení vodorovné přerušované čáry bezprostředně nad zápatím. Na jejím levém okraji je s podbarveným pozadím umístěn text typu např. Zápatí - Oddíl 2 - (s číslem aktuálního oddílu), na pravém okraji text Stejné jako minulé. V tomto okamžiku (protože zápatí skutečně pokračuje z předchozího oddílu) je dále aktivní volba
Nástroje záhlaví a zápatí / Návrh / Navigace / Propojit s předchozím
Tuto volbu je nutno "vymáčknutím" zrušit. Tím se odstraní informační text Stejné jako minulé a vazba na zápatí předchozího oddílu je zrušena.
Zbývá nastavit počáteční číslo stránky tohoto oddílu a jeho formát (i když je vazba na předchozí oddíl zrušena, číselné hodnoty a formáty jsou stále v přejatém tvaru). V zápatí se tedy označí pole s číslem stránky a pak:
Nástroje záhlaví a zápatí / Návrh / Záhlaví a zápatí / Číslo
stránky / Formát - číslování stránek
...
čímž se zobrazí formulář Formát čísel stránek. V něm autor dokumentu nastaví požadovaný formát číslování a zejména v části Číslování stránek zvolí požadované číslo ve volbě Začít od.
Po provedení event. dalších změn v zápatí se práce se zápatím ukončí:
Nástroje záhlaví a zápatí / Návrh / Zavřít / Zavřít záhlaví a zápatí
Zcela analogicky se postupuje při úpravě záhlaví, je-li třeba přerušit přejímání čísel a formátu v záhlaví stránek dokumentů.
Formátování odstavců a jejich styly
Seznam s odrážkami
Cíl: Vytvoření a změna seznamu s odrážkami
Seznamem s odrážkami se rozumí skupina odstavců, z nichž každý má na svém levém okraji odrážku (libovolný znak nebo vhodně volený obrázek). Z hlediska rychlosti přípravy a vytvoření je optimální zapsat nejprve text všech odstavců, a teprve poté z této skupiny odstavců vytvořit požadovaný seznam.
Ve cvičném dokumentu je taková skupina odstavců připravena. Začíná druhým odstavcem v pod-kapitole 2.2 (Pamětihodnosti Starého Plzence): Slovanské hradiště Hůrka ... a končí o 7 odstavců dále: Kostel Narození svatého ....
Při vytvoření seznamu se nejprve všechny tyto odstavce označí, pak:
Domů / Odstavec / Odrážky
přičemž lze stisknout přímo tlačítko příkazu Odrážky (použije
se naposledy použitá odrážka), nebo v příkazu Odrážka jeho rozvíjecí šipka
(pak lze volit znak nebo obrázek).
Změnit odrážku v již vytvořeném seznamu lze označením všech nebo jen některých jeho odstavců, pak
Domů / Odstavec / Odrážky
a buď vybrat některou z nabízeních, nebo zvolit nabídku Definovat novou odrážku.
Odstavcům seznamu je standardně přiřazen styl Odstavec se seznamem. Pokud je zapotřebí upravit vzhled všech seznamů, mění se tento styl. Pokud je zapotřebí upravit vzhled jen některých seznamů, vyplatí se vytvořit nový styl (viz dále).
Tok textu odstavců
Cíl: Nastavení chování odstavců v souvislosti s přechody na novou stránku
Často lze pozorovat (např. po vytvoření seznamu s odrážkami analogicky předchozímu popisu) poměrně rušivou věc: první odstavec seznamu už byl přesunut na následující stránku, zatímco text běžného předchozího odstavce zůstal osamocený dole na předchozí stránce, i když z kontextu ho lze považovat jakoby za úvodní text k seznamu. Toto chování lze měnit nastavením vlastností jak jednotlivým odstavcům, tak i konkrétním stylům. Zmíněnému odstavci je možno nastavit vlastnosti Kontrola osamocených řádků, Svázat s následujícím a Svázat řádky (viz dále).
Nastavení se provádí v záložce Tok textu formuláře Odstavec, který se zobrazí
Domů / Odstavec /
pro konkrétní vybraný jeden nebo více odstavců, nebo
panel Styly / konkrétní styl
/ Změnit / tlačítko
vlevo dole / Odstavec ...
pro konkrétní styl. Nastavení se provádí pomocí zaškrtávacích
polí . V dalším bude popsáno chování
textu toho odstavce XY, pro který se daná vlastnost nastavuje - a to v tom
případě, že takový odstavec nebo jeho část je (nebo měl by být) posledním
odstavcem na stránce.
Kontrola osamocených řádků
Termínem Osamocený řádek je označen první řádek takového odstavce, z něhož se na zbytek stránky vejde právě jen první řádek (a ostatní už jsou na stránce následující - případ A), nebo poslední řádek takového odstavce, který se ještě na konec stránky vejde celý - až právě na poslední řádek (ten už je na straně následující - případ B). Nastavením požadavku na kontrolu osamocených řádků se zmíněné případy řeší následovně:
- Případ A: Rovněž první řádek odstavce už bude přesunut na následující stránku.
- Případ B: Na následující stránku bude přesunut nejen poslední, ale i předposlední řádek odstavce.
Poznámka 1: Kvalitnější DTP systémy umožňují - dle běžné typografické praxe - nastavit počet řádků, které jsou považovány za osamocené (Word jen jeden), a dokonce tento počet rozlišují v pozici konce stránky (orphan, sirotek) a začátku stránky (widow, vdova) samostatně.
Poznámka 2: Po přesunu řádků nebo odstavců shora popsaným mechanismem zůstane na konci stránky větší či menší prázdný prostor. Kvalitní DTP systémy dovedou automaticky provádět tzv. vertikální kerning - proporcionální rozšíření vzdáleností mezi řádky stránky tak, aby poslední řádek končil skutečně na konci textové plochy stránky a ne "někde ve vzduchu". To je u programu Word samozřejmě nepředstavitelné.
Svázat s následujícím
Rozumí se tím Svázat s následujícím odstavcem. Pokud je požadavek nastaven, pak tento odstavec a následující odstavec budou umístěny na stejné stránce. Nemusí tam však být umístěny v celém rozsahu - to závisí na dalších požadavcích (může být např. celý tento a polovina následujícího odstavce na konci jedné a zbývající polovina následujícího odstavce na druhé stránce).
Tento požadavek mají nastaven především odstavce používané jako nadpisy kapitol, pod-kapitol ap. Bylo by nelogické, aby nadpis kapitoly byl na konci jedné stránky, ale celý zbytek kapitoly začínal až na stránce následující.
Svázat řádky
Nastavení požadavku zajistí, že odstavec nebude rozdělen mezi dvě stránky: pokud se celý nevejde na konec jedné stránky, bude celý přesunut na stránku následující. Také tento požadavek se nastavuje především pro odstavce používané jako nadpisy kapitol, pod-kapitol ap.
Vložit konec stránky před
Význam je zřejmý: tento odstavec bude vždy prvním odstavcem na stránce.
Nedělit slova
Přestože v dokumentu jako takovém se mohou aplikovat pravidla pro dělení slov, požadavek Nedělit slova v daném odstavci dělení slov zabrání. Rovněž tento požadavek se nastavuje především pro odstavce používané jako nadpisy kapitol, pod-kapitol ap.
Vlastní styl
Cíl: Vytvoření resp. změna vlastního stylu
Nechť byly prvnímu odstavci v 2.2 (Ve městě samotném ...) dle předchozího textu nastaveny vlastnosti toku textu tak, že na něj lze pohlížet jako na můj vlastní nadpis odrážkovaného seznamu. Protože takových případů může být v dokumentu více, je vhodné je formátovat nikoliv jednotlivě, ale použít pro jejich formátování jednotný styl. Ovšem jako předdefinovaný styl v galerii stylů neexistuje. Nový vlastní styl se vytvoří např. následujícím postupem:
Nejprve se nastaví atributy vybraného odstavce na finální hodnoty (tj. "aby vypadal tak jak chci"), načež se celý tento odstavec označí (= vybere). Pak
Domů / Styly / Galerie rychlých stylů / tlačítko Více
 vpravo dole / Uložit výběr jako
nový rychlý styl ...
vpravo dole / Uložit výběr jako
nový rychlý styl ...
a v následném formuláři Vytvořit nový styl podle formátování se zadá vlastní název - např. Můj nadpis seznamu. Tlačítko Změnit ... uprostřed dole umožní dodatečně změnit jakýkoliv atribut nově vytvářeného stylu.
Takto vytvořený styl se zařadí do seznamu v panelu stylů a do galerie rychlých stylů, a je možno s ním pracovat běžným způsobem. To se týká zejména jeho použití na vybrané odstavce a změny jeho atributů.
Tabulky
Cíl: Vytvoření tabulky z připraveného textu, změna základních atributů, přiřazení titulku
V této kapitole jsou popsány postupy, které nejsou obvyklým obsahem učiva středních škol. Předpokládá se však např. znalost vložení jednoduché tabulky daného rozměru na dané místo.
Tabulka z připraveného textu
Z hlediska rychlosti přípravy a vytvoření dokumentu je optimální zapsat nejprve neformátovaný text všech odstavců, a teprve poté se zabývat formátováním a dalšími úpravami. Pokud ve fázi zápisu neformátovaného textu je znám textový obsah všech buněk zamýšlené tabulky, zapíše se i ten mezi text ostatních odstavců na požadované místo, a tabulka se vytvoří posléze.
Pravidla pro přípravu textu, který má být automatizovaně převeden na tabulku, jsou následující:
- Při prvotním zápisu textového obsahu tabulky si autor dokumentu ujasní, jaký znak ve svém textu NEPOUŽIJE (např. hvězdičku). Tento znak naopak použije jako oddělovač textů jednotlivých buněk.
- Označí se všechny odstavce, z nichž má být tabulka vytvořena.
- Jeden odstavec označeného textu bude převeden na jeden řádek tabulky. Tabulka tedy bude mít tolik řádků, kolik je označených odstavců.
- Počet buněk v jednotlivých řádcích je určen počtem oddělovačů v jednotlivých odstavcích. Jsou-li např. v textu řádku 4 oddělovače, bude mít řádek 5 buněk.
Ve cvičném dokumentu je pro převod na tabulku připraveno 7 odstavců, a to počínaje druhým odstavcem v 2.4 počínaje BRUT NATURE a konče DOUX. Po jejich označení bude text v nich obsažený převeden na tabulku postupem:
Vložení / Tabulky / Tabulka / Převést text na tabulku ...
V následně zobrazeném formuláři se zkontroluje zjištěný počet sloupců a nastaví se vlastnosti automatického přizpůsobení (nejčastěji se volí přizpůsobení obsahu). Nakonec se zkontrolují oddělovače textu. Pokud autor dokumentu nezvolil jako oddělovač středník nebo tabelátor, zadá se zvolený znak do pole Jiné.
Ve cvičném dokumentu je jako oddělovač použit znak středník (;). Tabulka tedy bude mít 7 řádků, a protože v každém odstavci je jeden znak středník, bude mít 2 sloupce.
Výběr tabulky a jejích částí
Při práci s tabulkou je důležitý výběr jejích částí. Zvláště zde se projeví nutnost zobrazení informačních značek (viz shora Nastavení prostředí). Pro zobrazení konce buňky a konce řádku v buňce je použit znak "¤". V tabulce lze vybrat (a to i nespojitě - s CTRL)
- jeden nebo více řádků,
- jeden nebo více sloupců,
- jednu nebo více buněk,
- celou tabulku jako takovou.
Zvláště velký pozor je třeba věnovat rozlišení situace ad 4. a ad 3. při výběru všech buněk. Celá tabulka je vybrána, jsou-li do výběru zahrnuty i všechny znaky ¤ konce řádků. Není-li ve výběru ani jeden, jsou vybrány všechny buňky.
Výběr dle ad 1. až ad 3. se provede nejlépe tažením myší. Výběr dle ad 4. se provede nejlépe kliknutím na symbol přemísťovací čtyř-šipky, která se zobrazí po najetí kurzoru myši kamkoliv do tabulky.
Vybraným částem tabulky lze pak upřesnit vlastnosti pomocí
Nástroje tabulky / Rozložení / Tabulka / Vlastnosti
čímž se zobrazí formulář Vlastnosti tabulky s tou aktivní záložkou, která se týká právě vybrané části (vybraných částí) tabulky. Většina nabízených vlastností má zřejmý význam, jejich podrobnější popis je však nad zamýšlený rozsah tohoto textu.
Rozměry tabulky
Velikost tabulky, šířky jednotlivých sloupců a výšky jednotlivých řádků lze po výběru celé tabulky upravit tažením myší za jednotlivé linky, které tvoří mřížku tabulky. Pro detailnější úpravu rozměrů tabulky se použije
Nástroje tabulky / Rozložení
a dále skupiny příkazů v této kartě.
Poloha tabulky
Horizontální poloha tabulky se po označení celé tabulky určí běžným postupem:
Domů / Odstavec / Zarovnat na ...
nebo tažením za první úchytku zleva v horním vodorovném pravítku (s nápovědou "Přesunout sloupec tabulky"). Obecně lze polohu tabulky upravit tažením myší za symbol přemísťovací čtyř-šipky, která se zobrazí nad levým horním rohem tabulky po najetí kurzoru myši kamkoliv do tabulky. Při vertikálním přemístění se však začnou aplikovat pravidla pro obtékání, které jsou nad zamýšlený rozsah tohoto textu.
Ve cvičném dokumentu se postup procvičí zarovnáním tabulky na střed.
Titulek tabulky
Protože titulky se vztahují k řadě objektů, nejen k tabulkám, je v tomto odstavci jen heslovitě popsána úprava cvičného dokumentu s ohledem na vytvořenou tabulku. Bližší informace o titulcích objektů a jejich seznamech viz samostatná kapitola Titulky a seznamy objektů.
Ve cvičném dokumentu se označí tabulka vytvořená z připraveného textu (viz shora), postupem popsaným v kapitole "Titulky a seznamy" se zobrazí formulář "Titulek" a v něm se doplní za nabízený text "Tabulka 1" dvojtečka, mezera a text např. "Obsah cukru". Po vložení (jde o první titulek v dokumentu) bude titulek zarovnán vlevo. Protože tabulka je zarovnána na střed (to bývá obvyklá poloha tabulek), zarovná se i titulek na střed změnou stylu (!) Titulek.
Obrázky
Cíl: Vložení obrázku z připraveného souboru, vložení a připojení titulku k obrázku
Vložení obrázku do textu
Základním způsobem vložení obrázku je jeho umístění na aktuální pozici textového kurzoru jako jednoho nového objektu. Zjednodušeně si lze představit, že se tím obrázek stává jedním ze znaků odstavce, do kterého byl vložen. Jeho pozice pak podléhá všem změnám tohoto odstavce - zarovnání, přemístění, vkládání dalšího textu atd. Zároveň však změně podléhají samotné řádky odstavce, a to především změnou rozestupu mezi řádkem, do kterého byl obrázek vložen, a řádku předchozího.
To vše může působit velmi rušivě jak na vzhled dokumentu, tak na samotného autora publikace - při její přípravě text i obrázek různě poskakují, zapsáním jediného nového znaku lze zcela devastovat dosavadní úpravu, obrázek může i zmizet s aktuální stránky apod.
Proto je vhodné v jisté fázi přípravy publikace vložené obrázky od textu oddělit a přidělit jim samostatné chování jak vzhledem k okolnímu textu, tak vzhledem ke stránce nebo sloupci. Dále je vhodné zajistit, aby obrázek nebyl svévolně oddělován od svého titulku event. dalších souvisejících objektů.
Následně bude popsán postup při vložení obrázku do textu první stránky, nastavení jeho obtékání okolním textem, přidělení titulku a seskupení obrázku s titulkem.
Ve cvičném dokumentu se nastaví textový kurzor např. před písmeno Z na začátku odstavce "Z někdejšího královského ..." na první stránce.
Poznámka: Sem se primárně obrázek vloží. Místo nastavení je ale nepodstatné, autor dokumentu stejně posléze obrázek i s titulkem umístí na pozici, kterou bude pokládat za vhodnou.
Samotné vložení obrázku se provede pomocí
Vložení / Ilustrace / Obrázek
načež se požadovaný obrázek vybere z předloženého dialogu pro otevření souboru.
Ze cvičných obrázků se vybere RADYNE1M.JPG.
Poznámka: Obrázek má rozměry 709 x 502 bodů a byl uložen s rozlišením 300 dpi (bodů na palec). V dokumentu bude tedy mít šířku 709 x 2,54 / 300 = 5,98 cm, analogicky výšku 4,25 cm.
Obtékání obrázku okolním textem
Po vložení předchozím způsobem zůstane obrázek vybraným objektem (pokud ne, levý klik ho označí jako vybraný). Tomu se přizpůsobí hlavní karty - vpravo přibude hlavní menu Nástroje obrázku - Formát. V tomto pásu karet jsou soustředěny nástroje pro nastavení vlastností vybraného obrázku. Volíme
Nástroje obrázku / Formát / Uspořádat / Zalamovat text
/ Další možnosti rozložení ...
Následně je zobrazen formulář Rozložení mající pod svým nadpisem tři záložky. Pracuje se v následujících krocích:
- Záložka Obtékání textu:
- Styl obtékání: Vybere se Obdélník. Tím se uvolní k použití další dvě části.
- Zalomit text: Vybere se Oboustranně.
- Vzdálenost od textu: Zde se nastaví, do jaké vzdálenosti má okolní text povoleno přiblížit se obrázku (ze všech čtyřech stran samostatně). Počáteční nastavení se doporučuje nulové shora a zdola, milimetrové zleva a zprava - nastavení lze později kdykoliv změnit podle potřeby.
- Záložka Pozice:
- Vodorovně: Absolutní pozice X cm napravo od levého okraje.
- Svisle: Absolutní pozice X cm pod horním okrajem.
Označení X jako absolutní pozice není třeba v předchozím formuláři měnit. Jednak pozici upraví program Word podle aktuální polohy, jednak stejně bude upravena podle pozdějšího přání autora dokumentu - ať už interaktivně přetažením obrázku nebo "ručním" zadáním přesné číselné hodnoty.
Titulek obrázku
Po předchozím kroku (nastavení obtékání) zůstává obrázek stále vybraným objektem. Titulek lze obrázku přidělit buď po pravém klik-u a výběrem položky Vložit titulek ... z následného kontextového menu, nebo
Reference / Titulky / Vložit titulek
načež se postupuje podle odstavce Titulky a seznamy objektů - viz níže. V prvním textovém poli Titulek (= Caption) se za číslo obrázku doplní požadovaný text (= Title), např. Historická podoba.
Po potvrzení tlačítkem OK bude pod obrázkem umístěn titulek, přičemž okolní text bude respektovat obtékání i titulku.
Spojení obrázku se svým titulkem
Po předchozím kroku (titulek obrázku) zůstává titulek stále vybraným objektem. V tomto okamžiku Ctrl/Klik na obrázek přidá obrázek do označení (budou současně vybrány dva objekty: obrázek a jeho titulek). Následně
Rozložení stránky / Uspořádat / Skupina
/ Skupina
seskupí obrázek a titulek do jednoho objektu, se kterým lze pracovat samostatně.
Pozor! Toto seskupení lze provést pouze tehdy, když byl titulek vytvořen pro obrázek obtékaný způsobem popsaným shora. Pro jiné situace je třeba využít např. rámů - viz níže.
Umístění obrázku s titulkem
Nyní lze obrázek včetně titulku např. umístit do vhodné polohy na stránce, a to nejlépe tažením (= drag and drop). Přitom se okolní text bude přizpůsobovat aktuální poloze obrázku zejména co do obtékání. Obrázek s titulkem lze také tažením pohodlně umístit na jinou stránku. Po "odznačení" obrázku - např. při pokračování práce na jiném místě dokumentu - zůstává obrázek stále na stabilním místě tam, kam byl naposledy přemístěn.
Rámy (Frames)
Cíl: Vložení rámu, změna velikosti, pozice, obtékání, práce s obsahem rámu
Jedním ze základních sazečských nástrojů pro rozvržení strany dokumentu je rám (angl. Frame). Z neznámého důvodu si překladatelé Wordu do češtiny umanuli používat zdrobnělinu slova rám ve tvaru rámeček, čímž se ovšem dostali do sporu s jiným, na mnoha místech často používaným významem této zdrobněliny - ohraničení. Pojem rám přechází historicky z období ruční "horké" sazby, kdy šlo o skutečný obdélníkový rám, do kterého se umísťovaly jednotlivé litery. Rozměr se přizpůsoboval zejména obsahu, bral se však ohled i na ostatní rámy tvořící jednu tiskovou stranu. Formát obsahu rámu sice podléhal (a do dneška podléhá) jistým tiskařským konvencím, z hlediska dnešních DTP systémů je však libovolný a je dán možnostmi použitého DTP systému. Např. z tohoto pohledu primitivní program Word neumí v rámu ani vícesloupcovou sazbu, pro typografii vůbec má řadu dalších omezení.
Vložení prázdného rámu
Tuto akci v celé obecnosti nabízí až nástroj Vložit vodorovný rámeček popsaný v úvodu této části učebních textů v odstavci Nastavení prostředí. V dalším se tedy bude předpokládat, že odkaz na tuto akci byl do panelu nástrojů Rychlý přístup umístěn dle návodu shora.
Rám lze jako objekt aktuálního dokumentu vložit v popisované verzi Microsoft Word několika způsoby. Jednoduché je umístit rám na začátek toho odstavce, v němž je nyní umístěn textový kurzor.
Ve cvičném dokumentu se nastaví textový kurzor např. před písmeno H na začátku odstavce Hlavní stavbou ... na první stránce. Pak:
Rychlý přístup / Vložit vodorovný rámeček
Bezprostředně po vložení rámu je vzhled části stránky následující:

Po vložení je rám vybrán (označen) a má nastaveno obtékání okolního textu okolo celého rámu, vodorovné ukotvení vzhledem ke stránce a svislé ukotvení vzhledem k odstavci. Pro obecné použití rámu je vhodné tato nastavení změnit dle zamýšleného použití.
Poznámka: V některých situacích není prázdný rám vložen hned po stisknutí tlačítka Vložit vodorovný rámeček, ale je třeba kurzorem (který je změněn na tenký černý křížek) opsat na požadovaném počátečním místě obdélník o požadované počáteční velikosti.
Vložení rámu s obsahem
Obsah rámu musí být v tomto případě částí obsahu dokumentu (nikoliv jiného rámu). Tato část dokumentu se označí, pak:
Rychlý přístup / Vložit vodorovný rámeček
Vytvoří se nový rám a označená část dokumentu se do něj přesune (tj. z dokumentu se vyjme). Následně lze pracovat s rámem i jeho obsahem dle následujících odstavců.
Práce s rámem
Při přípravě dokumentu je třeba rozlišovat práci s rámem jako vloženým objektem a práci s jeho obsahem. Předchozí obrázek znázorňuje situaci, kdy je vybrán celý rám jakožto vložený objekt. Při výběru myší je k takovému výběru rámu zapotřebí provést levý klik na jeho okraj (hranice). Rám se pak označí silnějším šrafovaným okrajem s vyznačenými úchytkami v rozích a ve středech stran. Tažením za úchytky lze měnit rozměry rámu, tažením za šrafovaný okraj lze měnit polohu rámu.
Pravý klik na šrafovaný okraj zobrazí kontextové menu rámu. V něm se především volí položka Ohraničení a stínování ... - po vložení nastaví program Word rámu ohraničení tenkou černou čarou, což málokdy vyhovuje. Pro účely vkládání např. obrázků do rámu je vhodnější mít rám bez ohraničení. Druhou volenou položkou z kontextového menu je Formát rámečku ...; její volba otevře formulář pro nastavení vlastností rámu (srov. s nastavením vlastností obrázku):
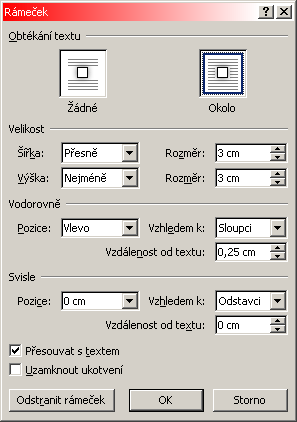
Ve formuláři Rámeček lze především ovlivnit automatické přizpůsobení velikosti rámu vkládanému obsahu. Např. pokud parametr Výška zůstane Nejméně, pak se bude výška rámu automaticky zvětšovat vkládáním dalšího a dalšího obsahu, třeba textu. Nastavení tohoto parametru na Přesně se automatické změně velikosti zabrání - to samozřejmě nevylučuje kdykoliv změnit velikost rámu na potřebnou velikost např. tažením za černé úchytky.
Dále je většinou vhodné zabránit - někdy nepředvídatelnému - poskakování rámu na stránce při úpravě okolního textu. Ukotvení na pevném místě na stránce se docílí odškrtnutím volby Přesouvat s textem a nastavením vodorovné a svislé pozice Vzhledem ke stránce. Konkrétní (číselná) pozice se posléze jednoduše nastaví tažením rámu za šrafovaný okraj do cílového umístění podle úvahy autora dokumentu.
Konečně se nastaví požadované (vodorovné i svislé) vzdálenosti od textu - jak blízko ještě autor dokumentu povolí přiblížení okolního textu k rámu.
Práce s obsahem rámu
Pro práci s obsahem rámu je třeba umístit textový kurzor dovnitř rámu. Tím se plocha rámu stává aktivní pro umísťování obsahu analogicky umísťování obsahu na plochu stránky. Vzhled části stránky pak bude obdobný následujícímu:

Program Word zdaleka neumožňuje pracovat s obsahem rámu v celém rozsahu práce se stránkou, základní postupy jsou však stejné: vkládání textu, odstavců, tabulek, obrázků.
Obecně lze však říci, že autoři programu Word práci s obsahem rámů - obtížně se hledají slušná slova - prostě se jim nepovedla. Jediný funkční způsob vložení obrázků je bez obtékání a bez ukotvení uvnitř rámu. Nelze nastavit vícesloupcovou sazbu (a tedy dělat noviny). Nelze nastavit orientaci (a tedy vkládat široké tabulky "naležato" pomocí rámu) atd. Zábavné je - pokud autor není student fofrující se svou diplomkou - zkusit přidělit odstavci uvnitř rámu styl např. Nadpis 3. Ono to jde - ale odstavec přeskočí z rámu na plochu stránky! Teprve po mnoha pokusech autor zjistí, že takový neposlušný odstavec lze označit, chytit a přetáhnout na původní místo v rámu - právě na takové legrácky však nemá diplomant čas.
Závěrem: Bohužel, na rozdíl od kvalitních DTP systémů, je smysluplné použití rámů v programu Word velmi omezené. Snad jediné, avšak poměrně rozumné využití, je pro umístění obrázků, jejich popisků a jednoduchých doprovodných textů do jednoho celku ukotveného na daném místě dokumentu. Tím se také obejde např. nemožnost seskupit obrázek a text nějakého doprovodného odstavce do jednoho celku.
Vícesloupcová sazba
Cíl: Uspořádat text části dokumentu do více sloupců
Program Word umožňuje rozdělit dokument na logické celky, které jsou v něm terminologicky označeny jako Oddíly (Divisions). Pozor - nejde o kapitoly! Důvodem zavedení oddílů je kromě jiného umožnit odlišné nastavení jen některých částí dokumentu rozdílně od dokumentu jako celku. V těchto učebních textech jsou zmíněny dvě z vlastností, které lze nastavit jak pro celý dokument, tak pro každý jednotlivý oddíl.
První z vlastností je číslování stránek oddílu ve vztahu k číslování stránek dokumentu. Podrobně viz shora kapitolu Číslování stránek od určité stránky.
Druhou vlastností je právě uspořádání části dokumentu do více sloupců. Vícesloupcovou sazbu lze nastavit jak celému dokumentu, tak každému jednotlivému oddílu.
Vytvoření oddílu
Definovat část P dokumentu jakožto oddíl spočívá v umístění zalomení oddílu bezprostředně před část P a bezprostředně za část P. Předvedeno bude na části pod-kapitoly 2.1. O městě samotném už jako příprava na vícesloupcovou sazbu.
Textový kurzor se umístí před písmeno A na začátku textu druhého odstavce Archeologické nálezy ... Pak:
Rozložení stránky / Vzhled stránky /
Konce
a tam
Konce oddílů / Nepřetržitě
Program Word zobrazí v dokumentu informační značku Konec oddílu (průběžně).
V tomto okamžiku je dokument rozdělen logicky tak, že počínaje tímto místem až k další značce Konec oddílu (nebo až do konce dokumentu) je vytvořen nový oddíl. Má-li být nový oddíl jen částí dokumentu, je třeba analogicky vložit další značku Konec oddílu na místo, kde podle představ autora dokumentu má oddíl končit:
Textový kurzor se umístí za tečku na konci věty ... Stará Plzeň upadala. ve třetím odstavci. Pak:
Rozložení stránky / Vzhled stránky /
Konce
a tam opět
Konce oddílů / Nepřetržitě
Program Word zobrazí v dokumentu další informační značku Konec oddílu (průběžně). Tím je definován nový oddíl jako část dokumenty svým počátečním a koncovým zalomením.
Vícesloupcová sazba v oddílu
Textový kurzor se umístí kamkoliv do textu nově vytvořeného (případně již existujícího) oddílu. Pak:
Rozložení stránky / Vzhled stránky /
Sloupce / Další sloupce ...
Program Word zobrazí formulář Sloupce, kde se nastaví:
- Počet sloupců: Zadá se požadovaný počet sloupců.
- Čára mezi: Pokud je požadována, volba se zaškrtne.
- Šířka sloupců a mezer: Zadají se požadované velikosti.
- Sloupce stejně široké: Pokud je požadována, volba se zaškrtne. V případě této volby propočte program Word potřebné šířky sloupců a mezer jednotně. Stačí pak měnit např. šířku mezer mezi sloupci, Word adekvátně upravuje šířku sloupců samotných.
- Použít na: Volí se Na celý oddíl.
Po uzavření formuláře je požadavek promítnut do zobrazení dokumentu. Změna existujícího nastavení se docílí opakováním výše uvedeného postupu.
Obsahy a seznamy
Obsah
Cíl: Vložení obsahu, který bude odpovídat současnému stavu dokumentu, a jeho aktualizace
Vložení obsahu
Obsah je programem Word vložen vždy na místo, ve kterém je umístěn textový kurzor. I když v odborných publikacích bývá obsah umístěný na začátku dokumentu, zde pro přehlednost bude obsah umístěn na jeho závěr.
Nechť je tedy před následujícími činnostmi textový kurzor umístěn do druhého prázdného odstavce dokumentu odspodu. Pak:
Reference / Obsah / Obsah
Z nabídky se volí dole položka Vložit obsah .... V předloženém formuláři je možno kompletně změnit způsob generování obsahu a jeho vzhled. Pro účely tohoto článku postačují nabídnuté parametry, proto se jen stiskne tlačítko OK.
Obsah v obsahu
Bývá zvykem, že v obsahu je i obsah. Tím se rozumí, že jednou z položek obsahu je i řádek typu Obsah ...... str. 6. Protože v automaticky generovaném obsahu jsou zobrazeny texty odstavců formátovaných stylem Nadpis 1 atd., pak má-li se v obsahu objevit Obsah, musí tedy být někde v dokumentu odstavec tvořený jediným slovem Obsah a tento odstavec musí být formátovaný stylem Nadpis 1. Logické umístění takového odstavce je těsně nad obsahem.
Do prvního prázdného odstavce nad vygenerovaným obsahem se tedy vloží text Obsah.
Tomuto odstavci se přiřadí styl Nadpis 1. Tím se však zároveň tomuto nadpisu přiřadí číslo kapitoly. Nebývá však zvykem, že Obsah je číslovaná kapitola. Proto se označí odstavec obsahující slovo Obsah a
Domů / Odstavec / Číslování
načež se stiskne ("vymáčkne") přímo tlačítko
Číslování, nikoliv
jeho rozvíjecí šipka .
Aktualizace obsahu
Po jakékoliv změně dokumentu, mající dopad na obsah, NENÍ obsah změněn automaticky. Aktualizaci obsahu je nutno zajistit umístěním textového kurzoru kamkoliv do obsahu a pak:
Reference / Obsah / Aktualizovat tabulku
načež se z předloženého malého formuláře zvolí Aktualizovat celou tabulku.
Titulky a seznamy objektů
Cíl: Přiřazení titulku různým typům objektů a vytvoření seznamů různých typů objektů
Nedůsledností nebo přímo nekvalifikovaností - snad překladatelů? - je způsoben zmatek při označování různých pojmů stejným názvem. Vložené objekty by měly být opatřeny angl. caption (ve smyslu titulek, nadpis, legenda). To se skládá z angl. label (ve smyslu označení, štítek, etiketa, jmenovka), následuje pořadové číslo v rámci stejného label, a konečně angl. title (ve smyslu název, nadpis, záhlaví). Všechny tři pojmy jsou shodně česky překládány jako "Titulek" a nechává se na pronikavé inteligenci uživatele Wordu, aby z kontextu pochopil, o co jde. Jen v ojedinělých případech je "Label" překládán celkem rozumně jako "Popisek titulku".
Totální zmatenost překladatelů dokumentuje následující obrázek (za povšimnutí stojí už jen počet českých termínů "Titulek" použitých ve zcela odlišných kontextech), o - zatím záhadném - termínu Typ objektu ani nemluvě):
Titulky
Objekty vložené do dokumentu (obrázky, fotografie, tabulky a další typy objektů) by měly být opatřeny titulky (caption), které zahrnují jejich automatické číslování v rámci typu objektu. Typy objektů se rozlišují v tomto smyslu jen tehdy, jsou-li jednotlivé objekty opatřeny právě titulky (caption), přičemž typ objektu je dán použitým popiskem titulku (label). Opatřit objekt titulkem (caption) lze po označení (výběru) objektu pomocí
Reference / Titulky / Vložit titulek
čímž se zpřístupní formulář Titulek pro nastavení vlastností titulku (caption) - viz obrázek shora. V prvním textovém poli shora je zobrazen titulek (label) použitý pro označení tohoto typu objektu a pořadové číslo v rámci typu objektu. Tento formulář je jednotný pro titulky (caption) všech typů objektů. Předdefinovány jsou titulky (labels) pro objekty Tabulka, Obrázek a Rovnice. Autor dokumentu však může přidat své vlastní typy objektů (např. Foto, Mapa apod.) tím, že ve zobrazeném formuláři použije tlačítko Nový titulek (New label) - viz další odstavec.
Pro typ objektu zvolený rozvíjecím seznamem Titulek (Label) doplní autor dokumentu ve formuláři v prvním textovém poli požadovaný text titulku (title), a v rozvíjecím seznamu Umístění polohu titulku.(caption). Bývá zvykem, že titulky (captions) tabulek jsou nad tabulkami, titulky (captions) obrázků a dalších objektů pod nimi. Ve formuláři lze rovněž změnit způsob číslování.
Zavřením formuláře pomocí OK se do zvolené pozice titulek (caption) umístí. V celém dokumentu najednou lze vzhled, zarovnání a další atributy titulků (captions) měnit změnou stylu Titulek, který je implicitně přiřazen vkládaným titulkům. Autorův text titulku (title) lze později měnit přímo v titulku (caption).
Typy objektů a jejich definice
Po vytvoření nového dokumentu pro něj definuje program Word tři různé Labels ( = typy objektů, viz obrázek v předchozím odstavci). Jsou jimi Tabulka, Obrázek a Rovnice (takto jsou přeloženy do češtiny). Je samozřejmé, že autorovi dokumentu nemusí vyhovovat ani jejich počet, ani jejich znění. Mnozí autoři dávají v rozsáhlých publikacích přednost místo např. Obrázek 5 tvaru Obr. 5. Odborným publikacím pak chybí objekty typy Mapa, Schéma a další.
Pomocí formuláře Titulek (viz výše) lze tlačítkem Nový titulek ... vytvořit další a další Titulky = Labels = Typy objektů. Pro každý z nich pak lze vložit jejich automaticky generovaný seznam.
Zde si však autor dokumentu musí předem pečlivě rozvážit, jaká označení bude chtít ve svém dokumentu používat. Bylo by poněkud hloupé, kdyby pod některými obrázky bylo např. Obrázek 5 a pod jinými Obr. 5 - a přitom by šlo o zcela jiné obrázky. Skutečně pak by bylo možno nechat do dokumentu vložit jak Seznam obrázků, tak současně Seznam obr. s nutně jinými objekty.
Vložení seznamu
Pro jednotlivé typy objektů, které jsou dány jednotlivými použitými titulky (labels), lze požadovat vytvoření seznamu. Lze tedy logicky nechat vytvořit tolik seznamů, kolik je různých titulků (labels). Seznam bude umístěn vždy na pozici textového kurzoru. Nejdříve se tedy umístí textový kurzor na požadovanou pozici, a pak
Reference / Titulky / Vložit seznam obrázků
(pozor: vždy je v příkaze slovo "Obrázků", ať si přejeme vložit seznam jakéhokoliv typu objektu, nejen obrázku). Následně je zobrazen formulář Seznam obrázků. Zde se jako první krok zvolí příslušný popisek titulku (label), ve většině případů není zapotřebí další činnost. Po zavření formuláře je do aktuálního umístění textového kurzoru vygenerován seznam. Jednotlivým odstavcům tvořících seznam je standardně přidělen styl Seznam obrázků.
Aktualizace seznamu
Po jakékoliv změně dokumentu, mající dopad na nějaký vygenerovaný seznam, NENÍ seznam změněn automaticky. Aktualizaci seznamu je nutno zajistit umístěním textového kurzoru kamkoliv do obsahu a pak:
Reference / Obsah / Aktualizovat tabulku
načež se z předloženého malého formuláře zvolí Aktualizovat celou tabulku. Požadavek na aktualizaci obsahu lze zahájit také pravým kliknutím kamkoliv do seznamu a z následného kontextového menu zvolit Aktualizovat pole.
Změna seznamu
Je-li zapotřebí změnit nějaké vlastnosti seznamu, postupuje se následovně:
- Označí se kterýkoliv odstavec tvořící položku seznamu
- Pravým kliknutím do něj se z kontextového menu vybere položka Upravit pole ...
- Z následně předloženého formuláře Pole se vybere: Kategorie: Vše, Názvy polí: TOC (Table of Content).
- Stiskne se tlačítko Obsah ... v pravé části formuláře.
Tím se zobrazí formulář Seznam obrázků stejně jako při primárním vložení nového seznamu. V předchozím seznamu kroků je důležitý krok ad 1. Pokud se totiž provedou kroky 2. a 3. s neoznačeným odstavcem, předloží nevyzpytatelný Word nikoliv Seznam obrázků, ale Obsah.
Vložení seznamu tabulek do dokumentu
Ve cvičném dokumentu je v tomto okamžiku vytvořen obsah a jedna tabulka s titulkem. Je tedy možno nechat vytvořit seznam tabulek. Jeho logické umístění je hned před obsahem. Protože se seznamy vkládají na místo textového kurzoru, umístí se textový kurzor do prázdného odstavce před obsah, pak"
Reference / Titulky / Vložit seznam obrázků
V následném formuláři "Seznam obrázků" se jako "Popisek titulku" zvolí "Tabulka". Ve většině případů (především z důvodu zachování jednotného vzhledu seznamů) netřeba měnit nic dalšího.
Vložení seznamu tabulek do obsahu
Bývá zvykem, že v obsahu je i seznam tabulek. Tím se rozumí, že jednou z položek obsahu je i řádek typu Seznam tabulek ...... str. 6. Protože v automaticky generovaném obsahu jsou zobrazeny texty odstavců formátovaných stylem Nadpis 1 atd, pak má-li se v obsahu objevit Seznam tabulek, musí tedy být někde v dokumentu odstavec tvořený slovy Seznam tabulek, a tento odstavec musí být formátovaný stylem Nadpis 1. Logické umístění takového odstavce je těsně nad vygenerovaným seznamem tabulek.
Do prvního prázdného odstavce nad vloženým seznamem tabulek se tedy vloží text Seznam tabulek a tomuto odstavci se přiřadí styl Nadpis 1. Tím se však zároveň tomuto nadpisu přiřadí číslo kapitoly. Nebývá však zvykem, že Seznam tabulek je číslovaná kapitola. Proto se označí odstavec obsahující slova Seznam tabulek a
Domů / Odstavec / Číslování
načež se stiskne ("vymáčkne") přímo tlačítko
Číslování, nikoliv
jeho rozvíjecí šipka . Protože došlo
ke změně dokumentu mající vliv na obsah, musí následovat aktualizace obsahu
(viz výše).
Díl III: Základy použití tabulkových procesorů
Obecně o tabulkových procesorech
Data, jejich elementární typy a jejich fyzický způsob uložení v digitálním prostředí, to vše je obsahem první části těchto textů. V praxi ovšem existuje řada situací reálného světa, jejichž stav nelze popsat jedinou fyzickou hodnotou jediné fyzikální nebo jiné "jednoduché" veličiny. Tvrzení, že venku je 28°, je uprostřed zimního období příjemné. Samo o sobě je však nic neříkající. Kde (na severu Afriky, to je daleko), kdy (v srpnu, to je tam vlastně s touto teplotou chladno), kolik (stupňů Celsia či Fahrenheita?) - už jen tato tři upřesnění potřebují minimálně další tři datové hodnoty. A pro to místo (kde) dnes každý žáček obecné školy použije prvotně souřadnice GPS ze svého mobilku (což jsou v optimálním případě dvě fyzické číselné hodnoty).
Je tedy třeba se zabývat tím, jak jsou jednotlivá "jednoduchá" data "poskládána k sobě" tak, aby tvořila ucelený "informační celek" vypovídající o konkrétním stavu konkrétní sledované veličiny.
Dnes k nejčastěji používaným schématům patří databázová schémata nejrůznějších databázových systémů (naštěstí jich není moc). Na toto téma - zvláště tzv. relačních systémů - však studenti narazí v následujících semestrech.
Účelem těchto textů je popsat nejen způsob organizace uložení dat v tzv. tabulkových procesorech, ale i jejich specifika - a na to navazující problematiku případné vzájemné konverze dat tabulkových procesorů a relačních databází.
Pojem "Spreadsheet"
V anglickém originále jde o složeninu "Spread" a "Sheet". Jako "Sheet" se zde běžně chápe "List", "Arch". Pod pojmem "Spread" se rozumělo "Rozložení", "Roztažení" ve smyslu novinových nebo časopisových položek (textů nebo grafiky) pokrývající dvě strany, které se rozprostírají přes středový okraj a jsou považovány za jeden velký arch - viz např. [8].
Složený pojem "spread-sheet" (tedy doslova "Rozložený arch") znamenal formát, který sloužil k předkládání účetních knih - se sloupci pro kategorie výdajů, s řádky pro jednotlivé faktury a částkou pro každou platbu v té buňce, kde se řádek a sloupec částky protínají. Tento formát byl tradičně "rozložen" na protilehlé strany účetní knihy nebo na velké listy papíru (nazývané "analytický papír") v řádcích a sloupcích; listy byly přibližně dvojnásobně širší než obyčejný papír.
Rozvoj (tehdy ještě sálové) výpočetní techniky přinesl samozřejmě i rozvoj programového vybavení pro zpracování účetních a jim podobných úloh. Kolem roku 1970 byl vyvinut software pro zpracování dat uložených ve formě tabulek (tedy obdobně jako v databázích). To nové však spočívalo v tom, že v buňkách tabulek mohly být umístěny nejen jednoduché číselné a textové hodnoty, ale také vzorce.
Nástupem třídy osobních počítačů (Personal Computer) se přirozeně začaly množit požadavky na vývoj software pro zpracování analogicky koncipovaných tabulek jako u zmíněných sálových počítačů. Ke vzniku prvního takového úspěšného programu se uvádí následující historka [8]:
Dan Bricklin, student Harvard Business School, pozoroval svého univerzitního profesora vytvářejícího na tabuli tabulku dat a výsledků výpočtů. Když profesor zjistil chybu, musel opatrně vymazat a přepsat řadu po sobě jdoucích záznamů v tabulce. To přivedlo Bricklina k myšlence replikace tohoto procesu na počítači, přičemž tabule by byla použita pro zobrazení výsledků použitých vzorců. Spolu s kolegou Bobem Frankstonem implementoval Bricklin myšlenku do programu VisiCalc v roce 1979 na Apple II a v roce 1981 na IBM PC. VisiCalc se stal první aplikací, která přeměnila osobní počítač z hobby pro nadšence počítačů na obchodní nástroj.
VisiCalc byl zároveň prvním software, který kombinoval všechny základní funkce moderních tabulkových procesorů. Šlo např. o interaktivní uživatelské rozhraní WYSIWYG (What You See Is What You Get), automatické přepočítávání, stavové a vzorové řádky, kopírování s relativními a absolutními odkazy, výběry odkazovaných buněk aj.
Od té doby vznikla řada více či méně úspěšných aplikací určených pro zpracování dat zadaných ve formátu tabulek spolu se vzorci, které tato data používají a bezprostředně zobrazují výsledek - např. památný Lotus-123. Z těch, které se dosud vyvíjí a vznikají nové verze, lze uvést např.
- Microsoft Excel
- Corel Quattro Pro
- OpenOffice.org Calc
a další.
Ovšem Spread-sheet (nebo nyní častěji Spreadsheet) je pojem, na který je třeba dát v anglických textech pozor - a to např. i na Wikipedii. Jak bylo shora popsáno, původně měl pojem význam především účetní knihy. Rozšířením počítačových aplikací zpracovávajících účetní a podobná data, došlo k tomuto:
- Programy uvedeného typu čtou a ukládají data v nějakém svém interním formátu v souborech daného operačního systému.
- Pro běžného uživatele je každý takový soubor virtualizací skutečných "papírových" dat, tedy "spreadsheet".
- Proto se vžilo mezi uživatelskou obcí používání pojmu "spreadsheet" právě pro takový souborový model uložení dat.
- Ovšem uložená data je třeba zpracovat nějakým programem. Správně by se každý takový program měl nazývat přinejmenším "spreadsheet application".
- To se ale zřejmě mnohým zdá trochu dlouhé, proto pro každou takovou aplikaci použijí zkráceně rovněž "spreadsheet".
Pojem "spreadsheet" proto jednou může označovat aplikaci (tedy program), jednou soubor (tedy data). Záleží jen na obratnosti autora anglického textu, zda čtenář z kontextu pozná, o co vlastně jde.
V českých odborných textech je situace jednodušší:
Každý program zpracovávající spreadsheet může mít svůj vlastní formát datového souboru. Protože však jedním z nejrozšířenějších programů této třídy je MS Excel a logika jeho datových souborů simuluje data v sešitu, vžilo se označení "sešit" obecně pro soubory obsahující spreadsheet (= data). Korektně by se však mělo používat označení např. "sešit Excelu". I jiné programy této třídy a téměř každý aplikační software však dovede soubory typu "sešit Excelu" minimálně číst, proto zkrácené označení "sešit" není příliš na újmu obecnosti.
Závěrem: zvykli jsme si - a to je dodrženo v těchto učebních textech - na toto označení:
- Tabulkový procesor = spreadsheet jako program.
- Sešit = spreadsheet jako soubor.
Sešit
I český pojem "sešit" zavedený výše v sobě skrývá nebezpečí dvojznačnosti. Jednak se používá pro označení logické organizace dat, jednak pro fyzický soubor obsahující data právě s touto organizací. Z hlediska běžného uživatele však toto dvojí chápání splývá (zvláště vidí-li uživatel na obrazovce vizuální podobu logické organizace dat fyzicky uložených v souboru), a není tedy na závadu.
Sešit a používaná terminologie je pro názornost vysvětlována na tom zobrazení, které používá grafické rozhraní tabulkového procesoru Excel z edice MS Office 2010 (viz obrázek níže).
Sešit (workbook) se chápe jako jednotka uložení dat. Logicky lze nazírat jako na skutečný "papírový" sešit, který na začátku obsahuje několik vodorovně i svisle nalinkovaných listů (worksheets). Na každém listě je tedy osnovou vodorovných a svislých linek vytvořena soustava buněk (cells).
Poznámka: Velmi by to připomínalo čtverečkovaný papír, kdyby ty buňky byly skutečně čtverečky. Protože rozestup linek (jak svislých tak vodorovných) lze měnit, jsou buňky zobrazeny obecně jako obdélníky.
Vodorovnými linkami jsou vymezeny řádky buněk (rows), svislými linkami jsou vymezeny sloupce buněk (columns). Každý řádek je opatřen záhlavím řádku (row header), které obsahuje jedinečné číslo řádku (row number). Každý sloupec je opatřen záhlavím sloupce (column header), které obsahuje jedinečné písmenné označení sloupce (column name).
Na plochu takových listů (ne do jejich buněk) lze vkládat grafy, obrázky a další grafické objekty.
Poznámka 1: K označení sloupců se používá 26 písmen anglické abecedy (tj. bez diakritiky). Označení prvních 26 sloupců je A až Z. Označení dalších sloupců je tvořeno dvěma písmeny (AA, AB, AC až ZZ), následují označení třemi písmeny (AAA, AAB atd).
Poznámka 2: Počty řádků, sloupců a listů jsou dány implementací konkrétního tabulkového procesoru. Například v tabulkovém procesoru Excel 2010 je počet řádků 1 048 576 (=220) a počet sloupců 16 384 (=214) - poslední dostupný sloupec má tedy písmenné označení XFD. Počet listů je shora omezen pouze dostupnou pamětí, zdola je omezen na 1 list (sešit tedy musí obsahovat alespoň jeden list). Zatímco počet řádků a počet sloupců je pevně dán uvedenými hodnotami, listy lze ve stanoveném intervalu libovolně přidávat nebo ubírat.
Poznámka 3: Počet řádků a počet sloupců je pevně dán uvedenými hodnotami. Tabulkové procesory mají sice funkci "odstranění" několika řádků resp. několik sloupců. V tom případě se ale do listu zespodu (při odstranění řádků) resp. zprava (při odstranění sloupců) "nasunou" nové prázdné řádky resp. sloupce v počtu odstraněných.
Kromě listů s buňkami může sešit obsahovat listy, na každém z nichž je umístěn jeden (a vždy jen jeden) graf.
Každý list je jednoznačně pojmenován (worksheet name). V grafickém prostředí jsou listy znázorněny záložkami (tabs), v nichž jsou jména listů zobrazena. Jména listů jsou při vytvoření nového sešitu vytvořena tabulkovým procesorem, uživatel sešitu je může posléze měnit - musí ovšem zachovat jedinečnost jmen.
Každá buňka má především svou adresu (cell address) tvořenou písmenným označením sloupce následovaným číslem řádku (např. G12). Každá buňka má dále svůj obsah (cell content). Tento obsah může být prázdný (null - pozor, nikoliv nulový!), může to být hodnota (value) nějakého typu (value type), a konečně může být obsahem buňky i vzorec (formula). Obsah je v grafickém prostředí tabulkovým procesorem v buňce zobrazen, a to implicitním nebo zvoleným formátem (cell format).
Tabulkové procesory pracují většinou se třemi typy hodnot: s čísly (number), se znakovými řetězci (character string) a s logickými hodnotami (logical). Znakové řetězce se často zjednodušeně označují také jako text.
Buňky lze obsahem naplnit buď interaktivně v grafickém rozhraní tabulkového procesoru (např. z klávesnice), nebo importem z různých zdrojů. Pokud se zadává hodnota prostřednictvím grafického rozhraní přímo zápisem do buňky, zadává se do tzv. aktivní buňky aktivního listu. Adresa aktivní buňky je zobrazena v poli názvů, obsah aktivní buňky je zobrazen v poli vzorců. V buňce samotné je vždy zobrazena nějakým formátem hodnota obsahu: je-li obsahem např. číslo, je zobrazeno toto číslo; je-li však obsahem vzorec, je zobrazen "výsledek výpočtu".
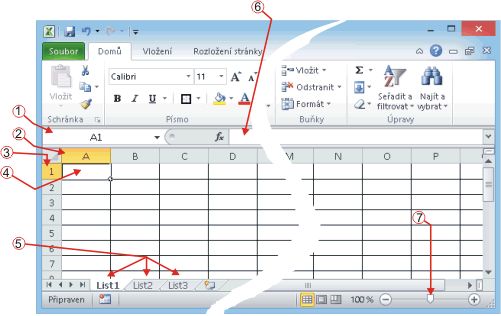 Sešit otevřený v prostředí programu Excel |
|
Konvence použité při popisu činností
V tomto textu jsou popisovány postupy v prostředí tabulkového procesoru Excel, edice Microsoft Office 2010. Tomu odpovídá i terminologie:
 K použité terminologii |
|
Tlačítko z bodu c. předchozího seznamu bude v textu zobrazováno symbolem
. Pro další ovládací prvky je použita
standardní terminologie resp. zobrazení (tlačítko, zaškrtávací pole
resp. , rozvíjecí seznam aj).
Pro vyznačení posloupnosti aktivací návazných ovládacích prvků je použit zápis
Hlavní karta / Skupina příkazů / Příkaz
Značí tedy zápis
Domů / Schránka / Vyjmout
(viz situaci na předchozím obrázku) požadavek na aktivaci hlavní karty Domů, tam vyhledání skupiny Schránka, a v ní použít příkaz Vyjmout.
Výjimkou je položka Soubor hlavního menu, kde na druhém místě je uvedena položka levého panelu a na třetím místě skupina parametrů.
Některé příkazy ve skupině mají pod ikonou nebo vedle textu ještě tlačítko
. Pokud to nevyplyne z kontextu,
bude výslovně řečeno, zda se má stisknout ikona nebo toto tlačítko pod (vedle)
ní.
Tento styl textu je ve článku použit pro pokyny čtenáři při práci se cvičným sešitem (viz níže), případně pro popis objektů a činností týkající se výhradně cvičného sešitu.
V celém následujícím textu se polohovacím zařízením rozumí klasická myš s implicitním nastavením tlačítek jako "levé" a "pravé". Pokud čtenář na svém zařízení používá jiné polohovací mechanismy (dotykovou obrazovky, touch-pad apod.) nebo opačného nastavení tlačítek, nechť pojmy myš, tlačítko, klik a další transformuje vzhledem ke svému zařízení resp. nastavení.
Cvičný sešit
Pro výuku je připraven cvičný sešit naplněný daty použitými při demonstraci jednotlivých kapitol. Studenti si jej před vlastní výukou stáhnou - např. do DOKUMENT-ů, na plochu ap. podle výukového prostředí. Jde o sešit s názvem CVICGMT.XLSX zde ke stažení.
Pokud se studenti hlásí jako uživatelé Student na učebně VŠB TU Ostrava, J-409, pak po přihlášení mají cvičný sešit v dokumentech uživatele Student (t.j. ve "svých" dokumentech) v adresáři EXCEL.
Typy dat
Poznámka: Tato kapitola používá termínů a znalostí kapitoly "Datové typy" v první části těchto učebních textů.
Ačkoliv v sešitu mohou být uloženy podprogramy a funkce uživatele využívající kompletní nabídky datových typů programovacího jazyka VBA (Visual Basic for Application), Excel sám využívá hodnotu (Value) buňky jako proměnnou typu Variant takto:
- Hodnoty jakéhokoliv číselného typu uloží jako typ Double (= racionální číslo s přesností max. 17 platných cifer).
- Text uloží jako hodnotu typu String (Null terminated character string - znakový řetězec ukončený nulovým bytem).
- Hodnoty PRAVDA a NEPRAVDA uloží jako hodnoty typu Boolean.
- Pokud je buňka s číselnou hodnotou formátována některým z datumových a (nebo) časových formátů, lze s takovou číselnou hodnotou pracovat jako s hodnotou datového typu Date a Excel skutečně pak nabízí volby pro "normální" číslo nesmyslné - např. číslo měsíce, týden v roce apod.
- Pokud je buňka s číselnou hodnotou formátována měnovým formátem (např. 10,60 Kč), lze s takovou číselnou hodnotou pracovat jako s hodnotou datového typu Currency.
Následně jsou stručně zmíněna jen některá specifika.
Číselný typ
Protože jde o hodnoty typu Double (racionální čísla ve dvojnásobné přesnosti), nelze do buňky vložit třebas Ludolfovo číslo na 35 desetinných míst (3.14159 26535 89793 23846 26433 83279 50288). Při pokusu o to Excel přijme a uloží jen 3.14159 26535 8979. Jak je zde vidět, shora zmíněných 17 (desítkových) cifer je skutečně maximum.
Na druhé straně lze bez problémů provádět číselné operace bez ohledu na formátování. Je-li číselná buňka formátována datumově (a uživatel vidí např. 30/12/2017), zřejmě nemá valný význam zjišťovat druhou odmocninu (=207,603). Jistě však má význam zjistit hodnotu o 20 menší (=10/12/2017).
Textový typ
Pro práci s textovými hodnotami disponuje Excel sice jen jedinou operací (obvykle nazývanou zřetězení, operátorem je znak & - jde o připojení druhého operandu za první), zato nabízí řadu funkcí pro práci s hodnotami typu Text. Buď některé parametry těchto funkcí nebo jejich výsledek je typu Text. Příkladem může být funkce ČÁST (vrací vnitřní část textu definovanou počáteční pozicí a počtem znaků), VELKÁ (vrací textový parametr, v němž jsou všechna písmena převedena na velká) a nejméně 22 dalších funkcí.
Logický typ
Velmi jednoduchý datový typ, z neznámého důvodu uživateli nepoužívaný, opomíjený ba až nenáviděný - kdykoliv uživatel vidí v buňce zobrazeno PRAVDA, raději její obsah co nejdříve smaže. Přitom hodnoty tohoto typu slouží k tak důležitým nástrojům, jako je řízení podmíněného výpočtu (viz funkce KDYŽ), nastavení nejrůznějších indikátorů apod. Trochu nepříjemné pro zkušenějšího pracovníka v oboru IT je to, že je zvyklý na logické operátory typu AND, OR, NOT a další. V Excelu je nutno tyto operace realizovat pomocí funkcí A, NEBO, NENÍ a dalších.
Datum resp. čas
Obecně viz shora Číselný typ. Je třeba mít neustále na paměti, že interně jde o hodnotu racionálního čísla; má tedy celou a necelou část. Celá část má význam pořadového čísla dne s počátkem (nulou) na časové ose dne 31/12/1899 (tj. den číslo 1 je 1/1/1900). Necelá část číselné hodnoty je proto zlomek dne tak, že 1,00 je jeden celý den = 24 hodin = 1 440 minut = 86 400 vteřin atd. Je-li tedy den č. 36 525 dnem 31/12/1999, pak hodnota 36 525,25 je čtvrtina tohoto dne, tj. 6:00 hodin ráno dne 31/12/1999.
Zobrazení datumu v buňce je v Excelu otázkou formátování číselné hodnoty. Pozor však: Excel neumí nulu a záporné hodnoty formátovat datumově!
Vkládání dat
Aktivní list, aktivní buňka
Sešit je komplexní dokument, sestávající z mnoho objektů. Při vkládání dat jsou ovlivňovanými objekty jednotlivé buňky, přesněji jejich hodnota event. vzorec (angl. Value resp. Formula). Nikoliv však na všech listech, ale pouze na těch, které určí uživatel - na tzv. aktivních listech (nejčastěji bývá při práci se sešitem zvolen jediný aktivní list). Aktivní list je indikován bílou záložkou na panelu záložek v levé dolní části pracovní plochy programu Excel. List aktivuje levý klik na jeho záložku. Lze určit více listů aktivních: další levý klik se stisknutou klávesou CTRL aktivuje další list. Na následujícím obrázku jsou aktivní tři listy: lCviceni, lTeplota a lVydaje.

Vkládat data - rozumí se "ručně", např. z klávesnice - lze v jednom okamžiku pouze do jedné buňky (tzv. aktivní buňky, např. C3). Tato buňka je však aktivní na všech aktivních listech. Jedním vložením lze zadat hodnoty více fyzickým buňkám právě jen v případě více aktivních listů - je-li aktivní buňkou např. C3, bude jedním vložením ovlivněn obsah buněk C3 na všech aktivních listech.
Vkládání a editace jednotlivých hodnot
Mechanismus vkládání dat z klávesnice do aktivní buňky je obecně znám, na úrovni těchto učebních textů zmíníme jen některá specifika.
Především se důrazně doporučuje ukončovat zadání každé hodnoty klávesou ENTER; teprve tím je zadaná hodnota rozpoznána a umístěna do buňky. V mnoha případech, zejména při zadávání vzorců, totiž Excel chápe použití např. myši nebo kurzorových kláves jako ukazování na operandy a výsledek rozhodně nebude odpovídat představě zadávajícího.
Po ukončení zadávání hodnoty program Excel upraví zobrazení zadané hodnoty s případným formátováním takto (předpokládá se zadání do buňky, která ještě nebyla explicitně ani implicitně formátována):
- Jestliže uživatelem zadaná posloupnost znaků tvoří přípustný zápis číselné hodnoty, bude uloženo číslo zarovnané na pravý okraj.
- Jestliže uživatelem zadaná posloupnost znaků tvoří přípustný zápis kalendářního datumu a (nebo) času, bude uloženo číslo formátované jako kalendářní datum resp. čas resp. datum a čas.
- Jestliže uživatelem zadaná posloupnost znaků je tvořena posloupností písmen PRAVDA nebo NEPRAVDA, bude uložena logická hodnota.
- Jestliže uživatelem zadaná posloupnost znaků začíná znakem rovnítko (=) a znaky za ním odpovídají syntaktickým pravidlům pro zápis vzorce (viz samostatná kapitola níže), bude uložen vzorec.
- V ostatních případech bude uložen text zarovnaný na levý okraj.
V některých případech požaduje zadavatel zapsat údaj, který by při běžném zápise byl rozpoznán jako číslo nebo datum nebo logická hodnota, nebo text začínající rovnítkem (tj. znaky za rovnítkem se nemají chápat jako vzorec). Může to být např. požadavek zápisu textu obsahující cifry v nějakém atypickém formátu apod. V tom případě se požadovaný text zapíše jako vzorec obsahující zápis textové konstanty tvořené požadovaným textem, např.
= "= moje sestra"
Rovněž editace (úprava) obsahu buňky by měla být obecně známa. Proto jen pro připomenutí: Požadovaná buňka se učiní aktivní, a pak
- klávesa F2 aktivuje mechanismus "edit on place" - editace na místě = přímo v buňce, nebo
- edituje se obsah buňky zobrazený v řádku vzorců (řádek nad nadpisy sloupců), nebo
- zapíše se kompletní nová hodnota.
Vkládání množiny dat
V těchto učebních textech (což není referenční manuál programu Excel !) jsou uvedeny postupy, které nejsou obecně známy, nebo u kterých je vhodné upozornit na některé jejich aspekty. Většinu popisovaných cílů lze dosáhnout i nástroji z hlavního menu resp. pásů karet, zde se však zabýváme pouze postupy zprostředkovanými myší (obecně polohovacím zařízením).
Po označení (výběru) buňky nebo spojité oblasti buněk je celý výběr orámován tučně a jeho plocha barevně odlišena - kromě buňky, kterou započal výběr; ta barevně odlišena nebude a stává se aktivní buňkou. Pravý dolní roh orámování je zvýrazněn a je důležitým ovládacím prvkem. Při práci s vybranou oblastí je orientací pro uživatele tvar kurzoru myši v různých situacích. Pro přehlednost je na následujících obrázcích označena (vybrána) jen jedna buňka (A1) a ta je tedy aktivní.
 Stahování směrem dolů za pravý dolní roh |
Nejčastější činností při popisované přípravě dat je použití pravého dolního rohu stylem drag-and-drop = uchopením myší a táhnutím. Na obrázku vlevo je naznačeno stažení směrem dolů, lze však táhnout libovolným ze čtyřech směrů. |
 Tvar kurzoru myši po přiblížení dolnímu okraji se stisknutou klávesou CTRL |
Rovněž okraj označené oblasti je ovládacím prvkem, který lze uchopit a táhnout. Výsledek tažení závisí na dalších okolnostech. Na obrázku vlevo je znázorněna ta okolnost, že při pohybu myši je na klávesnici nejprve stisknuta a držena klávesa CTRL. |
 Tvar kurzoru myši po přiblížení pravému dolnímu rohu bez stisknuté klávesy CTRL. |
Výsledek tažení za pravý dolní roh se významně liší podle stavu klávesy CTRL. |
 Tvar kurzoru myši po přiblížení pravému dolnímu rohu se stisknutou klávesou CTRL |
Protože výsledek tažení je určen stavem klávesy CTRL, je vhodné sledovat tvar kurzoru myši. |
Následují ukázky výsledků stažení výchozích dat. Pokud nebude výslovně uvedeno, stahuje se LEVÝM tlačítkem myši. V některých případech pozor na upozornění stažení PRAVÝM tlačítkem myši. Je nutno pozorně sledovat stahování BEZ stisknutého nebo SE stisknutým tlačítkem CTRL.
| P1 |
 Výchozí data |
 Stažení dolů bez stisknuté klávesy CTRL |
 Stažení dolů se stisknutou klávesou CTRL |
||
| P2 |
 Výchozí data |
 Stažení dolů bez stisknuté klávesy CTRL |
 Stažení dolů se stisknutou klávesou CTRL |
||
| P3 |
 Výchozí data |
 Stažení dolů bez stisknuté klávesy CTRL |
 Stažení dolů se stisknutou klávesou CTRL |
||
| P4 |
 Výchozí data |
 Stažení dolů bez stisknuté klávesy CTRL |
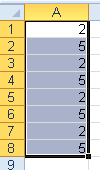 Stažení dolů se stisknutou klávesou CTRL |
||
| P5 |
 Výchozí data |
 Stažení dolů bez stisknuté klávesy CTRL |
 Stažení dolů se stisknutou klávesou CTRL |
Znovu je třeba upozornit na odlišné chování BEZ stisknuté klávesy CTRL a SE stisknutou klávesou CTRL.
Vkládání aritmetické posloupnosti
Příklady P1 a P4 ukazují vkládání aritmetické posloupnosti. V případě P1 jde o posloupnost s diferencí vždy 1 s prvním členem daným výchozí datovou hodnotou (zde v buňce A1 hodnota 1). V případě P4 jde o posloupnost s prvním členem daným první výchozí datovou hodnotou (zde v buňce A1 hodnota 2) a diferencí danou rozdílem druhé a první výchozí datové hodnoty (zde 5-2=3). Třetí člen (i=3) je tedy 2+(3-1)x3=8, sedmý člen (i=7) je roven 2+(7-1)x3=20.
Uvedený postup platí pro práci s myší BEZ stisknuté klávesy CTRL. Při stisknuté klávese CTRL jde o pouhou kopii dat.
Vkládání posloupnosti datumů resp. časů
Datum resp. čas je interně uloženo jako racionální číslo ve dvojnásobné přesnosti. Nástroje Excelu však jsou podle formátování číselné buňky schopny rozeznat specifika datumového údaje - např. číslo měsíce apod. Příklad P3 ukazuje totožný mechanismus při generování aritmetické posloupnosti jako v případech P1 a P4 - diference je rovna 1 (=1 den = 24 hodin), ovšem z naprosto neznámého důvodu je prohozeno chování klávesy CTRL při akci "stahování" - viz P1 a P4. Teprve v případě stisknuté klávesy CTRL jde o prostou kopii, jinak jde o vytvoření aritmetické posloupnosti.
Poznámka: Zda jde o datum, o čas nebo o datum a čas - to je dáno formátováním buňky s výchozími daty.
Vkládání posloupnosti textů s číselnou částí
Při vytváření aritmetické posloupnosti je Excel schopen rozpoznat zápis čísla i "odzadu" textového údaj - viz P2 (s Petrem) nebo P5 (s Janem). V těchto případech je chování s ohledem na klávesu CTRL stejné jako při datumových datech - a tedy "převrácené" oproti číselným datům.
Poznámka: Zápis čísla musí tvořit koncovou část textového údaje a musí to být celé číslo. Pro číselné hodnoty v textu typu "Petr 23 Pavel" se inkrementace neprovádí.
Použití lineární regrese
Silným nástrojem Excelu je možnost generování datových hodnot na základě stanovení lineární regrese výchozích dat. Jako základní příklad vezměme následující příklad P6. Výchozí data D (= A1 : A4) byla sestavena tak, aby zhruba odpovídala závislosti D=2xJ+3, kde J je pořadí hodnoty D (tedy J = 1, 2, 3, 4).
| P6 |
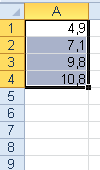 Výchozí data |
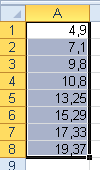 Stažení dolů bez stisknuté klávesy CTRL |
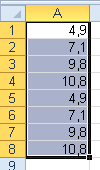 Stažení dolů se stisknutou klávesou CTRL |
Výchozími daty jsou v tomto případě hodnoty buněk A1 až A4. Nechť tvoří výběr (označení). Označme jejich počet n (v uvedeném příkladu tedy n=4). Jejich stažením SE stisknutou klávesou CTRL je generována jejich kopie. Ovšem jejich stažením BEZ klávesy CTRL o k řádků dolů (v uvedeném příkladu k=4) jsou vloženy hodnoty zjištěné následovně:
- Nejprve je provedena lineární regrese lineární funkcí (y = a . x + b) tak, že x je rovno pořadovému číslu řádku výběru (nikoliv číslu řádku listu!) a y je hodnota dat v tomto řádku.
- Lineární regrese se provádí metodou nejmenších čtverců odchylek, výsledkem jsou koeficienty a a b regresní přímky.
- Do následujících buněk (tedy v počtu k) je vložena hodnota y = a . x + b pro x od n+1 do n+k.
V uvedeném příkladu P6 má regresní přímka koeficienty a=2.04 a b=3.05, dopočtené hodnoty tedy vyhovují předpisu 2.04x+3.05 pro x=5, 6, 7 a 8.
Pomocí transformace dat lze řešit lineární regrese i některými nelineárními funkcemi, jak ukazuje následující příklad P7:
| P7 |
Výchozí data |
 Kontextové menu po stažení dolů bez stisknuté klávesy CTRL, avšak PRAVÝM tlačítkem myši |
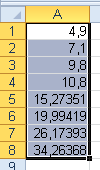 Doplnění po volbě Geometrický trend |
Výchozími daty jsou stejně jako v předchozím případě hodnoty buněk A1 až A4. Nechť tvoří výběr (označení). Stejně jako v předchozím případě označme jejich počet n (v uvedeném příkladu tedy n=4). Jejich stažením BEZ klávesy CTRL, avšak PRAVÝM tlačítkem myši o k řádků dolů (v uvedeném příkladu k=4) je nejprve zobrazeno kontextové menu. Volbou Geometrický trend jsou pak vloženy hodnoty zjištěné následovně:
- Nejprve je provedena lineární regrese funkcí y = b.ea.x tak, že x je rovno pořadovému číslu řádku výběru (nikoliv číslu řádku listu!) a y je hodnota dat v tomto řádku.
- Lineární regrese se provádí metodou nejmenších čtverců odchylek, výsledkem jsou koeficienty a a b regresní funkce.
- Do následujících buněk (tedy v počtu k) je vložena hodnota y = b . e a . x pro x od n+1 do n+k.
V uvedeném příkladu P6 má regresní křivka koeficienty a=0.269 a b=3.973, dopočtené hodnoty tedy vyhovují předpisu 3.973 . e 0.269 . x pro x=5, 6, 7 a 8.
Představu o popisovaném mechanismu dá následující obrázek:
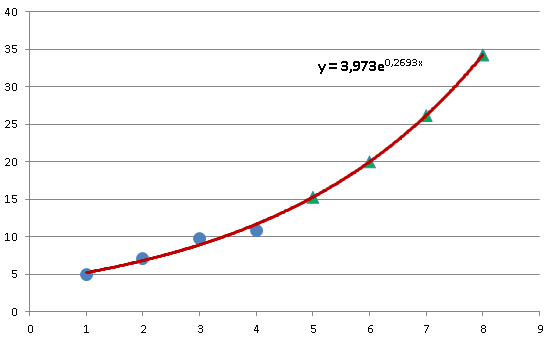 Dopočet geometrickým trendem |
|
Vkládání specielní řady datumů
Stahováním pravým tlačítkem myši má za následek zobrazení kontextového menu, jehož obsah je však různý podle typu stahovaných dat. Excel zde rozlišuje číselnou hodnotu formátovanou jako číslo a číselnou hodnotu formátovanou jako datum. Jedné z nabídek kontextového menu pro datumově formátované hodnoty lze využít pro řešení následující úlohy:
Vytvořte řadu datumů posledních dnů v měsíci.
Jako příklad P8 uveďme takovou řadu datumů, která obsahuje jak únor přestupného, tak únor nepřestupného roku:
| P8 |
 Výchozí data |
 Kontextové menu po stažení dolů bez stisknuté klávesy CTRL, avšak PRAVÝM tlačítkem myši |
 Doplnění po volbě Vyplnit měsíce |
Zatímco roky 2015 a 2017 nebyly přestupné, rok 2016 přestupný byl.
Když už je předložena tato úloha, můžeme na jejím výsledku demonstrovat řešení následující (obecné) úlohy:
Co to bylo za dny? Pondělky, čtvrtky ...
Pro kontrolu vytvořme pro následující ukázku P9 kopii datumových údajů. Po označení těchto nových dat zvolme
Domů / Číslo
a v následně předloženém formuláři zvolme Druh=Vlastní a vyplňme Typ: písmeny ddd.
| P9 |
 Příprava dat |
 Nastavení formátu druhému sloupci dat |
 Jiný z datumových formátů číselných hodnot |
Formátovací znak d se používá takto:
- d je symbol pro jedno - nebo dvouciferné číslo dne,
- dd je symbol pro vždy dvouciferné číslo dne,
- ddd je symbol pro zkratku dne,
- dddd je symbol pro plný název dne.
Bližší výklad o formátovacích symbolech a jejich použití (např. znaku m pro měsíce) však překračuje rozsah těchto učebních textů.
Vzorce, odkazy a názvy
Vzorce
Objektový model definovaný v knihovně Excel používá třídu Range (doslova přeloženo "Množina různých prvků stejného obecného typu", volně chápáno jako rozsah, výběr, oblast) jako reprezentanta buňky nebo skupiny buněk (angl. Cells). Běžný uživatel si pod tímto pojmem může zhruba představit jednu nebo více vybraných (označených) buněk. Každá buňka má řadu vlastností - způsob výplně, font použitý pro zobrazení obsahu apod.
Z hlediska diskutované problematiky patří mezi dvě nejdůležitější vlastnosti vzorec (angl. Formula) a hodnota (angl. Value). Tyto vlastnosti jsou navzájem svázány. Vztah mezi nimi by se dal vyjádřit takto: Vzorec (Formula) je předpis pro výpočet hodnoty (Value) nebo také naopak - hodnota je vypočítaný vzorec. V buňce je pak uložen vzorec, uživateli zobrazena jeho hodnota. Jde-li o aktivní buňku, pak je vzorec zobrazen nahoře nad záhlavími sloupců v řádku vzorců.
Pokud uživatel vloží do některé buňky "ručně" (z klávesnice) data některého z výše uvedených typů, budou vzorcem přímo tato data a pak Formula = Value. Jde-li o aktivní buňku, je v tomto případě obsah buňky i obsah řádku vzorců stejný.
Pokud uživatel vkládá do buňky vzorec, povinně musí být prvním znakem znak rovnítka (=). Za tímto znakem následuje tzv. výraz (angl. Expresion). Pro výraz platí striktní syntaktická pravidla, která musí být dodržena, jinak bude obsah buňky označen za chybný. Níže je uvedena definice výrazu. Výrazem je pak jedna z následujících konstrukcí (značí přitom symbol Ψ libovolný výraz, symbol ⊗ operační znaménko):
| Konstrukce | Popis | Příklad | |
| 1 | Konstanta | Zápis konkrétní datové hodnoty |
Číselná konstanta: 125 nebo -19,825 nebo 19/4/2017 Textová konstanta: "Ahoj" nebo "Jan Novák" Logická konstanta: NEPRAVDA nebo PRAVDA |
| 2 | Proměnná | Adresa buňky nebo její název (hodnotu buňky lze měnit, odtud proměnná) |
Adresa: B19 nebo GB$120 Název: SazbaDPH nebo Den_Nákupu |
| 3 | Operace |
⊗ Ψ (unární operace) Ψ ⊗ Ψ (binární operace) |
Unární operace: -A3 Binární operace: Den_Nákupu+14 |
| 4 | Volání funkce | Hodnota vrácená provedením knihovní funkce Excelu nebo vlastní naprogramované funkce. Značí-li F jméno nějaké funkce, pak volání funkce má obecně tvar F(Ψ ; Ψ ; ... ; Ψ) | ZAOKROUHLIT (A3 ; 3) |
| 5 | (Ψ) | Libovolný výraz uzavřený v kulatých závorkách | (A3 * sin (2 + Beta)) |
Uvedená definice pojmu Výraz je tzv. definicí rekurzivní: už při definici pojmu se používá definovaný pojem. Jde o poměrně komplexní způsob zavádění nových pojmů, který však může - setká-li se s ním čtenář poprvé - působit jisté problémy. Proto pro procvičení nechť čtenář rozmyslí, zda níže uvedená konstrukce je nebo není výrazem:
3 * A1 - 4 - C9 + sin (2 * G5 + 1)
Nápověda: má-li být uvedené výrazem, musí to být podle předchozí tabulky buď 1 nebo 2 nebo 3 nebo 4 nebo 5.
Pro unavené: stačí v prázdném listu do buněk A1, C9 a G5 vložit jedničky a do některé jiné vzorec
= 3 * A1 - 4 - C9 + sin (2 * G5 + 1)
Pokud po vložení tohoto vzorce bude zobrazena hodnota -1,85888 (obecně nebude zobrazena chyba), shora uvedená konstrukce je jistě výrazem. I pro unaveného čtenáře však zbývá otázka: proč?
Odkazy
Pomocí odkazů se ve výrazech (viz výše) odkazuje na operandy operací a parametry funkcí. Odkazy jsou v Excelu především proměnné, tj. adresy buněk nebo jejich názvy (o názvech viz následující podkapitola). Nejčastěji používanou adresou buňky je písmenné označení sloupce, za kterým následuje číslo řádku (tzv. notace A1), např. GB27. V Excelu lze odkazovat i na jednu nebo více oblastí (tedy jedním odkazem na více buněk), a to i nespojitých (angl. Areas). Např. odkaz B2:D5 odkazuje na obdélníkovou oblast dvanácti buněk, v jejímž levém horním rohu je buňka B2 a v pravém dolním rohu buňka D5.
V tomto odstavci je diskutován pouze odkaz na jedinou buňku. Důvodem je výklad chování Excelu při kopírování (nikoliv přesunu!) vzorců obsahující odkazy typu adresa buňky.
Uvažujme jednoduchou situaci: Pro několik nákupů zboží se známou cenou bez 21% DPH je třeba zjistit DPH i celkovou cenu s DPH. Připravme tedy nejprve první řádek tabulky. Součet ceny bez DPH a DPH v buňce E2 je bez problémů, tedy výpočet DPH v buňce D2:
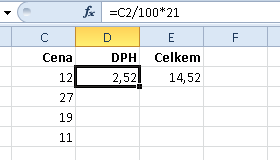
Kopírováním buňky D2 dolů pomocí jejího pravého dolního rohu budou doplněny vzorce pro výpočet DPH do dalších buněk:
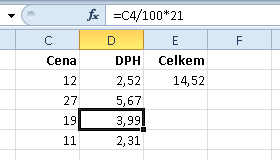
Za povšimnutí stojí důležitý mechanismus použitý při kopírování buňky D2 dolů: číslo řádku adresy C2 (tedy 2) ve vzorci bylo zvětšeno o tolik, kolik činil počet řádků, o kolik byl vzorec zkopírován. Např. při zkopírování vzorce o 2 řádky dolů na adresu D4 byla původní adresa C2 změněna o 2 řádky na C4.
Za takovou úpravu vzorců Excel velmi chválíme: pochopil, že když na druhém řádku počítáme DPH z ceny v C2, tak na třetím řádku budeme chtít počítat DPH z ceny v C3 atd.
Nyní však nastane problém: s novou vládou přijdou nové daně. DPH už nebude příjemných 21%, ale velmi nepříjemných 34% (poznámka: modelová situace není z domácího prostředí!). To ovšem znamená zásah do všech dříve vytvořených vzorců obsahujících hodnotu 21. Proto hned na začátku sazbu DPH raději umístíme do samostatné buňky (např. F2) a při změně sazby budeme měnit tuto jedinou buňku:
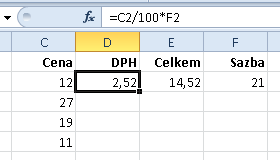
Kopírováním buňky D2 dolů pomocí jejího pravého dolního rohu budou doplněny vzorce pro výpočet DPH do dalších buněk, avšak s nenadálým výsledkem:
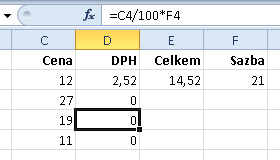
Příčinou je shora popsaný mechanismus použitý při kopírování buňky D2 dolů: číslo řádku adresy C2 (tedy 2) ve vzorci bylo zvětšeno o tolik, kolik činil počet řádků, o kolik byl vzorec zkopírován. Např. při zkopírování vzorce o 2 řádky dolů na adresu D4 byla původní adresa C2 změněna o 2 řádky na C4. Stejný mechanismus byl však uplatněn i u adresy F2: i ona byla změněna o 2 řádky na F4 (a tam není nic, což se chápe jako nula).
Ovšem za tuto druhou změnu už Excel nechválíme. Stojíme tedy před otázkou: jak dát Excelu na vědomí, že některá čísla řádků si přejeme zvětšovat, zatímco jiná ne?
Autoři Excelu (stejně jako autoři jiných tabulkových procesorů dávno před Excelem) to zajistili vložením znaku $ (dolar) před to číslo řádku, které si nepřejeme zvětšovat:
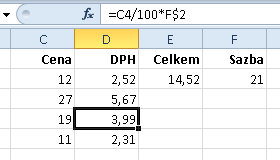
Uvedený příklad popisoval kopírování vzorce směrem dolů. Pokud by se kopíroval směrem nahoru, číslo řádku by se zmenšovalo. Při kopírování ve směru vodorovném by se analogicky měnilo písmeno sloupce (zvětšovalo by se nebo zmenšovalo). Pro zabránění této změny je třeba znak $ (dolar) umístit před písmeno sloupce.
Protože vzorec může být principiálně kopírován i vertikálně i horizontálně, existují 4 možnosti tvaru odkazu typu adresa buňky. Příklad: F11, F$11, $F11, $F$11. Znak $ (dolar) bývá na národních rozložení klávesnic obtížně přístupný, proto autoři Excelu pomáhají takto: umístěním textového kurzoru při zápisu vzorce na adresu (např. pro F11 nejlépe mezi F a 11) dochází postupným stiskem klávesy F4 k cyklické změně mezi uvedenými 4 možnostmi adres se znakem $ (dolar).
Obsahuje-li adresa ve vzorci znak $ (dolar), bývá nazývána adresou absolutní (protože odkazuje na absolutně stejné místo), kdežto adresy bez znaku $ (dolar) bývají nazývány adresy relativními (protože se mění o relativní posun).
Názvy
Pomocí adresy se lze odkazovat na jednu nebo více buněk. V případě odkazu na více buněk může jít např. o řadu nespojitých oblastí, navíc na jiných listech nebo v jiných sešitech. Adresa bývá v tom případě složitá a nepřehledná. V rozsáhlém sešitu s velkou řadou vzorců s odkazy se navíc ztrácí orientace v tom, co vlastně v buňce s konkrétní adresou je - zvláště když je vzorec např. na řádku 5000 a adresa odkazuje na buňku na řádku 2 a není tedy z řádku 5000 vidět.
Excel nabízí ve svých sešitech možnost zavádět pro jednoduché i složité adresy jejich pojmenování = názvy buněk nebo celých oblastí.
Přidělit vybrané (označené) buňce nebo oblasti název lze nejjednodušeji vepsáním tohoto názvu do pole názvů:
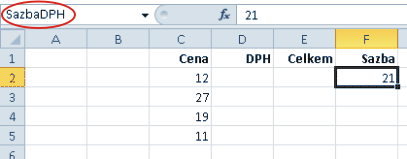
Důsledek se projeví hned při zápise vzorce, který obsahuje odkaz na pojmenovanou buňku:
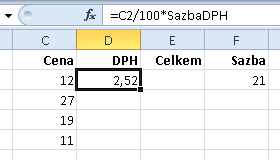
Ještě příjemnějším důsledkem je to, že při kopírování takového vzorce se autor sešitu nemusí příliš zabývat rozlišováním relativních a absolutních adres; "hned napoprvé" se povede vytvořit správné výpočty:
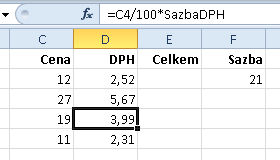
Je to dáno tím, že Excel při popsaném postupu daným názvem pojmenovává absolutní adresy, a to v celém sešitu - pojmenovaná adresa obsahuje nejen znaky $ (dolar) před písmenem sloupce i před číslem řádku, ale obsahuje i označení listu. Pokud se tedy uvede takový název ve vzorci kdekoliv v sešitu, vždy odkazuje do listu, kde se pojmenovaná oblast nachází.
Pokud by uvedený způsob adresace nevyhovoval, lze postupem
Vzorce / Definované názvy / Správce názvů
otevřít formulář Správce názvů, v němž ve spodní části v textovém poli Odkaz na se adresa příslušně upraví.
Důležitá poznámka: Každý název musí být v sešitu jedinečný (nemohou existovat dva stejné názvy). Dále: název musí mít tvar identifikátoru; musí to být posloupnost písmen a cifer začínající písmenem. Nesmí tedy obsahovat zvláště mezeru (!), může však obsahovat znak podtržítka (_), který se počítá mezi písmena.
Grafy
Tato kapitola popisuje práci s grafy především na obecné úrovni. Z konkrétních typů grafů se zabývá pouze sloupcovými, spojnicovými a XY bodovými, a to jen s ohledem na některá specifika jejich použití.
O grafech obecně
Terminologie
Graf, nazývaný také v jiných kontextech diagram, je znázornění především číselných dat, ve kterém jsou data reprezentována grafickými symboly. V prostředí tabulkových procesorů bývají těmito symboly obdélníkové nebo válcové sloupce, kruhové výseče, prstence, bubliny apod. Program Excel nabízí řadu grafů používajících různou symboliku s různou informační schopností. Jednotlivé nabízené typy grafů včetně ukázek jsou v použité verzi programu Excel následující:
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Ačkoliv se grafy podle typu různí, některé jejich vlastnosti jsou společné. Na často používaném sloupcovém grafu uveďme používanou terminologii.
 Graf vložený na plochu listu |
|
Ohraničení z bodu 1. předchozího obrázku je určeno ke změně rozměrů (úchytky v rozích a středech stran) nebo k přemístění (tažením za ohraničení uchopením kdekoliv jinde než ve zmíněných úchytkách). Vodorovná mřížka z bodu 10. předchozího obrázku má ekvivalent ve svislé mřížce, která však na obrázku znázorněna není.
Podle typu mají grafy nejčastěji dvě osy (sloupcový, spojnicový, pruhový, plošný, XY bodový, burzovní, bublinový), žádnou osu (prstencový, výsečový, paprskový) a podle podtypu grafu osy dvě nebo tři (povrchový). Osy jsou dvojího typu:
- Osa hodnot. Taková osa slouží pro číselná (kvantitativní) data. Hodnotou dat je určena jejich poloha na ose.
- Osa kategorií. Je použita pro kvalitativní data, přičemž konkrétní hodnota je dána textovým popiskem.
Na předchozím obrázku je jako ad 7. zobrazena osa X, která je v tomto případě osou kategorií (obsahuje tři kategorie), kdežto jako ad 8. je zobrazena osa Y jako osa hodnot v intervalu <0; 14.000>.
Důležitá poznámka: Popisky kategorií jsou vždy chápány textově, i kdyby měly mít jako zdroj čísla - v tom případě bude textový popisek tvořen potřebným počtem znaků, kterými jsou jednotlivé číslice. Toto může být kritický moment při vytváření grafů: chybná volba typu grafu může způsobit zcela mylnou představu o chování sledovaných veličin.
Umístění grafu
Graf může být v sešitu umístěn na "běžném" listu (v tom případě může být na takovém listu grafů více), nebo na samostatném "grafickém" listu (v tom případě je na takovém listu graf jediný). Umístění grafu lze po jeho vytvoření kdykoliv změnit: přesunout graf z běžného listu na nový grafický, nebo naopak odstranit grafický list a graf z něj přesunout na některý list s daty. Pokud je graf na některém listu s daty, pak mu lze kdykoliv změnit polohu, velikost i obsah. Pokud tvoří graf samostatný grafický list, lze mu měnit jen obsah.
Existující graf lze umístit jeho výběrem (označením, aktivací), pak:
Nástroje grafu / Návrh / Umístění / Přesunout graf
a v následně zobrazeném formuláři vybrat jednu z možností:
- Nový list:
- Objekt v:
V prvním případě se jako parametr zadá (jedinečné) jméno nově vytvářeného "grafického" listu, do kterého bude graf přemístěn. Ve druhém případě se vybere z rozvíjecí nabídky požadovaný (existující) list, do kterého bude graf přemístěn.
Vytvoření grafu
Graf lze vytvořit principiálně dvěma způsoby:
- Nejprve se v sešitu označí data, pak se vloží graf - ten již bude zobrazovat vybraná data.
- Nejprve se vloží prázdný graf - až posléze se mu přiřadí data, která mají být zobrazena.
První postup je jednodušší a rychlejší, druhý postup je obecnější. Níže jsou popsány oba postupy - směřují k vytvoření základu grafu "Výdaje v domácnosti" (viz bezprostředně předcházející obrázek).
Vytvoření grafu s již zobrazenými daty
Na listu lDomácnost se vybere (označí) oblast A1 : C4. Pak:
Vložení / Grafy / Sloupcový / Dvojrozměrný sloupcový / Skupinový sloupcový
Vytvoření prázdného grafu s následným určením dat
Na listu lDomácnost se aktivuje prázdná buňka nesousedící se žádnými daty (!). Pak:
Vložení / Grafy / Sloupcový / Dvojrozměrný sloupcový / Skupinový sloupcový
Na list bude vložen prázdný graf. Pak:
- Na listu lDomácnost se vybere (označí) oblast A1 : C4.
- Klávesovou kombinací CTRL / C se vybraná data zkopírují do schránky.
- Kliknutím do grafu se aktivuje (zatím prázdný) graf.
- Klávesovou kombinací CTRL / V se vybraná data umístí ze schránky do grafu.
Poznámka: Zkopírovat do schránky a vložit do grafu lze rovněž běžným způsobem pomocí kontextových menu (pravý klik).
Popsaný způsob je při tomto postupu zřejmě nejrychlejší. Obecnějším způsobem je volba položky Vybrat data ... z kontextového menu oblasti grafu (pravý klik na oblast grafu):
Kontextové menu oblasti
grafu
Následně je zobrazen formulář Vybrat zdroj dat. Zdrojová data ze zadají buď do textového pole Oblast dat grafu, nebo komplexněji tlačítkem Přidat v levém seznamu Položky legendy (řady).
Úprava (editace) grafu
Graf je poměrně komplexní objekt obsahující řadu komponent, kterými jsou zejména (viz také shora legendu u obrázku Graf vložený na plochu listu)
- oblast grafu,
- zobrazovaná oblast,
- datová řada,
- datový bod,
- vodorovná osa X,
- svislá osa Y,
- legenda,
- položka legendy,
- název grafu,
- název vodorovné osy X,
- název svislé osy Y,
- vodorovná mřížka,
- svislá mřížka.
Podle typu resp. podtypu grafu nemusí graf obsahovat všechny vyjmenované komponenty nebo naopak může obsahovat další, zde neuvedené součásti.
Upravovat (editovat) lze vybraný (aktivní, označený) graf - přesněji takový, ve kterém je vybrána (aktivní) některá jeho komponenta. Není-li graf vložený na plochu běžného listu aktivní, vybere se kliknutím kamkoliv do něj; tím se současně vybere jeho příslušná komponenta. Tvoří-li graf obsah samostatného "grafického" listu, aktivuje se výběrem tohoto listu. Další postup je společný oběma umístěním.
Vybrat (aktivovat) některou komponentu lze nejjednodušeji kliknutím na ni (levým tlačítkem myši). U některých "složených" komponent však pozor na posloupnost označování. Např. datová řada je množina datových bodů. Pro výběr datového bodu je zapotřebí nejprve vybrat příslušnou datovou řadu a teprve při vybrané datové řadě označit požadovaný datový bod. Analogicky např. při výběru jedné položky legendy, která je součásti legendy jako takové.
Po výběru některé komponenty grafu je hlavní menu programu Excel rozšířeno o tři položky z karet nástrojů grafu: Návrh, Rozložení a Formát. Zkušený uživatel dobře seznámený s terminologií (a zejména českými překlady) může pomocí těchto třech položek přidávat, odebírat a upravovat v podstatě kteroukoliv komponentu grafu.
Formát vybrané (aktivní) komponenty lze nastavit daleko jednodušeji než náhodným putováním po zmatených kartách. Pravý klik na vybranou komponentu XY totiž zobrazí kontextové menu této komponenty, kde poslední položka je vždy Formát komponenty XY. Její volbou je předložen formulář Formát XY pro nastavení všech vlastností této komponenty.
Pro milovníky zmíněných karet lze uvést i postup karty využívající: po výběru příslušné komponenty grafu aplikovat
Formát / Styly obrazců /
Po stisknutí tlačítka
je zobrazen stejný
formulář Formát XY jako postupem
popsaným výše.
Některé aspekty použití grafů
Sloupcové grafy
Sloupcové grafy jsou samy o sobě celkem fádní, patří však mezi hojně používané. Přesto je poměrně málo znám velmi jednoduchý způsob jejich zpestření:
 Běžný sloupcový graf |
 Sloupcový graf s obrázkem |
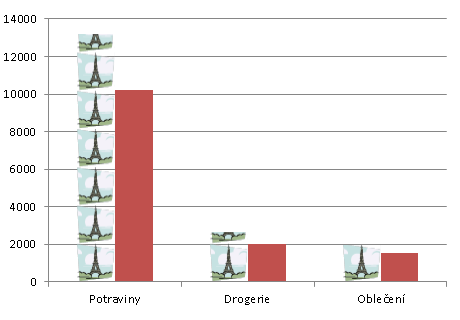 Sloupcový graf se skládaným obrázkem |
Výplň všech (nebo i jednotlivých) sloupců datové řady lze samozřejmě zajistit z formuláře pro formát datové řady nebo datového bodu klasickým (a tedy poměrně zdlouhavým) vyhledáním souboru. I to je jedno z omezení - výplň musí tvořit soubor některého obrázkového typu. Daleko jednodušší a obecnější je využití faktu, že substituci výplně označených (aktivních) datových bodů provede vložení obsahu schránky. Celý postup je pak následující:
- Do schránky se libovolným způsobem umístí obrázkový (nejlépe vektorový) zdroj, který má být výplní. Nemusí to být kompletní obrázek, ale např. výřez grafiky právě zpracovávané nějakým grafickým editorem (která navíc vůbec nemusí tvořit fyzický soubor).
- Vybere se (aktivuje) datová řada nebo jen některé datové body grafu.
- Klávesová zkratka CTRL/V provede substituci výplně.
Pokud je na závadu vertikální deformace, nastaví se ve formátu výplně datové řady nebo bodu při volbě Obrázková nebo texturová požadavek Skládat.
Grafy XY vs. grafy spojnicové
Jde o klasickou situaci: student finišující na své diplomové práci pojme úmysl vložit k textu své práce čárové zobrazení např. průběhu teploty v jistém dni. Data má připravená v tabulce:
|
HODINA |
TEPLOTA |
|
4 |
5 |
|
5 |
6 |
|
8 |
8 |
|
10 |
14 |
|
11 |
16 |
|
15 |
17 |
|
16 |
17 |
|
19 |
15 |
|
23 |
9 |
Podle zaběhnutého schématu data označí a začne vkládat graf. První nabídnutý jsou sloupce, to nechce, ovšem hned druhý nabídnutý jsou nějaké čáry - to je ono, šup tam s ním. Sice místo jedné čáry teploty uvidí ještě jednu čáru navíc, ale to DELETE spraví. Rovněž popis vodorovné osy X čísly od 1 do 9 mu dá zabrat, ale nakonec zvítězí:
Graf teploty spojnicový
Ovšem zvítězil-li student nad grafem, rozhodně nezvítězil nad oponenty své práce. Studentem předložený graf totiž deformuje představu o skutečném průběhu teploty ten den. Už jen pohled závěr dne: podle spojnicového grafu teplota viditelně strmě klesala - což je v kontrastu se skutečným průběhem, jak dokumentuje správně zvolený typ grafu - XY bodový:
Graf teploty XY bodový
Rovněž skutečný průběh teploty do osmé hodiny se diametrálně liší od průběhu znázorněném spojnicovým grafem.
Pochybení spočívá ve špatné volbě typu grafu. Spojnicový graf totiž používá vodorovnou osu X jako osu kategorií, zatímco graf XY používá vodorovnou osu X jako osu hodnot. Ve spojnicovém grafu jsou tedy hodiny 4, 5, 8 atd. chápány nikoliv jako hodnoty, ale jako kategorie (viz např. sloupcový graf) - proto jsou datové bodu od sebe vodorovně vzdáleny stejně, jsou ve stejném "rozestupu". Naopak graf XY umístí horizontálně datový bod podle hodnoty souřadnice X (zde hodiny).
Pozor na grafy funkcí
Grafy v Excelu znázorňující průběh funkce jsou založeny nikoliv na analytickém předpisu funkce, ale na množině dat tvaru [xi,{yi1,i2,...}]. Za "funkční čáru" je pak vydávána lomená (nebo "hladká") čára spojující jednotlivé body. Právě to může nevhodnou volbou bodů funkce zcela zkreslit představu o průběhu funkce.
Modelová funkce
Jako modelovou funkci pro ukázku zmíněné citlivosti na volbu
bodů funkce zvolme rovnici tlumeného harmonického oscilátoru
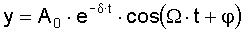 (1)
(1)
s parametry A0=3; d=0,03; W=3; j=0.
Poznámka: Čtenáři se nemusí děsit ani fyziky, ani matematiky. Stačí zavěsit kuličku s ouškem na špagátek, postrčit ji a koukat, jak se kýve, kýve, kýve ... A případně zapsat uvedený vztah jako vzorec v Excelu, to by mělo být obsahem učiva na střední škole.
Sledujme chování funkce (1) pro časový interval <0,100>.
V něm je skutečný průběh funkce následující:
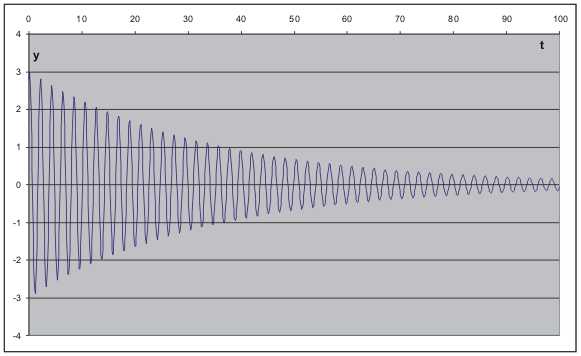
Obr. 1: Skutečný průběh funkce (1)
Dvě mylné představy
Pro znázornění průběhu funkce grafem XY je zapotřebí vytvořit
tabulku funkčních hodnot ("tabelovat funkci"). Nejprve měňme nezávisle proměnnou
(=čas) t s nějakým krokem; od 0 do 100 je daleko, nejdříve tedy člověka
napadne hodnota kroku 1. Dobrá tedy, tabulka funkčních hodnot je
| t | y |
|---|---|
| 0 | 3,00000 |
| 1 | -2,88220 |
| 2 | 2,71276 |
| 3 | -2,49813 |
| 4 | 2,24529 |
| ... | ... |
| 97 | -0,06404 |
| 98 | 0,04094 |
| 99 | -0,01835 |
| 100 | -0,00330 |
|
Tab. 1: Tabelace funkce s krokem 1 |
|
Graf XY takto tabelovaných hodnot je na následujícím obrázku:
Obr. 2: Graf hodnot z tabulky 1 - jen čáry
Je pravdou, že oko nematematika, nefyzika je potěšeno - graf je pohledný, harmonický, pěkně se vlní kolem osy X (hle, osciluje!) a dokonce čím dál míň, jako by ho tlumila únava. A zmíněný nematematik, nefyzik odchází s dobrým pocitem, že už ví, co to je tlumený harmonický oscilátor.
Nechť nyní jiný nematematik, nefyzik si nechá stejné hodnoty
zobrazit ne spojnicemi bez bodů, ale body bez spojnic:
Obr. 3: Graf hodnot z tabulky 1 - jen body
Ovšem tento druhý nematematik, nefyzik má zcela jinou představu než první. Především jeho oko vidí ne jednu, ale dvě čáry (mimochodem s celkem správným zobrazením, nikoliv však s danými parametry) s celkem pochopitelným průběhem - také jsou pohledné, harmonické, také se vlní a také tlumeně. Ale jeho mysl je zmatena; z hloubi své paměti doluje útržky informací spojených s oscilátorem - snad kulička (jedna), závaží na pružině (jedno) nebo tak něco. Kde se tedy vzalo to druhé a co to je? Tento druhý nematematik, nefyzik už s tak dobrým pocitem neodchází.
Zdroj problému
Zdroj problému spočívá ve volbě kroku. V uvedeném případě
byl zvolen krok roven 1; pro správnou - byť mnohdy hrubou - představu je zapotřebí
volit krok menší než čtvrtina intervalu mezi dvěma "sousedními" inflexními
body, což zde splněno není. Nastalo zde tedy toto: body tabelované s krokem
1 samozřejmě leží na funkční křivce, ale takto:
Obr. 4: Poloha tabelovaných bodů na křivce
Objekt třídy "Graf", který Excel používá, pak jen
mechanicky spojí úsečkou dva sousední body z množiny zadané jako "Zobrazovaná
data" (to mimochodem vyžaduje, aby data pro smysluplný XY graf byla seřazena
vzestupně dle X). Výsledkem je pak místo správného (modrého) průběhu nesprávný
(červený):
Obr. 5: Mylný průběh vzhledem ke skutečnému
Závěr
Odstranit problém se zdá jednoduché: stačí zjemnit krok. Je však zapotřebí si uvědomit, že Excel je široce používaný program právě zmíněnými ne-matematiky a ne-fyziky, kteří se občas ve svém oboru dostanou k nutnosti "podívat" se na funkční závislost. Tito uživatelé rozhodně neprovádí nejdřív analýzu funkce. A ruku na srdce, i mnohý matematik a fyzik při potřebě rychle získat představu o nějaké funkci se dlouho přípravou dat nezabývá.
Zde zmíněné jádro problému tuší dobře ti, kdo se pokusili jednou řadou vykreslit velmi jednoduchou čáru - hyperbolu y = 1 / x. V nule tabulková hodnota spočíst nejde, a místo aby graf zobrazil známé dvě křivky asymptoticky se přibližující ose Y, spojí poslední záporný a první kladný bod nesmyslnou úsečkou.
Je proto třeba mít uvedené skutečnosti na paměti a není-li průběh funkce z jejího předpisu obecně znám, udělat několik pokusů s různými kroky a nejlépe na různých intervalech.
Literatura a další výukové zdroje
[1] IMHOFF, M., WEBB, A., GOLDSCHMIDT, A.: Health Informatics. European Society of Intensive Care Medicine, 2001. p: 179-186.
[2] NELSON, R., STAGGERS, N.: Health informatics: an interprofessional approach. 2nd edition. St. Louis, Missouri: Elsevier, 2013. ISBN 9780323402316.
[3] Informatika. In: Wikipedie: Otevřená encyklopedie [online]. Wikimedia Foundation, 2003. [cit. 4.6.2017]. Dostupné z: https://cs.wikipedia.org/wiki/Informatika
[4] Endianness in: TANNENBAUM, A. S., AUSTIN, T.: Structured Computer Organization. 6th edition. Boston: Pearson, 2013. ISBN 9780132916523.
[5] International System of Units (SI): Prefixes for binary multiples. National Institute of Science and Technology. [cit. 4.10.2017]. Dostupné z: https://physics.nist.gov/cuu/Units/binary.html
[6] Institute of Electrical and Electronics Engineers: IEEE Standard 754-1985 for Binary Floating-Point Arithmetic, IEEE 1987. Reprinted in SIGPLAN 22, 2, 9-25.
[7] Rounding. In: Wikipedia: The free encyclopedia [online]. Wikimedia Foundation, 2003. [cit. 4.6.2017]. Dostupné z: https://en.wikipedia.org/wiki/Rounding
[8] Spreadsheet. In: Wikipedia: The free encyclopedia [online]. Wikimedia Foundation, 2003. [cit. 10.7.2017]. Dostupné z: https://en.wikipedia.org/wiki/Spreadsheet